 搜云库技术团队
搜云库技术团队
前言
在上一篇文章中分析了Spring是如何解析默认标签的,并封装为BeanDefinition注册到缓存中,这一篇就来看看对于像context这种自定义标签是如何解析的。同时我们常用的注解如:@Service、@Component、@Controller标注的类也是需要在xml中配置
正文
自定义标签解析原理
在上一篇分析默认标签解析时看到过这个类DefaultBeanDefinitionDocumentReader的方法parseBeanDefinitions:
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
//默认标签解析
parseDefaultElement(ele, delegate);
}
else {
//自定义标签解析
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
现在我们就来看看parseCustomElement这个方法,但在点进去之前不妨想想自定义标签解析应该怎么做。
public BeanDefinition parseCustomElement(Element ele, @Nullable BeanDefinition containingBd) {
String namespaceUri = getNamespaceURI(ele);
if (namespaceUri == null) {
return null;
}
NamespaceHandler handler = this.readerContext.getNamespaceHandlerResolver().resolve(namespaceUri);
if (handler == null) {
error("Unable to locate Spring NamespaceHandler for XML schema namespace [" + namespaceUri + "]", ele);
return null;
}
return handler.parse(ele, new ParserContext(this.readerContext, this, containingBd));
}
可以看到和默认标签解析是一样的,只不过由decorate方法改为了parse方法,但具体是如何解析的呢?这里我就以component-scan标签的解析为例,看看注解是如何解析为BeanDefinition对象的。
注解解析原理
进入到parse方法中,首先会进入NamespaceHandlerSupport类中:
public BeanDefinition parse(Element element, ParserContext parserContext) {
BeanDefinitionParser parser = findParserForElement(element, parserContext);
return (parser != null ? parser.parse(element, parserContext) : null);
}
首先通过findParserForElement方法去找到对应的解析器,然后委托给解析器ComponentScanBeanDefinitionParser解析。在往下看之前,我们先想一想,如果是我们自己要去实现这个注解解析过程会怎么做。是不是应该首先通过配置的basePackage属性,去扫描该路径下所有的class文件,然后判断class文件是否符合条件,即是否标注了@Service、@Component、@Controller等注解,如果有,则封装为BeanDefinition对象并注册到容器中去?下面就来验证我们的猜想:
public BeanDefinition parse(Element element, ParserContext parserContext) {
String basePackage = element.getAttribute(BASE_PACKAGE_ATTRIBUTE);
basePackage = parserContext.getReaderContext().getEnvironment().resolvePlaceholders(basePackage);
String[] basePackages = StringUtils.tokenizeToStringArray(basePackage,
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
// Actually scan for bean definitions and register them.
// 创造ClassPathBeanDefinitionScanner对象,用来扫描basePackage包下符合条件(默认是@Component标注的类)的类,
// 并创建BeanDefinition类注册到缓存中
ClassPathBeanDefinitionScanner scanner = configureScanner(parserContext, element);
Set<BeanDefinitionHolder> beanDefinitions = scanner.doScan(basePackages);
registerComponents(parserContext.getReaderContext(), beanDefinitions, element);
return null;
}
可以看到流程和我们猜想的基本一致,首先创建了一个扫描器ClassPathBeanDefinitionScanner对象,然后通过这个扫描器去扫描classpath下的文件并注册,最后调用了registerComponents方法,这个方法的作用稍后来讲,我们先来看看扫描器是如何创建的:
protected ClassPathBeanDefinitionScanner configureScanner(ParserContext parserContext, Element element) {
boolean useDefaultFilters = true;
if (element.hasAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE)) {
useDefaultFilters = Boolean.valueOf(element.getAttribute(USE_DEFAULT_FILTERS_ATTRIBUTE));
}
// Delegate bean definition registration to scanner class.
