为什么需要Spring Cloud Sleuth
- 微服务架构是一个分布式架构,它按业务划分服务单元,一个分布式系统往往有很多个服务单元。
- 由于服务单元数量众多,业务的复杂性,如果出现了错误和异常,很难去定位。
- 主要体现在,一个请求可能需要调用很多个服务,而内部服务的调用复杂性,决定了问题难以定位。
- 所以微服务架构中,必须实现分布式链路追踪,去跟进一个请求到底有哪些服务参与,参与的顺序又是怎样的,从而达到每个请求的步骤清晰可见,出了问题,很快定位。
举个例子,在微服务系统中,一个来自用户的请求,请求先达到前端A(如前端界面),然后通过远程调用,达到系统的中间件B、C(如负载均衡、网关等),最后达到后端服务D、E,后端经过一系列的业务逻辑计算最后将数据返回给用户。对于这样一个请求,经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?这就需要用到服务链路追踪。
基本术语
Spring Cloud Sleuth采用的是Google的开源项目Dapper的专业术语。
- Span:基本工作单元,发送一个远程调度任务 就会产生一个Span,Span是一个64位ID唯一标识的,Trace是用另一个64位ID唯一标识的,Span还有其他数据信息,比如摘要、时间戳事件、Span的ID、以及进度ID。
