 搜云库技术团队
搜云库技术团队
一、背景
在视频会议中接入SIP客户端时,需要在MCU服务器里完成视频混屏。而owt-server是Intel开源的基于WebRTC的流媒体服务。其中的MCU实现了VideoMixer功能,对我们完成视频混屏具有很好的参考意义。
这篇文章主要对owt-server里VideoMixer的Pipeline流程和线程模型做一次梳理。
owt-server项目地址Github。代码fork from2019/10/24的版本,commit地址 61a95d68
二、概览
下图是owt-server混屏模块的类图,接下来会基于这个图来展开Pipeline和线程模型。
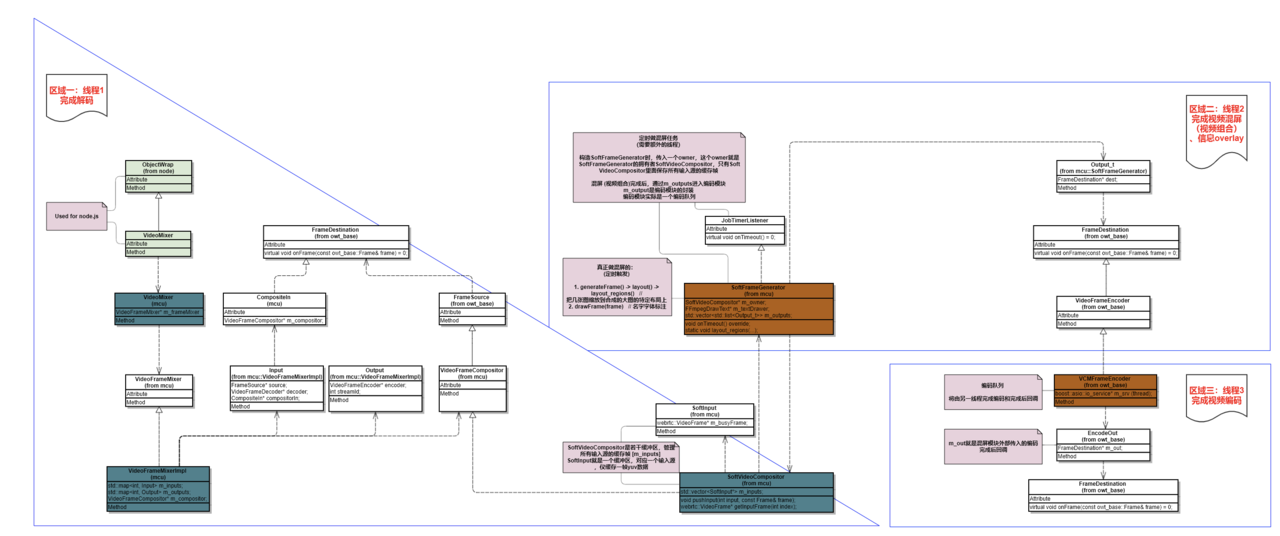
简单介绍:
这里只画出混屏模块类间关系,没有画出数据流向(数据流向参考下文的
Pipeline流程)。整体从左向右看,分为三个区域。
- 区域一:完成视频解码;
- 区域二:完成视频组合(Compose)、overlay昵称/概览等;
- 区域三:完成视频编码、完成后回调;
三、Pipeline流程
(1)、Pipeline流程
FrameSource --> decode --> compositorIn(Buffer) --> compose/overlay --> encode(queue) --> Destination
(2)、如何建立Pipeline
为方便阅读和理解,下文出现的代码,除了
类名和方法名外,其余可能是省略不重要环节的伪代码。
1. 给VideoMixer配置Input和Output
- 每一次
addInput,都会带上一个视频数据来源FrameSource;每一次addOutput都会带上一个视频混屏(整个Pipeline)完成后回调dest; - 设置每一个
Input时,会把Input与一个解码器、解码完成后的缓冲区(compositorIn)绑定;设置每一个Output时,会把Output与一个编码器绑定; - 在配置
Input和Output的过程中,通过设置当前功能模块(比如encode、compose等)完成后的下一个功能模块回调(dest),完成整个Pipeline顺序关系的建立;
2. FrameSource –> decode –> compositorIn
inline bool VideoFrameMixerImpl::addInput(owt_base::FrameSource* source ...)