ClassPathBeanDefinitionScanner scanner = createScanner(parserContext.getReaderContext(), useDefaultFilters);
scanner.setBeanDefinitionDefaults(parserContext.getDelegate().getBeanDefinitionDefaults());
scanner.setAutowireCandidatePatterns(parserContext.getDelegate().getAutowireCandidatePatterns());
if (element.hasAttribute(RESOURCE_PATTERN_ATTRIBUTE)) {
scanner.setResourcePattern(element.getAttribute(RESOURCE_PATTERN_ATTRIBUTE));
}
...
parseTypeFilters(element, scanner, parserContext);
return scanner;
}
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
if (useDefaultFilters) {
registerDefaultFilters();
}
setEnvironment(environment);
setResourceLoader(resourceLoader);
}
protected void registerDefaultFilters() {
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
protected void parseTypeFilters(Element element, ClassPathBeanDefinitionScanner scanner, ParserContext parserContext) {
// Parse exclude and include filter elements.
ClassLoader classLoader = scanner.getResourceLoader().getClassLoader();
// 将component-scan的子标签include-filter和exclude-filter添加到scanner中
NodeList nodeList = element.getChildNodes();
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node.getNodeType() == Node.ELEMENT_NODE) {
String localName = parserContext.getDelegate().getLocalName(node);
try {
if (INCLUDE_FILTER_ELEMENT.equals(localName)) {
TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);
scanner.addIncludeFilter(typeFilter);
}
else if (EXCLUDE_FILTER_ELEMENT.equals(localName)) {
TypeFilter typeFilter = createTypeFilter((Element) node, classLoader, parserContext);
scanner.addExcludeFilter(typeFilter);
}
}
catch (ClassNotFoundException ex) {
parserContext.getReaderContext().warning(
"Ignoring non-present type filter class: " + ex, parserContext.extractSource(element));
}
catch (Exception ex) {
parserContext.getReaderContext().error(
ex.getMessage(), parserContext.extractSource(element), ex.getCause());
}
}
}
}
上面不重要的方法我已经删掉了,首先获取use-default-filters属性,传入到ClassPathBeanDefinitionScanner构造器中判断是否使用默认的过滤器,如果是就调用registerDefaultFilters方法将@Component注解过滤器添加到includeFilters属性中;创建后紧接着调用了parseTypeFilters方法去解析include-filter和exclude-filter子标签,并分别添加到includeFilters和excludeFilters标签中(关于这两个标签的作用这里不再赘述),所以这一步就是创建包含过滤器的class扫描器,接着就可以调用scan方法完成扫描注册了(如果我们要自定义注解是不是也可以这样实现呢?)。
protected Set<BeanDefinitionHolder> doScan(String... basePackages) {
Assert.notEmpty(basePackages, "At least one base package must be specified");
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) {
// 这里就是实际扫描符合条件的类并封装为ScannedGenericBeanDefinition对象
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// 接着在每个单独解析未解析的信息并注册到缓存中
for (BeanDefinition candidate : candidates) {