- Trace:一系列Span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口,需要调用多个微服务,调用每个微服务都会产生一个新的Span,所有由这个请求产生的Span组成了这个Trace。
- Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束 。这些注解包括以下:
1⃣️ cs – Client Sent -客户端发送一个请求,这个注解描述了这个Span的开始
2⃣️ sr – Server Received -服务端获得请求并准备开始处理它,如果将其sr减去cs时间戳便可得到网络传输的时间。
3⃣️ ss – Server Sent (服务端发送响应)–该注解表明请求处理的完成(当请求返回客户端),如果ss的时间戳减去sr时间戳,就可以得到服务器请求的时间。
4⃣️ cr – Client Received (客户端接收响应)-此时Span的结束,如果cr的时间戳减去cs时间戳便可以得到整个请求所消耗的时间。
案例实战
- 本文案例一共四个工程采用多Module形式
 目录结构
目录结构
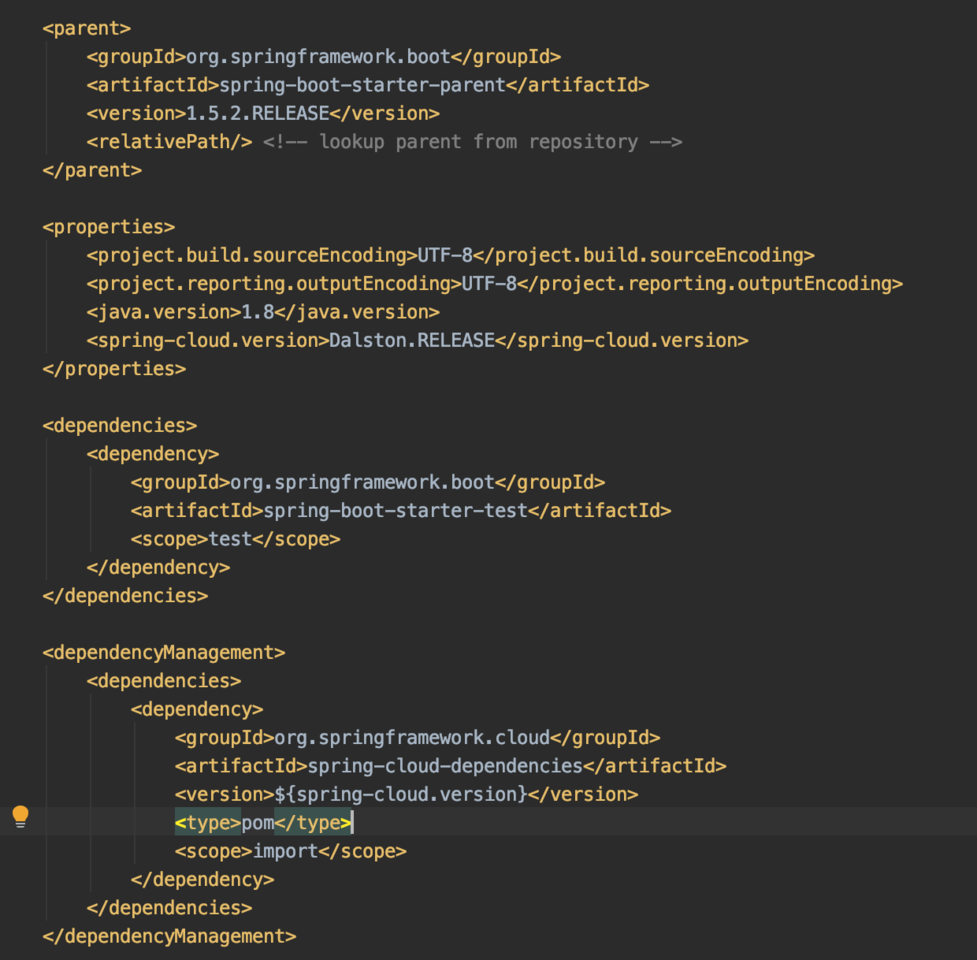
- 需要新建一个主Maven工程,主要指定了Spring Boot的版本为1.5.3,Spring Cloud版本为Dalston.RELEASE