{
...
owt_base::VideoFrameDecoder* decoder = new owt_base::FFmpegFrameDecoder();
CompositeIn* compositorIn = new CompositeIn(...);
source->addVideoDestination(decoder); // source -> decode
decoder->addVideoDestination(compositorIn); // decode -> compositorIn
...
}
3. compositorIn(Buffer) –> encode(queue)
上面Pipeline流程中,compositorIn后是compose/overlay,在从缓冲区(compositorIn)在所有Input中各取一帧后完成混屏(compose)是在一个类中,所以不需要设置回调。在完成混屏后才需要一个dest(encode)。
inline bool VideoFrameMixerImpl::addOutput(int fps, int bitrate, owt_base::FrameDestination* dest ...)
{
...
owt_base::VideoFrameEncoder* encoder = new owt_base::VCMFrameEncoder(format, profile, m_useSimulcast);
m_compositor->addOutput(fps, bitrate, encoder); // compositorIn -> encode, encoder就是compositorIn的dest
...
}
4. encode(queue) –> Destination
还是在上面一个函数:
inline bool VideoFrameMixerImpl::addOutput(int fps, int bitrate, owt_base::FrameDestination* dest ...)
{
...
owt_base::VideoFrameEncoder* encoder = new owt_base::VCMFrameEncoder(format, profile, m_useSimulcast);
encoder->generateStream(fps, bitrate, dest); // encode -> dest
...
}
在owt_base::VCMFrameEncoder::generateStream内部,会把使用一个EncodeOut的类型把dest与其他一些信息绑定。在VCMFrameEncoder完成编码后,通过这个EncodeOut结构找到dest,从而把混屏完成后的码流抛到混屏模块外部。
四、线程模型
整个Pipeline涉及到3个线程,分别是:
1、 通过FrameSource把视频码流送入混屏模块的外部线程。
* 这个线程会完成视频码流的解码,解码后的YUV保存在`SoftVideoCompositor::m_inputs`中;
* m\_inputs是所有Input的帧缓冲区,但是每一个Input的缓冲区长度只有1,就是只能缓冲一个帧,如果这个帧没来得及混屏,后面解码的帧会覆盖这个帧;
2、 在SoftFrameGenerator中定时做混屏(compose)的线程。
* 混屏完成后,把YUV放到`VCMFrameEncoder`中的编码队列,由下一个线程顺序完成编码;
3、 在VCMFrameEncoder中执行编码的线程。
* 编码完成后由该线程返回`EncodedFrame`给上层。
五、对于owt-server线程模型的思考
上面线程模型中的三个线程:
- 第一个是外部的,完成解码。解码必须立即完成,不能缓冲。缓冲Buffer不能太长,否则缓冲的码流就没有意义了;Buffer也不能太短,太短就有被覆盖或丢弃的风险。一旦码流因为缓冲被部分丢弃,会导致后面的码流解码出问题导致花屏。所以由外部线程完成解码是正确的。
- 第二个是内部的,完成混屏。如果考虑到Pipeline工作太重,由一个线程完成可能会导致很大延时,那这个线程也有存在的必要。
- 第三个也是内部的,完成编码。这部分工作是否可以由第二个线程完成?毕竟是运行在服务器上,太多的线程切换也会影响性能。
音视频服务器中,每一个客户端都会对应一个endpoint的对象,完成音视频的接收、处理或转发。每一个endpoint给它对应的客户端转发的视频都必然是不一样的(至少没有自己的视频),也就意味着一个endpoint对应一个VideoMixer。而owt-server的VideoMixer至少引入了两个线程完成Pipeline,这么多线程是不是会影响服务器性能?