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// 解析@Lazy、@Primary、@DependsOn等注解
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
if (checkCandidate(beanName, candidate)) {
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
definitionHolder =
AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
beanDefinitions.add(definitionHolder);
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
return beanDefinitions;
}
public Set<BeanDefinition> findCandidateComponents(String basePackage) {
if (this.componentsIndex != null && indexSupportsIncludeFilters()) {
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
// 主要看这,扫描所有符合条件的class文件并封装为ScannedGenericBeanDefinition
return scanCandidateComponents(basePackage);
}
}
private Set<BeanDefinition> scanCandidateComponents(String basePackage) {
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// 获取class文件并加载为Resource
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
for (Resource resource : resources) {
if (traceEnabled) {
logger.trace("Scanning " + resource);
}
if (resource.isReadable()) {
try {
// 获取SimpleMetadataReader对象,该对象持有AnnotationMetadataReadingVisitor对象
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
if (isCandidateComponent(metadataReader)) {
// 将AnnotationMetadataReadingVisitor对象设置到ScannedGenericBeanDefinition中
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
sbd.setResource(resource);
sbd.setSource(resource);
if (isCandidateComponent(sbd)) {
if (debugEnabled) {
logger.debug("Identified candidate component class: " + resource);
}
candidates.add(sbd);
}
}
}
}
}
}
return candidates;
}
这个方法实现很复杂,首先是扫描找到符合条件的类并封装成BeanDefinition对象,接着去设置该对象是否可作为根据类型自动装配的标记,然后解析@Lazy、@Primary、@DependsOn等注解,最后才将其注册到容器中。
需要注意的是和xml解析不同的是在扫描过程中,创建的是ScannedGenericBeanDefinition对象:
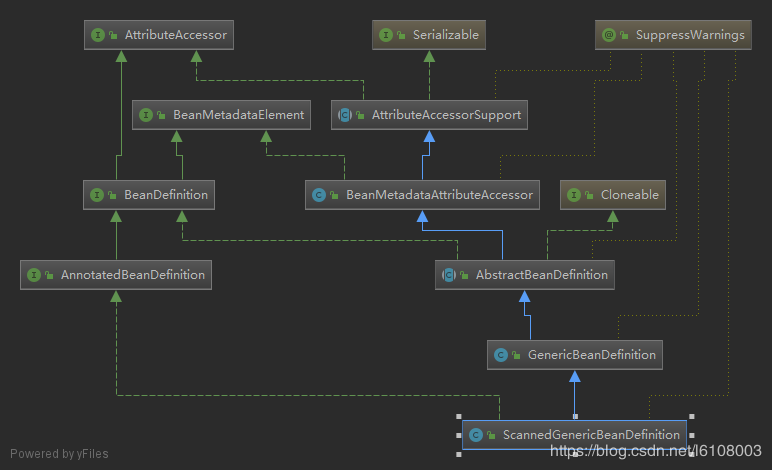
该类是GenericBeanDefinition对象的子类,并持有了AnnotationMetadata对象的引用,进入下面这行代码:
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
我们可以发现AnnotationMetadata实际上是AnnotationMetadataReadingVisitor对象: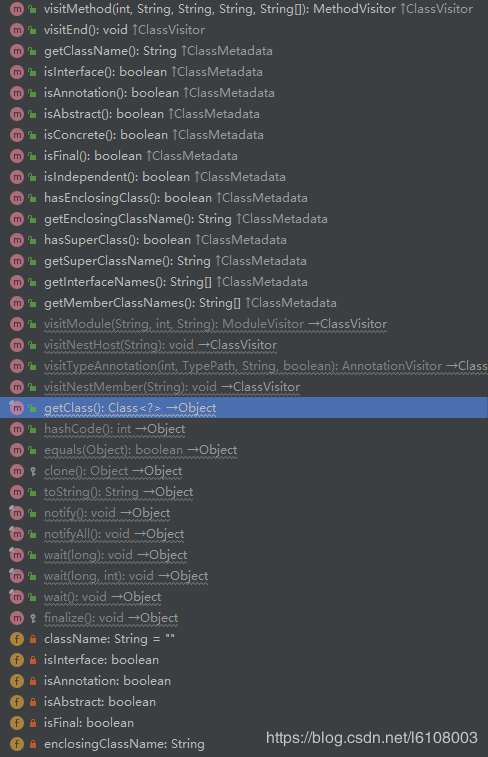
从上图中我们可以看到该对象具有很多属性,基本上包含了我们类的所有信息,所以后面在对象实例化时需要的信息都是来自于这里。
以上就是Spring注解的扫描解析过程,现在还剩一个方法registerComponents,它是做什么的呢?
protected void registerComponents(
XmlReaderContext readerContext, Set<BeanDefinitionHolder> beanDefinitions, Element element) {
Object source = readerContext.extractSource(element);
CompositeComponentDefinition compositeDef = new CompositeComponentDefinition(element.getTagName(), source);
for (BeanDefinitionHolder beanDefHolder : beanDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(beanDefHolder));
}
// Register annotation config processors, if necessary.