1⃣️ 包含了eureka-server工程,作为服务注册中心 eureka-server的创建过程这里不重复
2⃣️ zipkin-server作为链路追踪服务中心,负责存储链路数据
3⃣️ gateway-service作为服务网关工程,负责请求的转发,同时它也作为链路追踪客户端,负责产生数据,并上传给zipkin-service
4⃣️ user-service为一个应用服务,对外暴露API接口,同时它也作为链路追踪客户端,负责产生数据
主maven pom文件
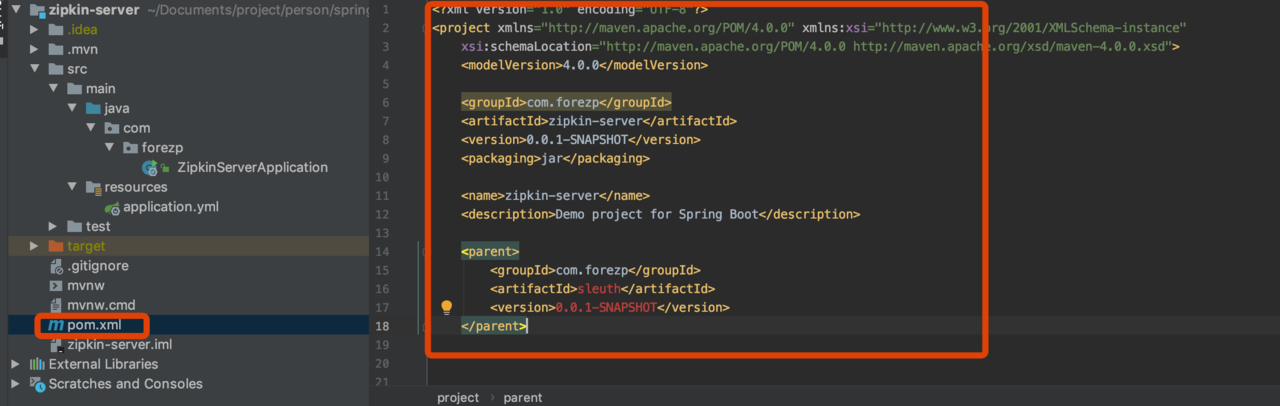
构建zipkin-server工程
- 目录结构
- pom文件
- 配置文件
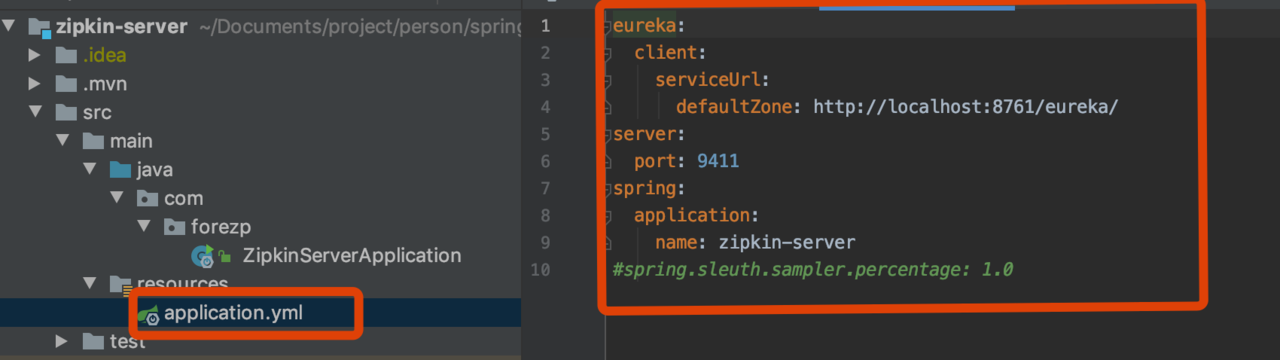
- 代码
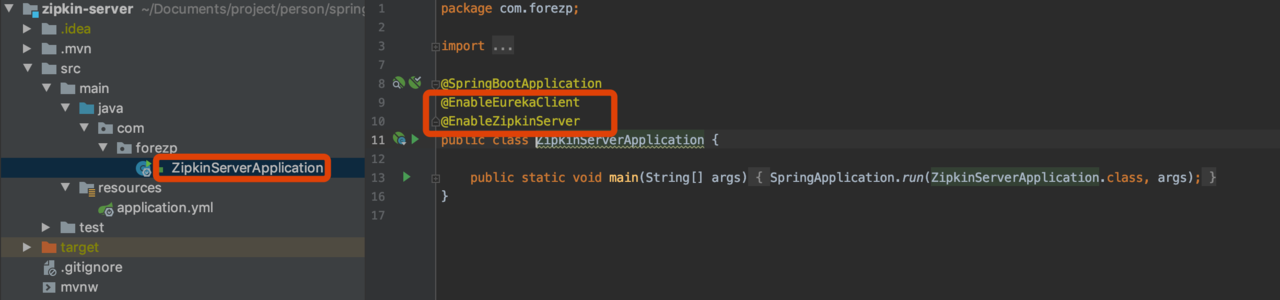
构建user-service
目录结构
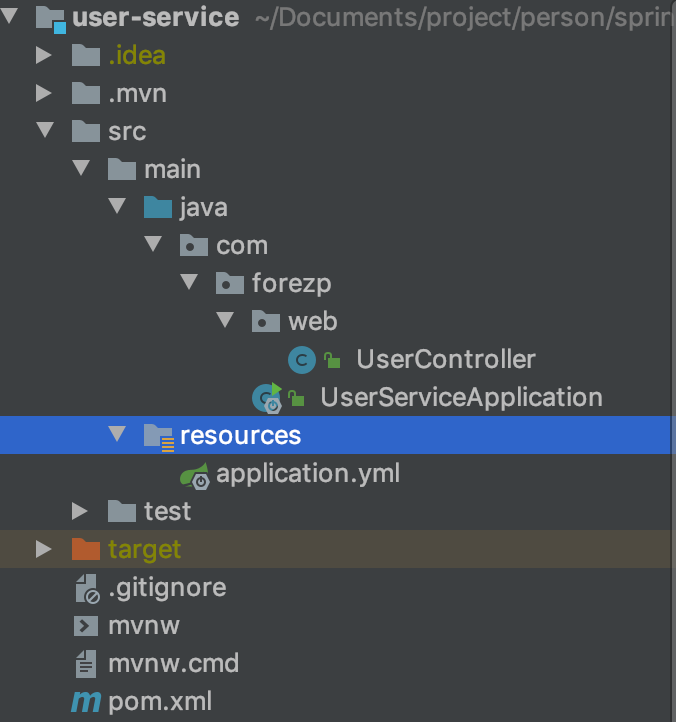
pom文件
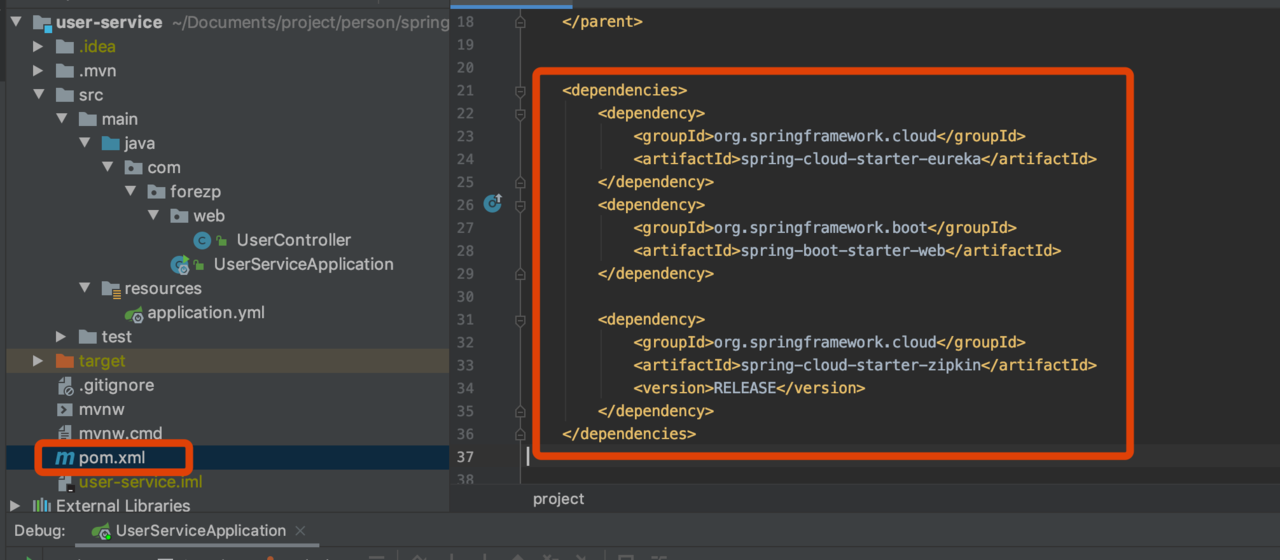
代码
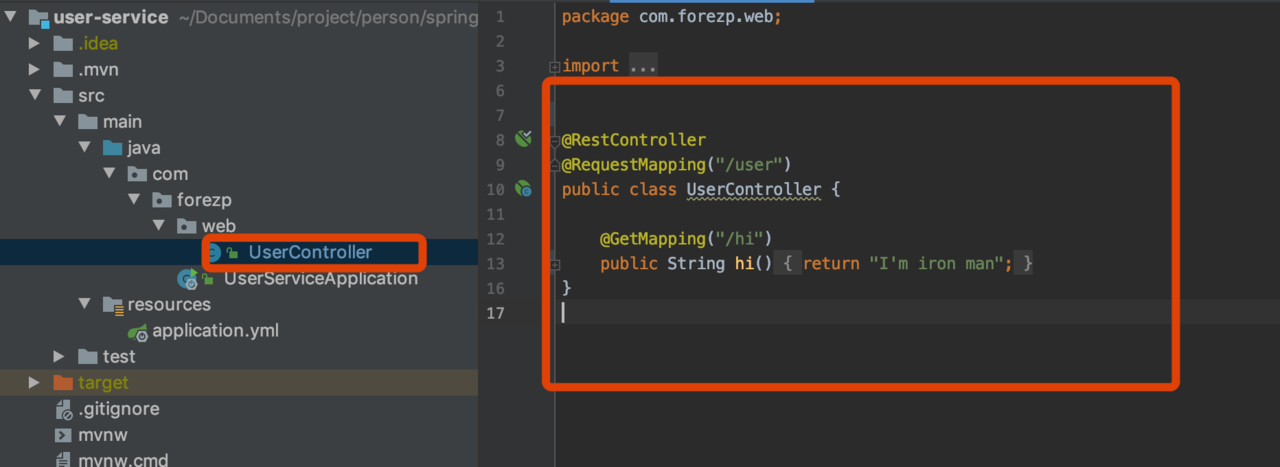
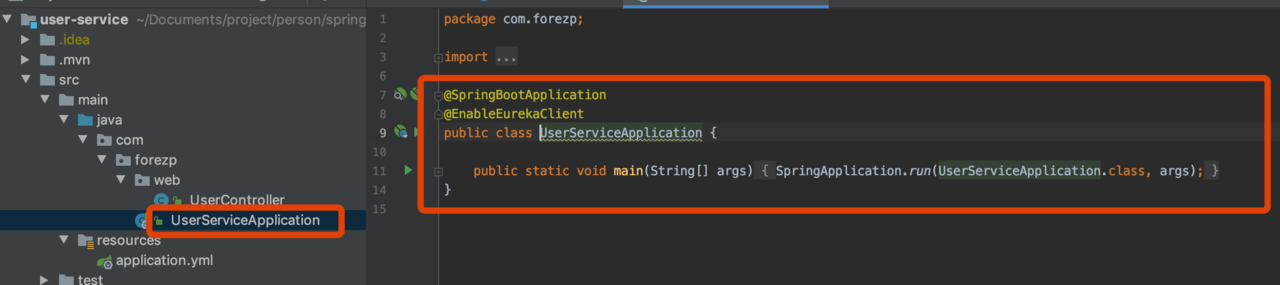
配置文件
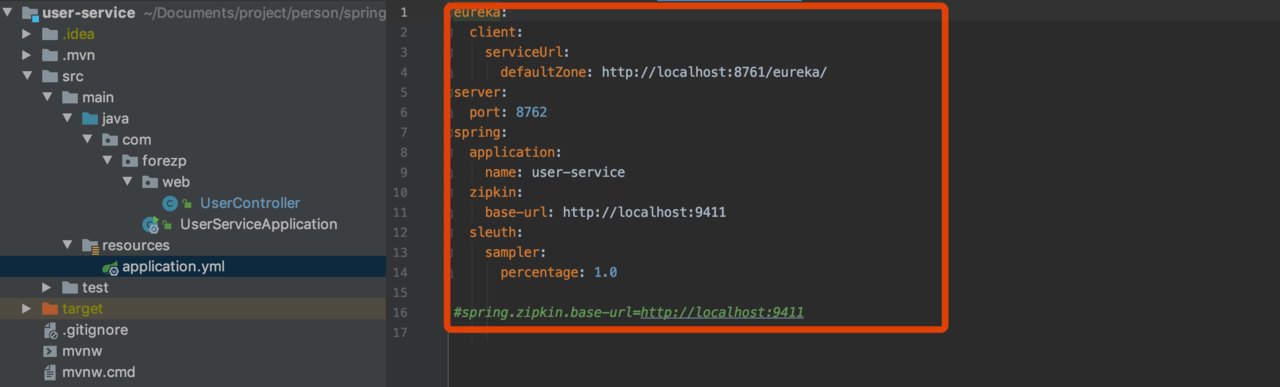
构建gateway-service
目录结构

配置文件
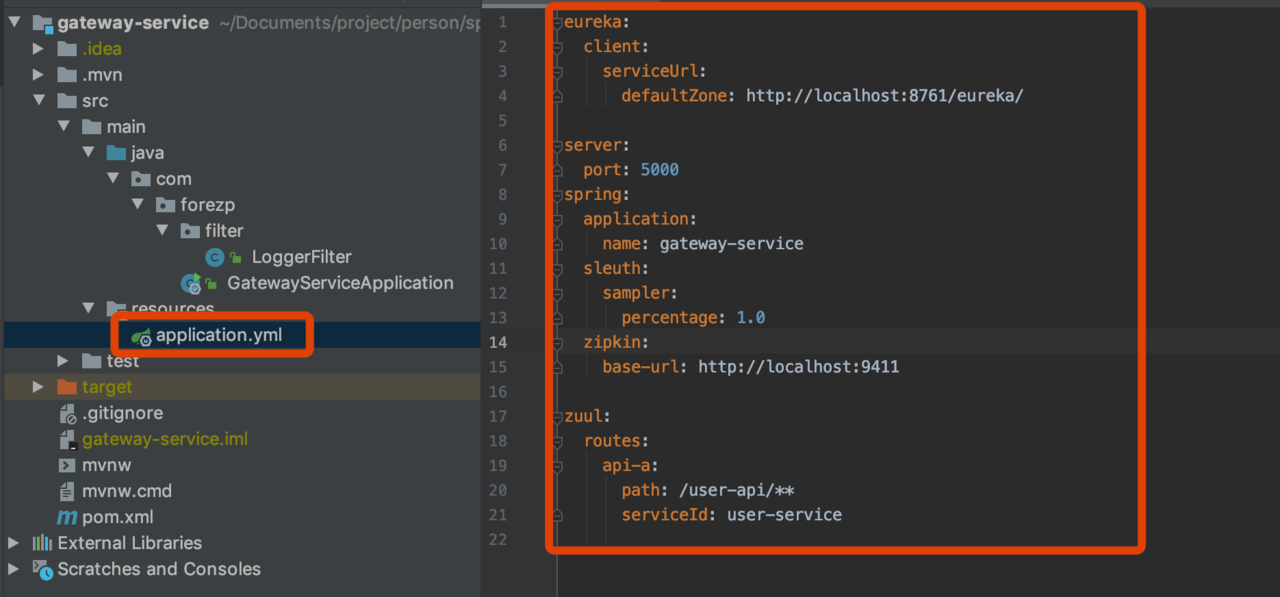
代码
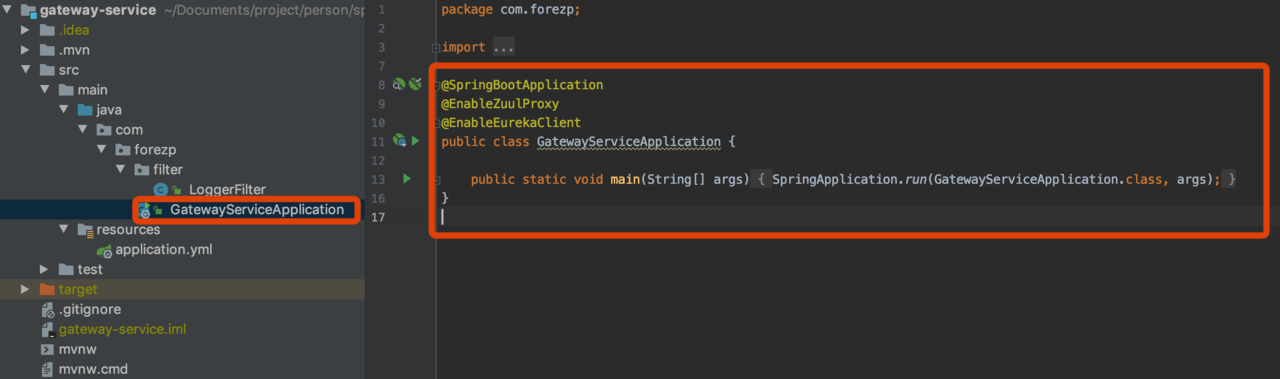
pom文件
项目演示
- 依次启动eureka-server、zipkin-server、user-service、gateway-service
- 浏览器访问 http://localhost:5000/user-api/user/hi
- http://localhost:9411,即访问Zipkin的展示界面
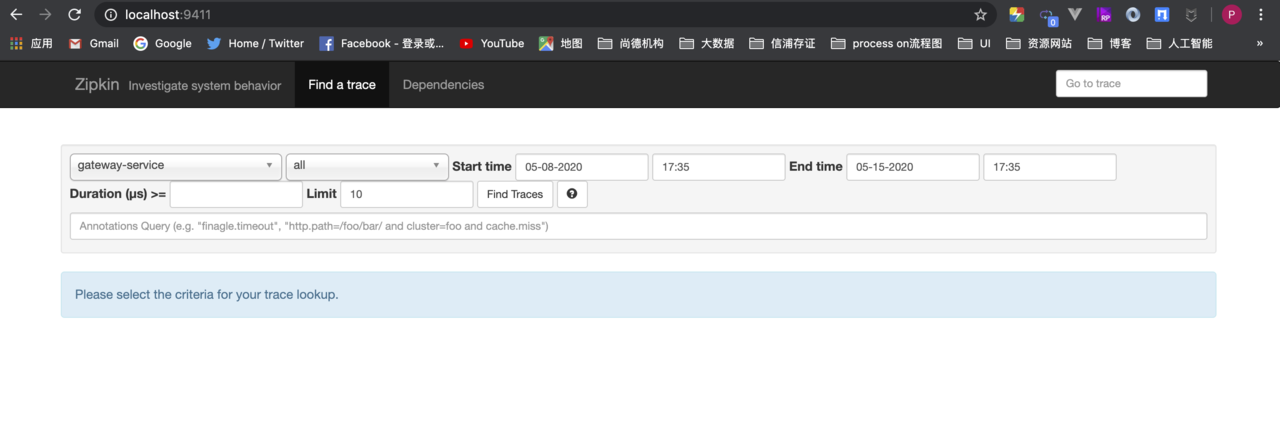
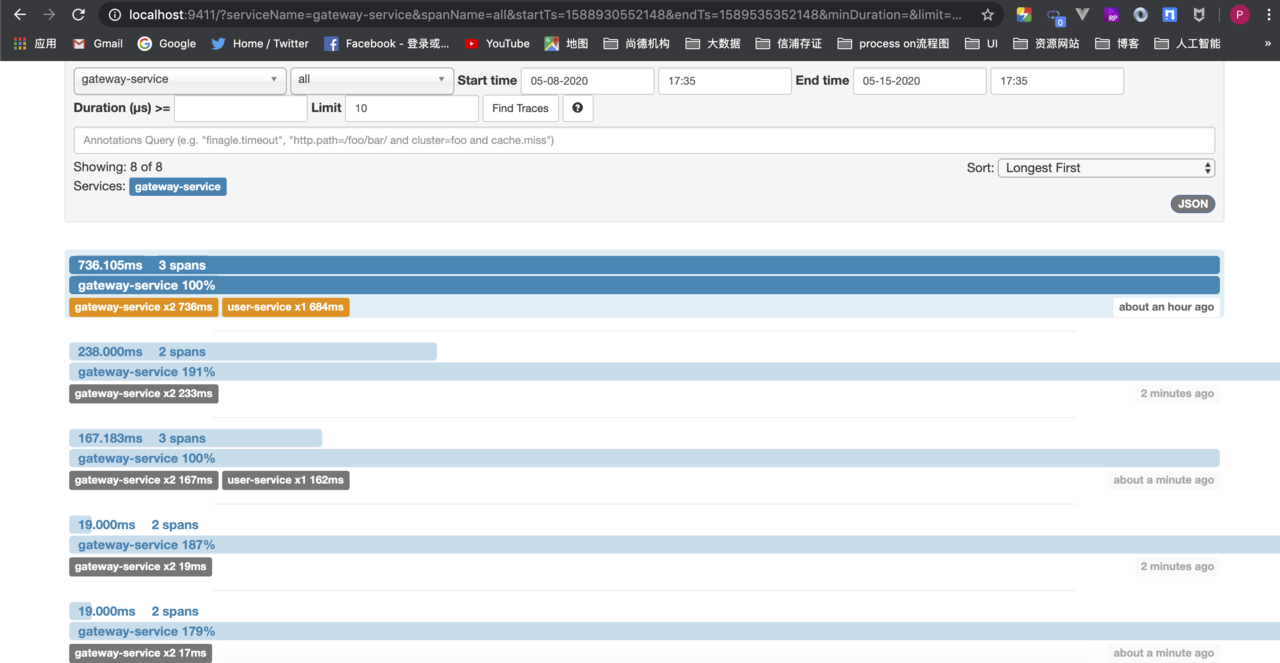
- 这个界面主要用来查找服务的调用情况,可以根据服务名、开始时间、结束时间、请求消耗的时间等条件来查找。点击“Find Trackes”按钮,界面如图所示。从图可知服务的调用情况,比如服务调用时间、服务的消耗时间,服务调用的链路情况。
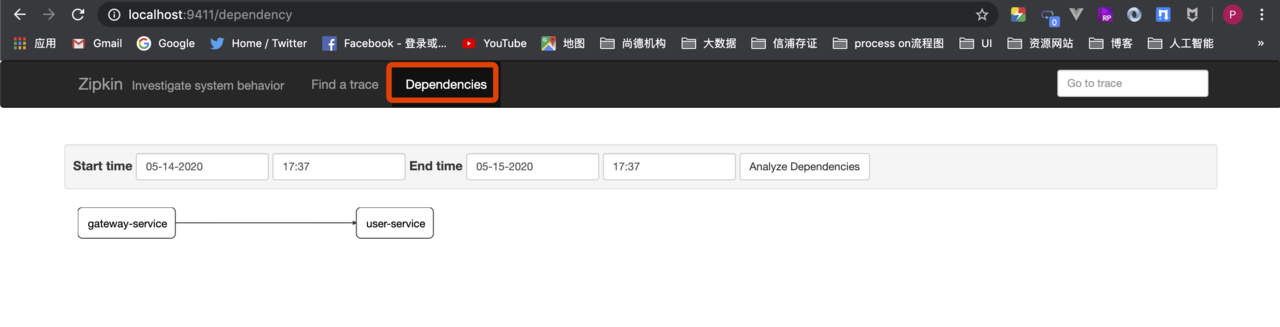
- 点击Dependences按钮,可以查看服务的依赖关系,在本案例中,gateway-service将请求转发到了user-service,它们的依赖关系如图:
怎么在链路数据中添加自定义数据
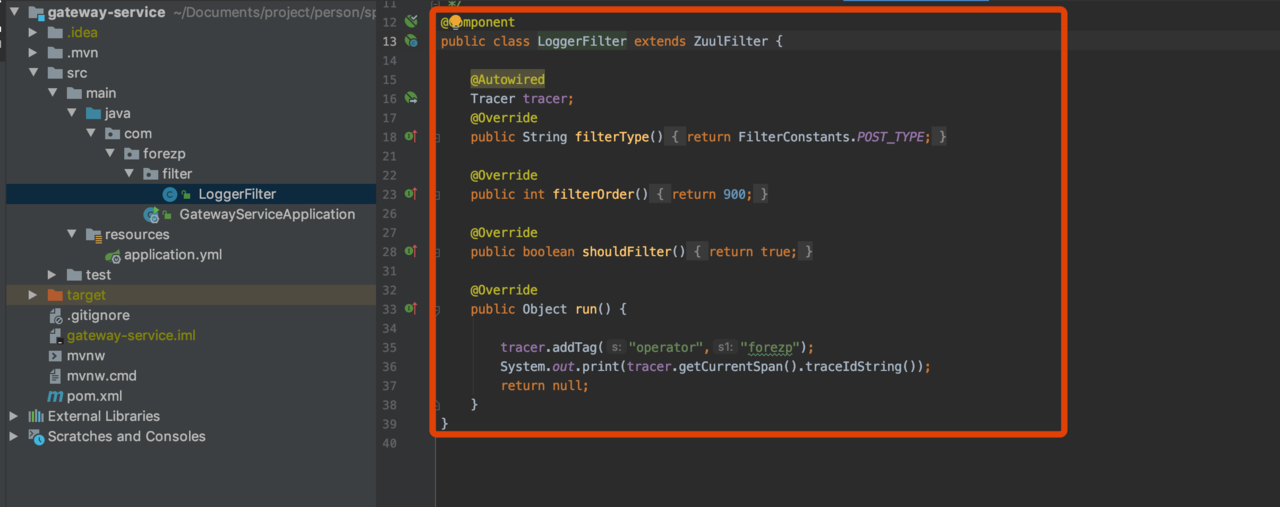
需要在gateway-service上实现。建一个ZuulFilter过滤器,它的类型为“post”,order为900,开启拦截。在拦截逻辑方法里,通过Tracer的addTag方法加上自定义的数据,比如本案例中加入了链路的操作人。另外也可以在这个过滤器中获取当前链路的traceId信息,traceId作为链路数据的唯一标识,可以存储在log日志中,方便后续查找。
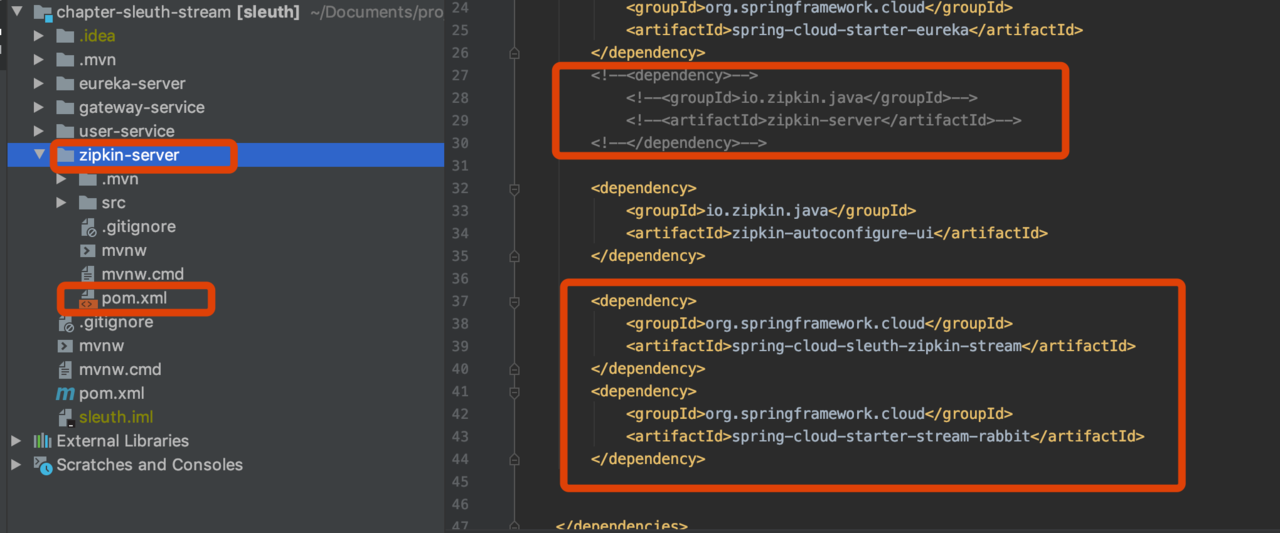
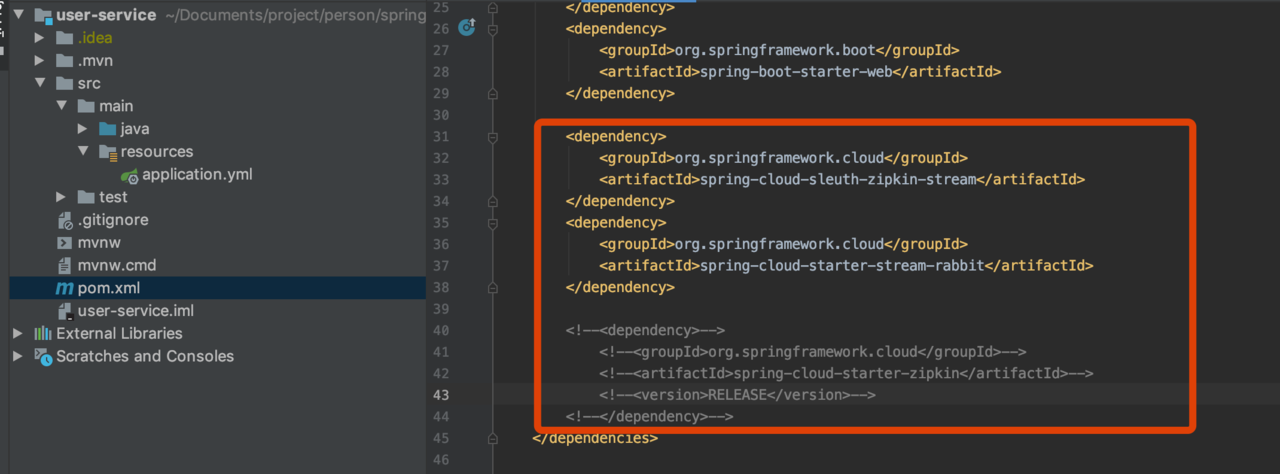
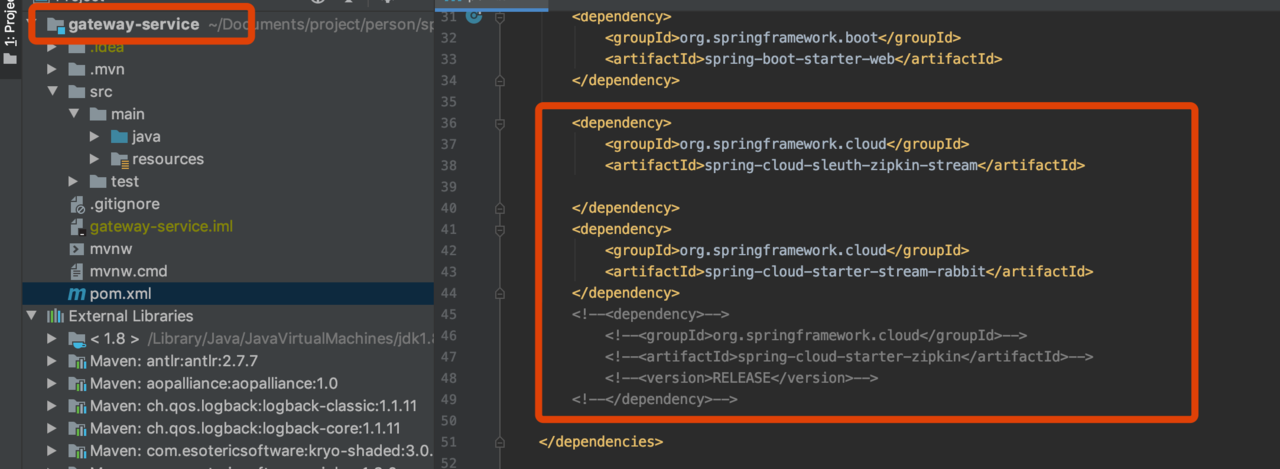
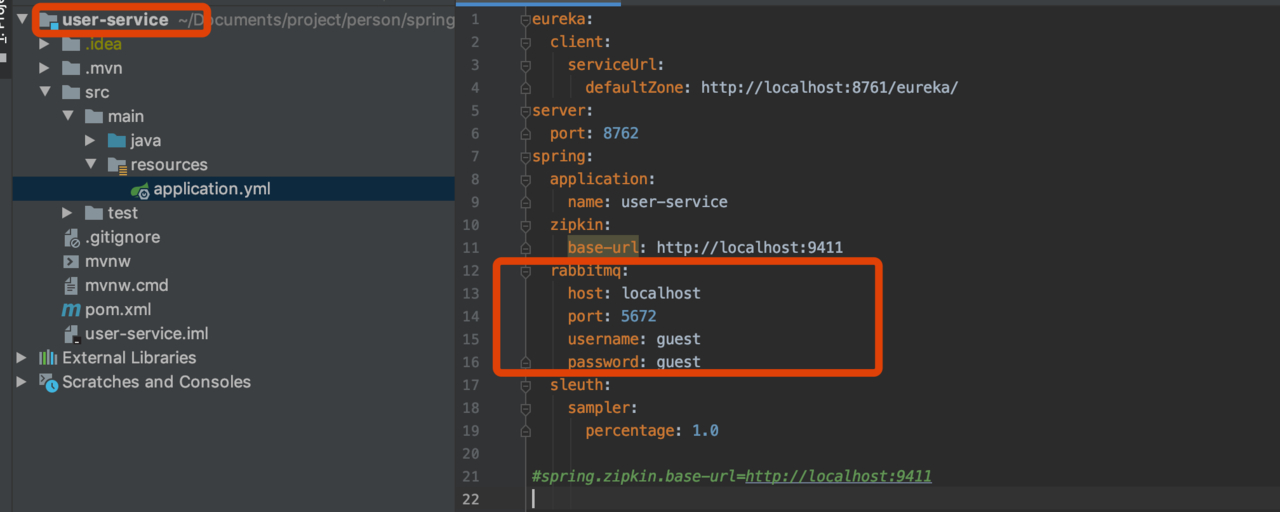
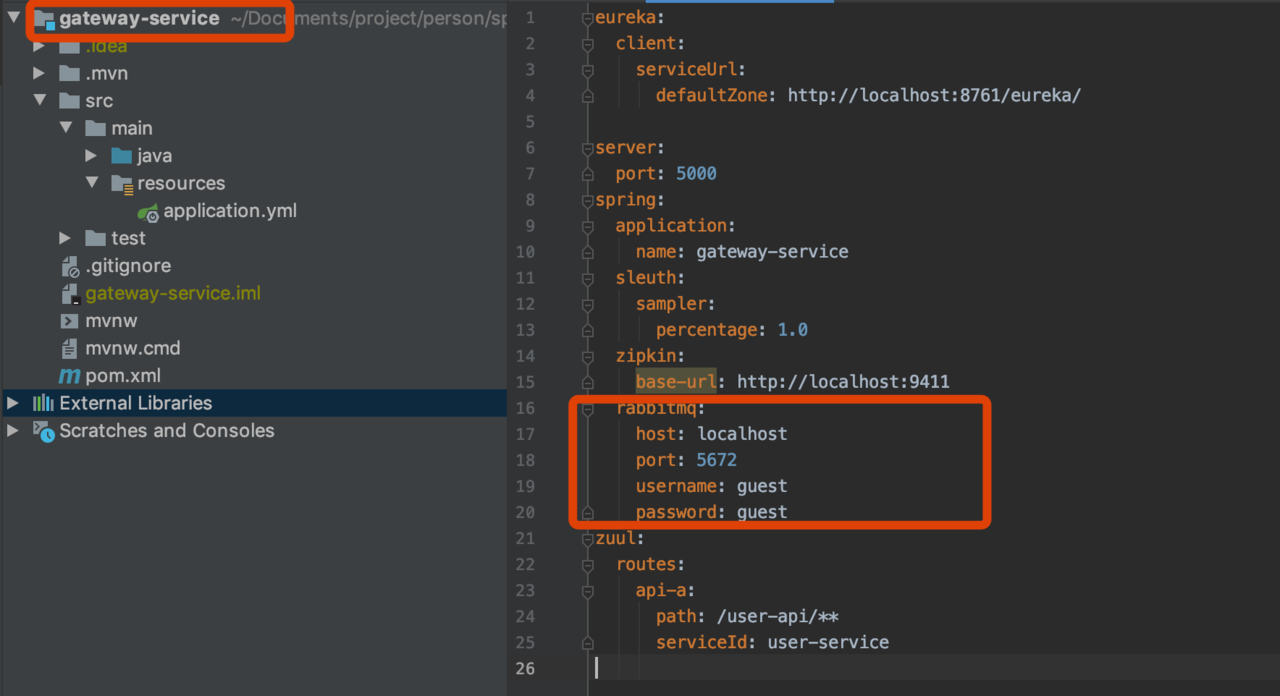
使用spring-cloud-starter-stream-rabbit进行链路通讯
在上述的案例中,最终gateway-service收集的数据,是通过Http上传给zip-server的,在Spring Cloud Sleuth中支持消息组件来通讯的
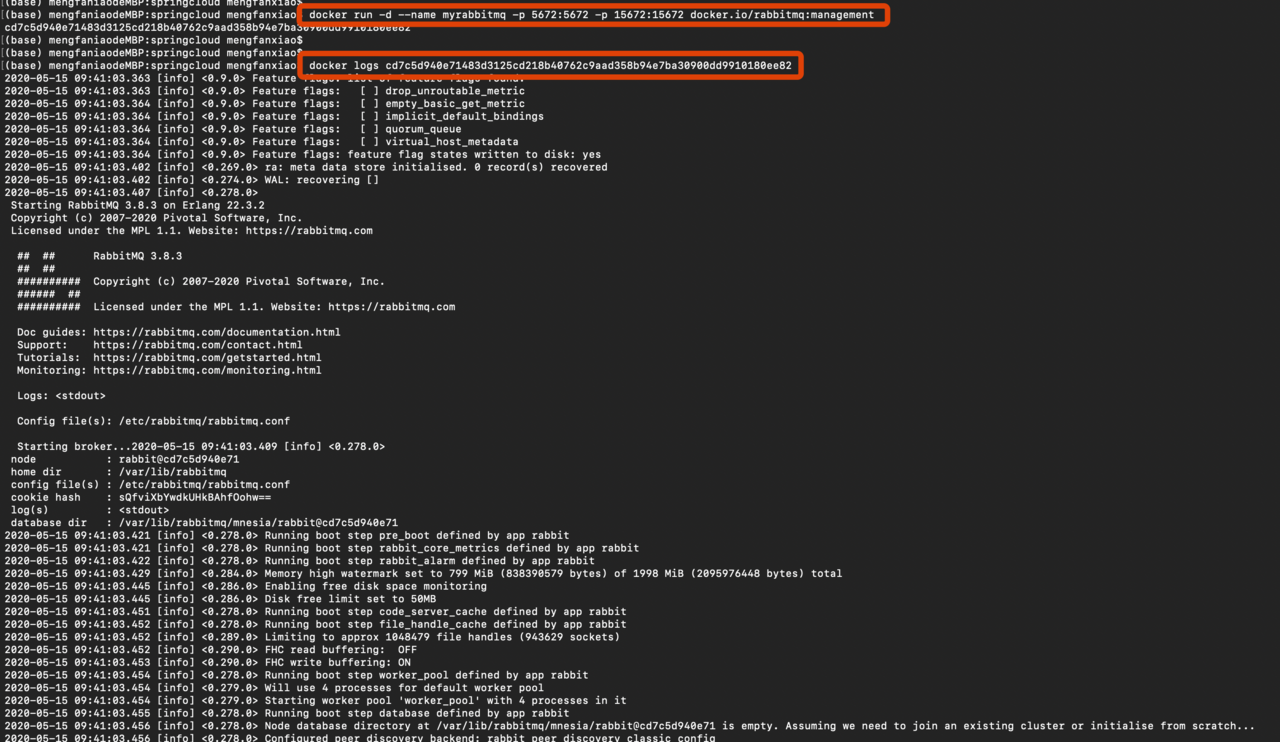