boolean annotationConfig = true;
if (element.hasAttribute(ANNOTATION_CONFIG_ATTRIBUTE)) {
annotationConfig = Boolean.valueOf(element.getAttribute(ANNOTATION_CONFIG_ATTRIBUTE));
}
if (annotationConfig) {
Set<BeanDefinitionHolder> processorDefinitions =
AnnotationConfigUtils.registerAnnotationConfigProcessors(readerContext.getRegistry(), source);
for (BeanDefinitionHolder processorDefinition : processorDefinitions) {
compositeDef.addNestedComponent(new BeanComponentDefinition(processorDefinition));
}
}
readerContext.fireComponentRegistered(compositeDef);
}
在该标签中有一个属性annotation-config,该属性的作用是,当配置为true时,才会去注册一个个BeanPostProcessor类,这个类非常重要,比如:ConfigurationClassPostProcessor支持@Configuration注解,AutowiredAnnotationBeanPostProcessor支持@Autowired注解,CommonAnnotationBeanPostProcessor支持@Resource、@PostConstruct、@PreDestroy等注解。这里只是简单提提,详细分析留待后篇。
至此,自定义标签和注解的解析原理就分析完了,下面就看看如何定义我们自己的标签。
定义我们自己的标签
通过上面的分析,我相信对于定义自己的标签流程应该大致清楚了,如下:
1、 首先设计一个标签并定义其NamespaceHandler类,让它继承NamespaceHandlerSupport类;
2、 其次定义标签对应的解析器,并实现parse方法,在parse方法中解析我们的标签,将其封装为BeanDefinition对象并注册到容器中;
3、 最后在classpath/META-INF文件夹下创建一个spring.handler文件,并定义标签的命名空间和NamespaceHandler的映射关系。
这就是我们从之前的源码分析中理解到的,但这里实际还忽略了一个步骤,这也是之前分析时没讲到的,你能想到是什么么?我们设计的标签需不需要一个规范?不可能让其他人随便写,否则怎么识别呢?因此需要一个规范约束。同样,在Spring的META-INF文件夹下都会有一个spring.schemas文件,该文件和spring.handler文件一样,定义了约束文件和约束命名空间的映射关系,下面就是context的spring.schemas文件部分内容:
http\://www.springframework.org/schema/context/spring-context-2.5.xsd=org/springframework/context/config/spring-context.xsd
......
http\://www.springframework.org/schema/cache/spring-cache.xsd=org/springframework/cache/config/spring-cache.xsd
但是这个文件是在什么时候被读取的呢?是不是应该在解析xml之前就把规范设置好?实际上就是在调用XmlBeanDefinitionReader的doLoadDocument方法时读取的该文件:
protected Document doLoadDocument(InputSource inputSource, Resource resource) throws Exception {
return this.documentLoader.loadDocument(inputSource, getEntityResolver(), this.errorHandler,
getValidationModeForResource(resource), isNamespaceAware());
}
protected EntityResolver getEntityResolver() {
if (this.entityResolver == null) {
// Determine default EntityResolver to use.
ResourceLoader resourceLoader = getResourceLoader();
if (resourceLoader != null) {
this.entityResolver = new ResourceEntityResolver(resourceLoader);
}
else {
this.entityResolver = new DelegatingEntityResolver(getBeanClassLoader());
}
}
return this.entityResolver;
}
public DelegatingEntityResolver(@Nullable ClassLoader classLoader) {
this.dtdResolver = new BeansDtdResolver();
this.schemaResolver = new PluggableSchemaResolver(classLoader);
}
public static final String DEFAULT_SCHEMA_MAPPINGS_LOCATION = "META-INF/spring.schemas";
public PluggableSchemaResolver(@Nullable ClassLoader classLoader) {
this.classLoader = classLoader;
this.schemaMappingsLocation = DEFAULT_SCHEMA_MAPPINGS_LOCATION;
}
总结
通过两篇文章完成了对Spring XML标签和注解解析的源码分析,整体流程多看几遍还是不复杂,关键是要学习到其中的设计思想:装饰、模板、委托、SPI;掌握其中我们可以使用到的扩展点:xml解析前后扩展、自定义标签扩展、自定义注解扩展(本篇没有讲解,可以思考一下);深刻理解BeanDefinition对象,可以看到所有标签和注解类都会封装为该对象,因此接下来对象实例化都是根据该对象进行的。