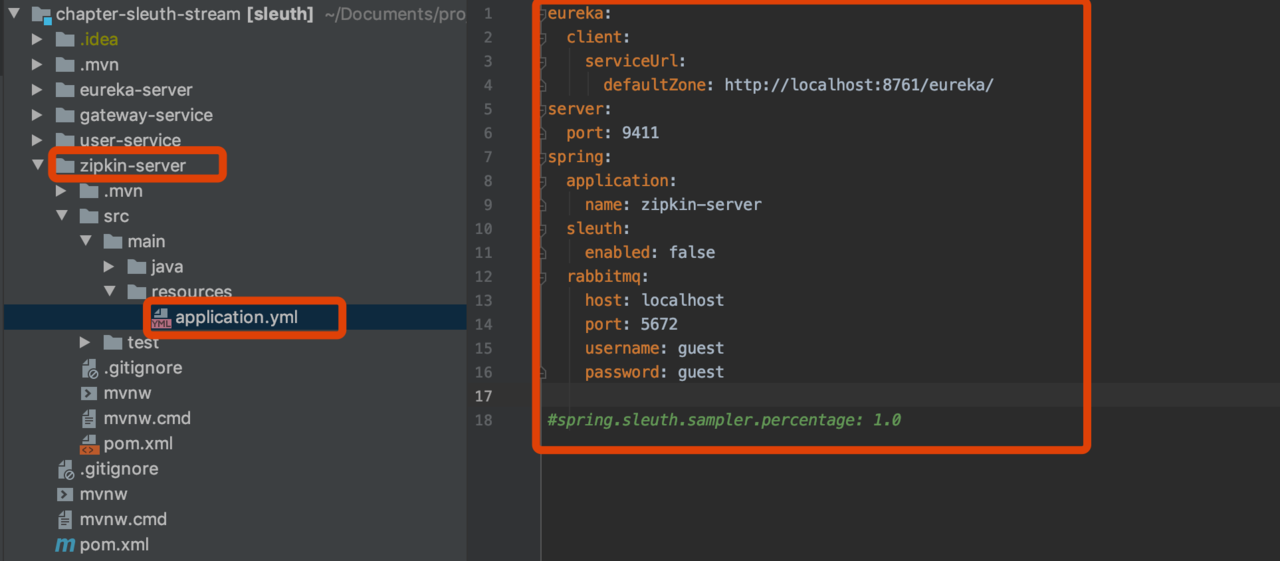
首先安装rabbitmq
- docker run -d –name myrabbitmq -p 5672:5672 -p 15672:15672 docker.io/rabbitmq:management
- 访问 http://127.0.0.1:15672/#/
改造zipkin-server
pom改造
配置文件
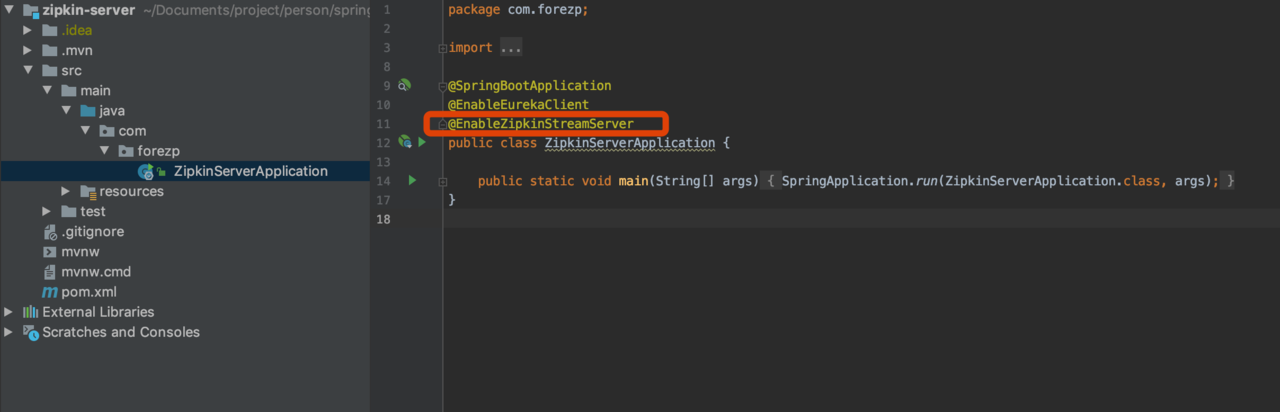
启动类
改造 Zipkin Client(包括gateway-service、user-service)
启动方式和访问方式如上
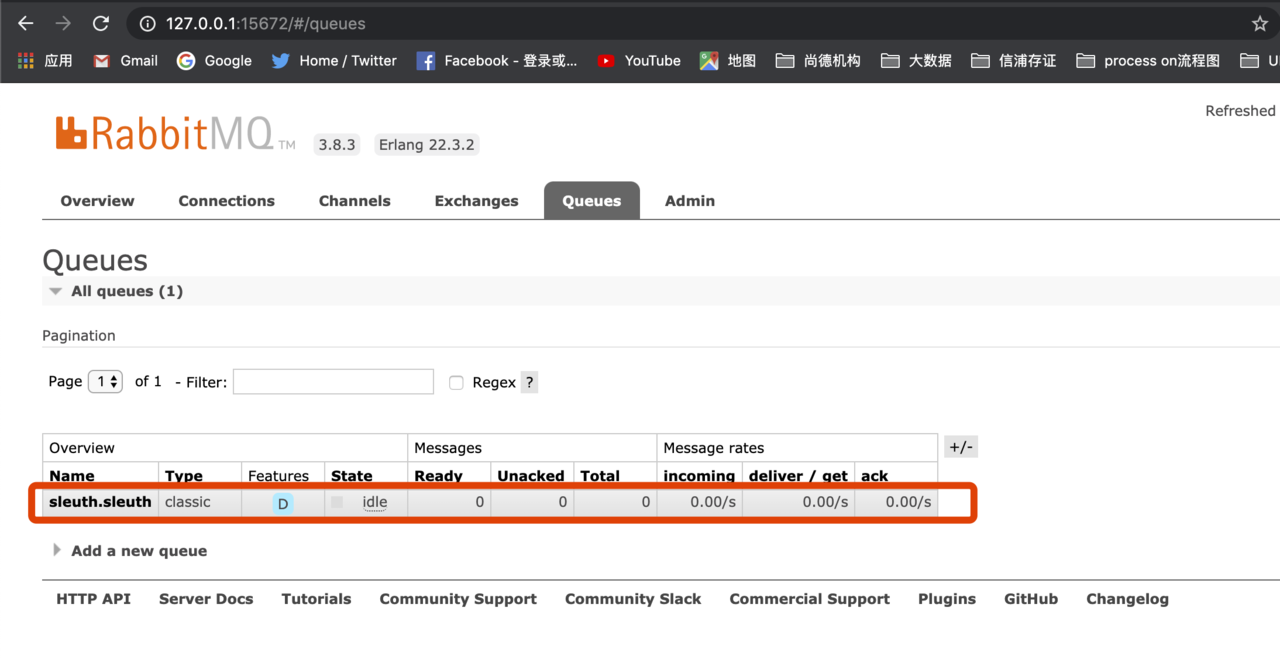
访问rabbitmq页面
这样,就将链路的上传数据从Http改了为用消息代组件RabbitMQ。
将链路数据存储在Mysql数据库
在上述的例子中,Zipkin Server是将数据存储在内存中,一旦程序重启,之前的链路数据全部丢失,那么怎么将链路数据存储起来呢?Zipkin支持Mysql、Elasticsearch、Cassandra存储
改造 zipkin-server
pom 文件
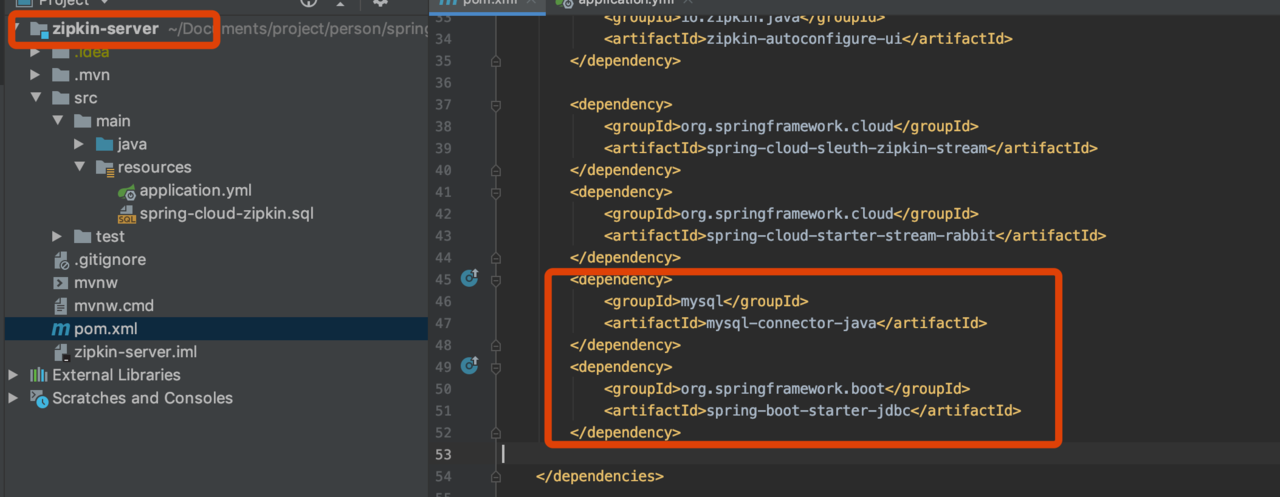
`` 备注:mysql-connector-java 依赖版本号要和数据库保持一致 比如数据库版本号是8.0.19 那么依赖 mysql-connector-java的版本号也需要是8.0.19
``
配置文件
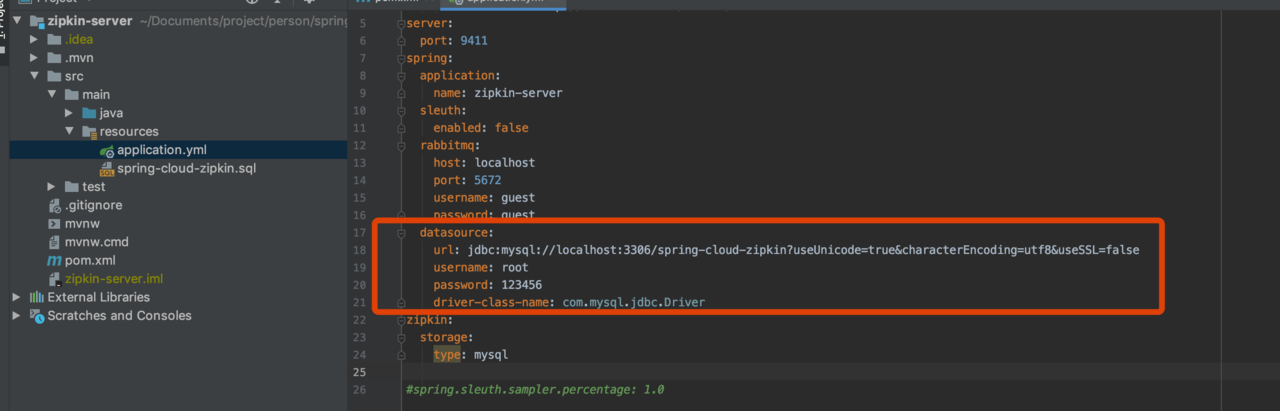
数据库
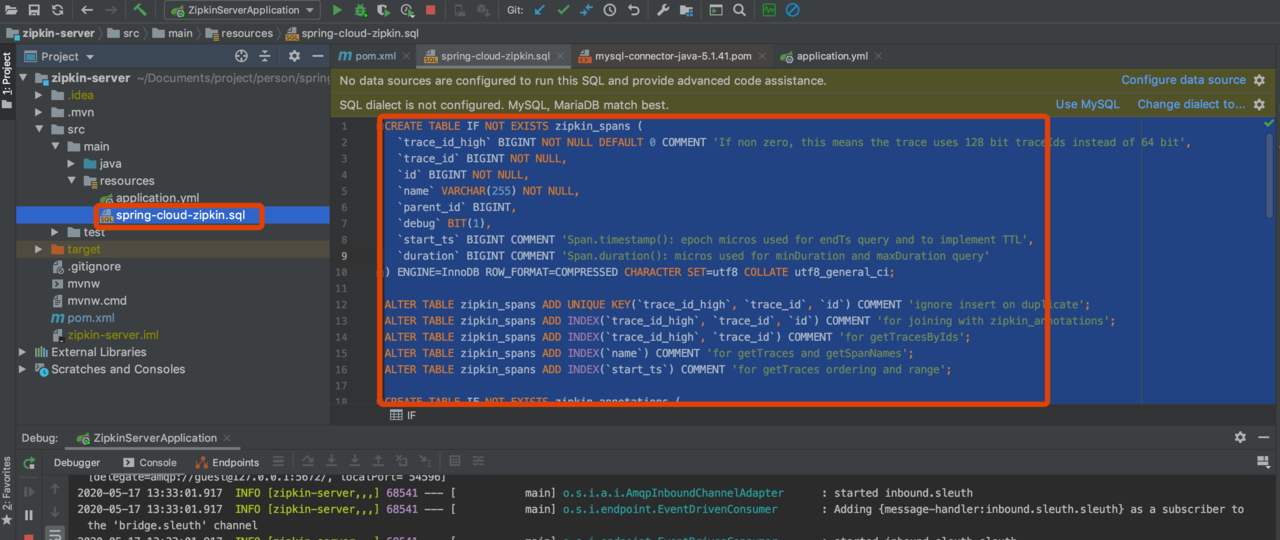
启动服务、访问接口(同上)
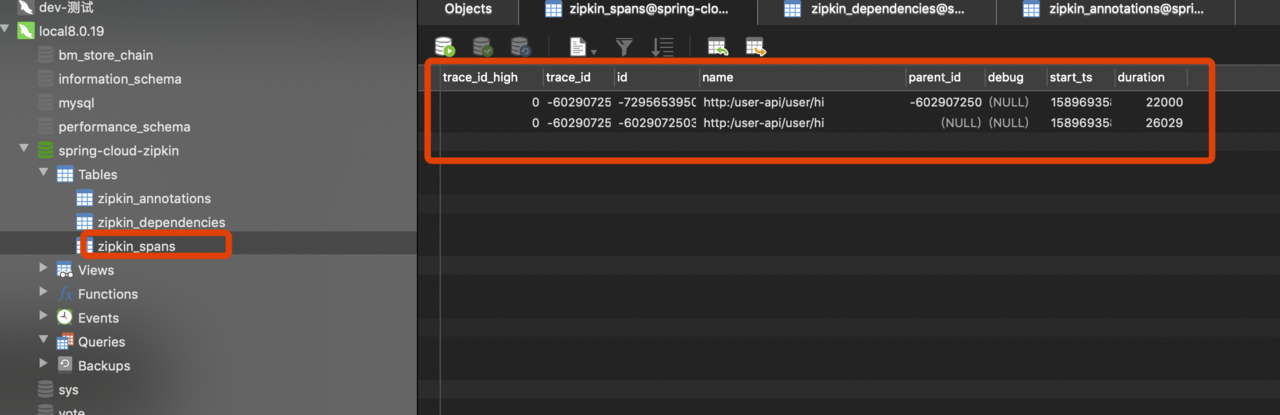
查看数据库记录
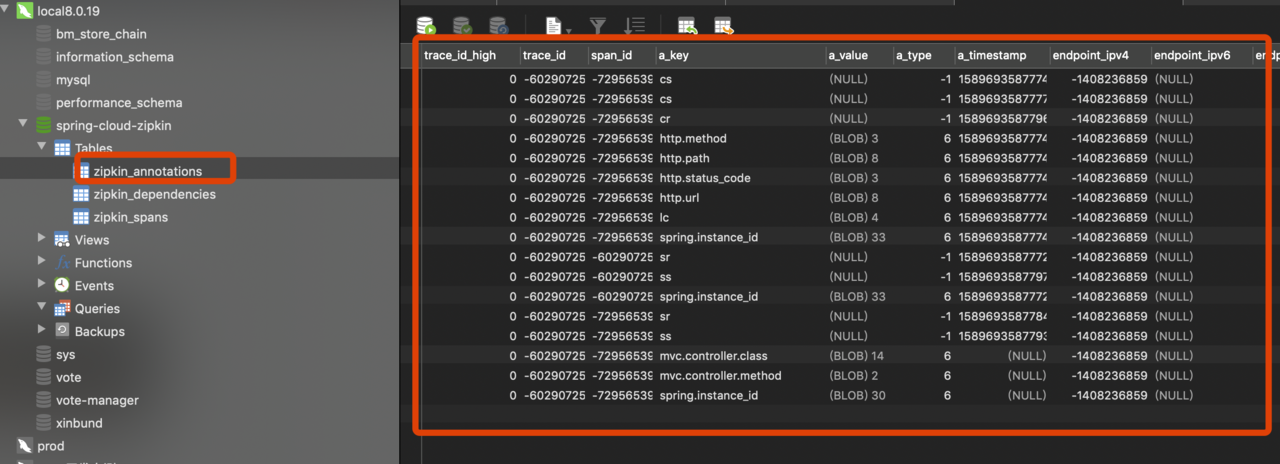
将数据存储在es中
使用Mysql存储链路数据,在并发高的情况下,显然不合理,这时可以选择使用ElasticSearch存储。
安装 ES、kibana
可参考我之前写的文章《ELK环境部署》
- 启动 ES
- 启动 Kibana
- 访问 Kibana
1⃣️ 查看本地IP ifconfig
2⃣️ 访问 http://172.16.2.197:5601
它默认会向本地的9200端口的ElasticSearch读取数据,它默认的端口为5601
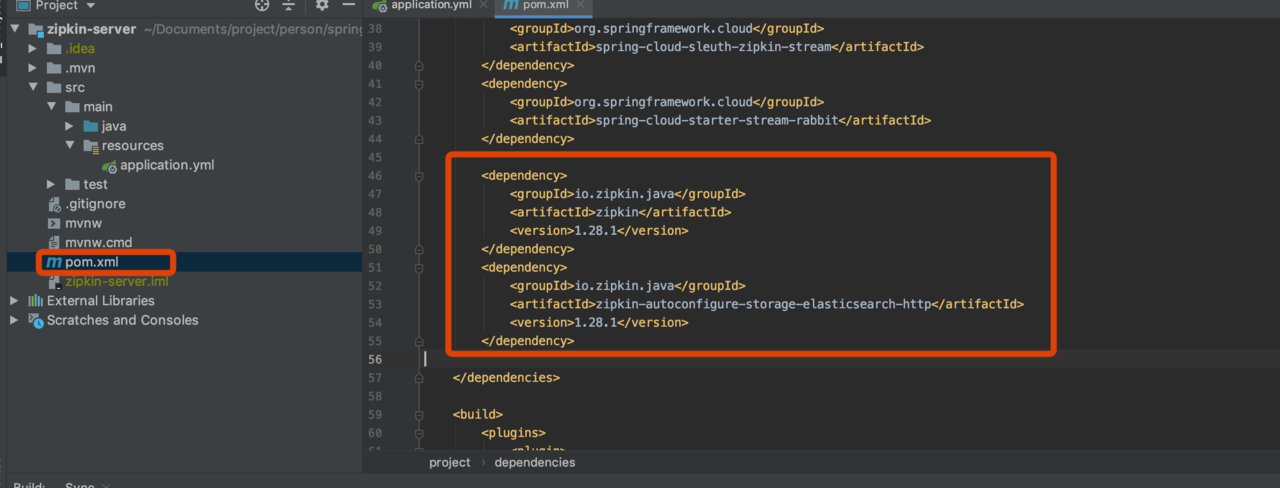
在zipkin中配置 ES
添加依赖
配置
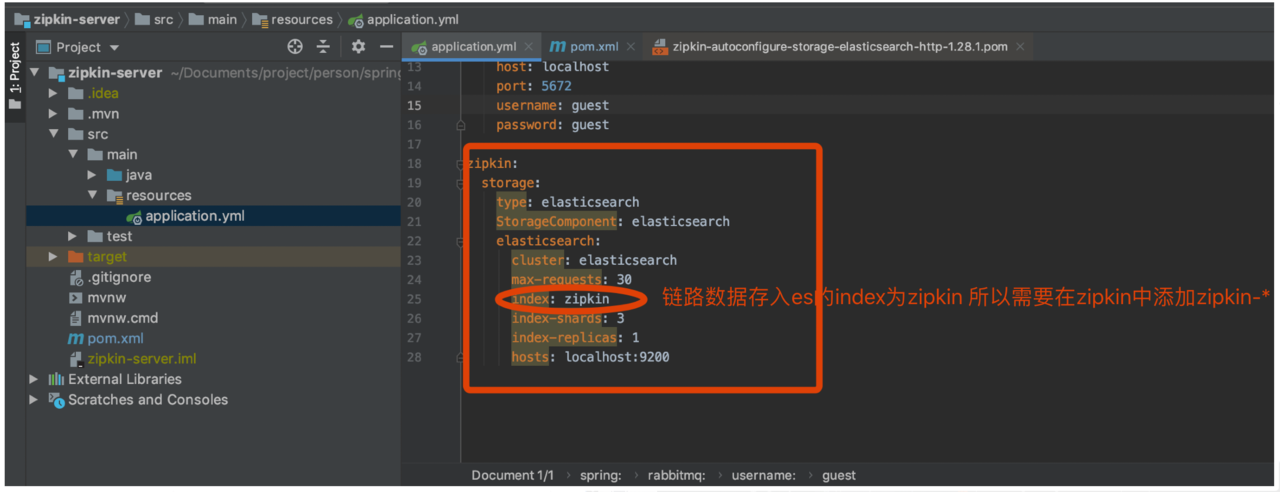
启动服务 访问接口 (同上)
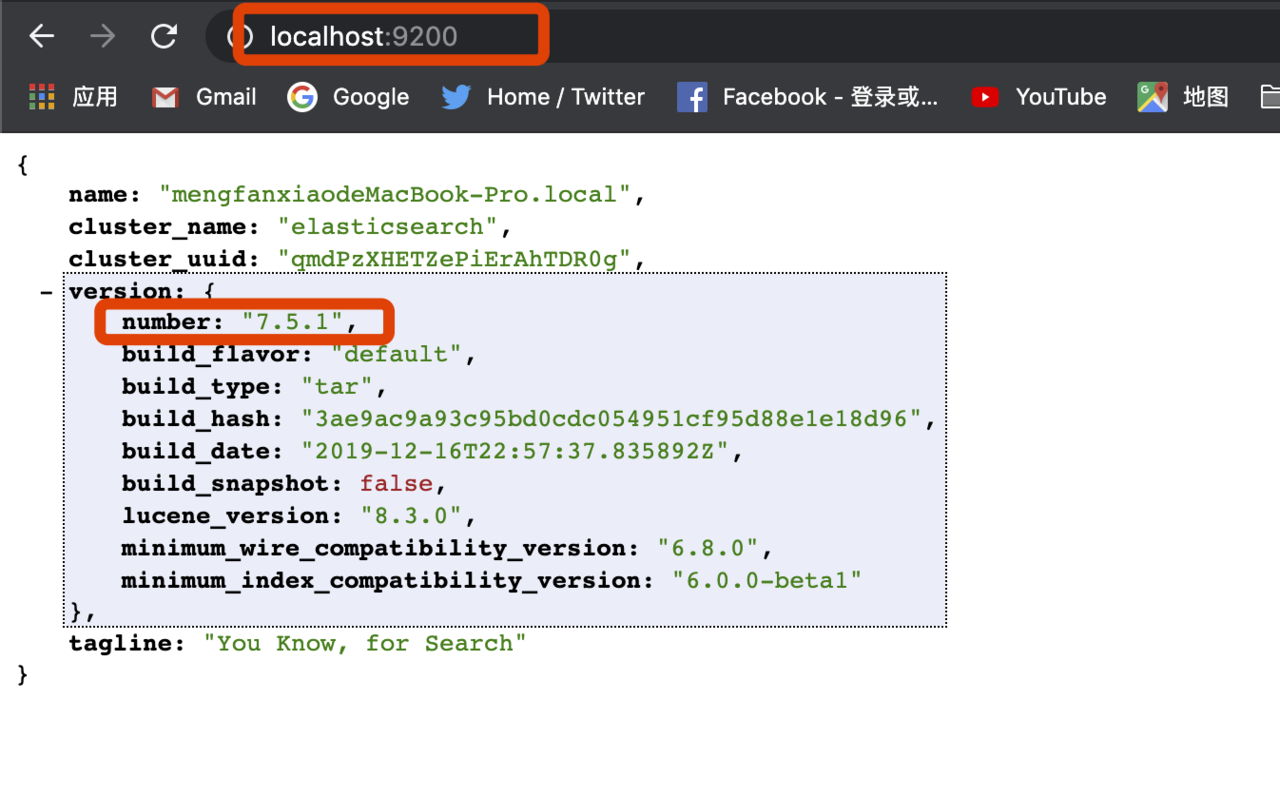
启动zipkin报错
异常:IllegalStateException(Elasticsearch 2.x and 5.x are supported, was: 7.5.1)
原因 我安装的ES版本太高7.5.1 需要安装低版本的ES
- 查看es版本
- 版本说明
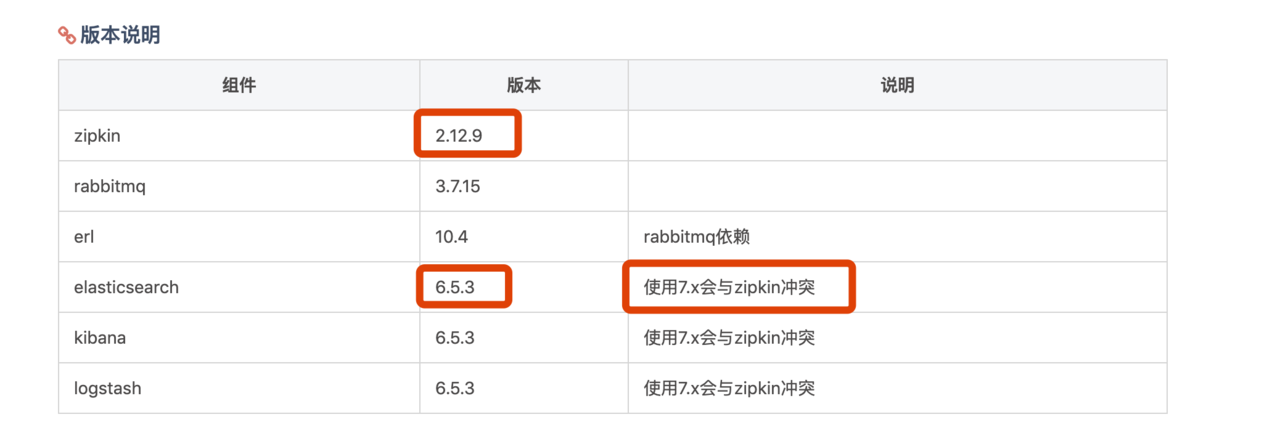
- 换成这个版本启动不会报错 但还是使用不了ES 所以不要使用新版本的ES 因为zipkin还未做兼容
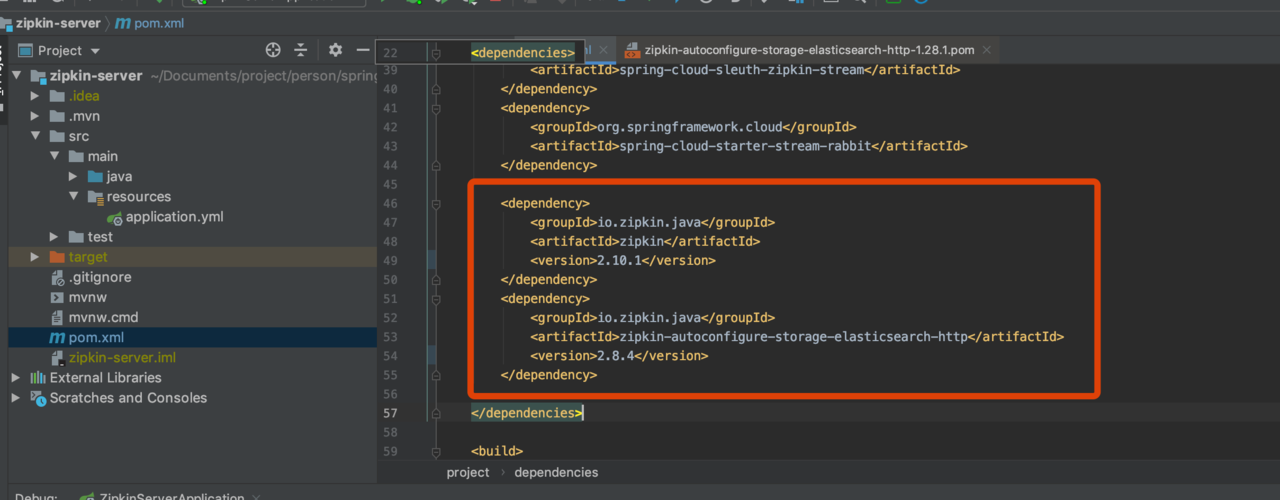
安装好了ES 6.X或更低版本
访问 kibana 添加index zipkin
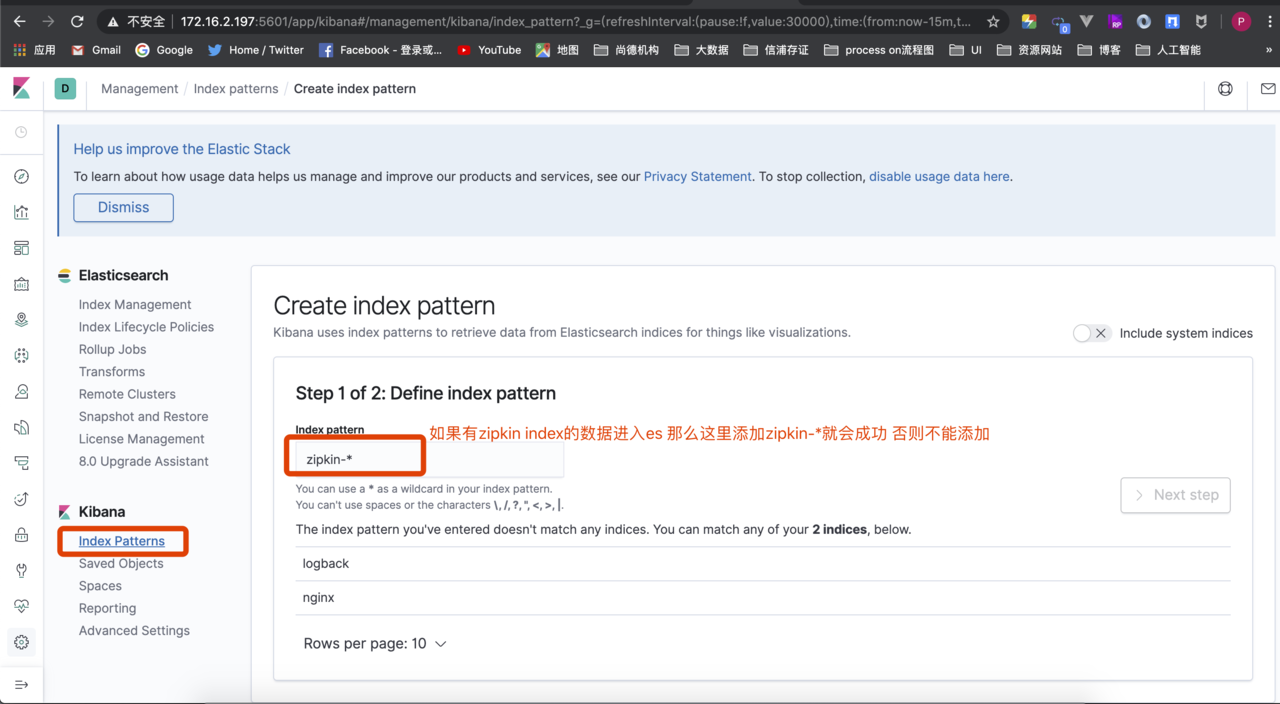
在Kibana中查看链路数据和使用图标显示数据
这里不在重复了 感兴趣的童鞋可以看我之前写的ELK部署的文章有详细的介绍
源码资源
https://gitee.com/pingfanrenbiji/SpringCloudLearning.git
参考文献
https://tech.souyunku.com6844903490045624334
本文使用 tech.souyunku.com 排版