1、WorkCount代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
public class WordCountApp {
/**
* map类,实现map函数
* * Mapper
* * KEYIN 即K1 表示每一行的起始位置(偏移量offset)
* * VALUEIN 即v1 表示每一行的文本内容
* * KEYOUT 即k2 表示每一行中的每个单词
* * VALUEOUT 即v2 表示每一行中的每个单词的出现次数,固定值1
*/
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
//暂存每个传过来的词频计数,均为1,省掉重复申请空间
private final static IntWritable one = new IntWritable(1);
//暂存每个传过来的词的值,省掉重复申请空间
private Text word = new Text();
//核心map方法的具体实现,逐个<key,value>对去处理
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
//用每行的字符串值初始化StringTokenizer
StringTokenizer itr = new StringTokenizer(value.toString());
//循环取得每个空白符分隔出来的每个元素
while (itr.hasMoreTokens()) {
//将取得出的每个元素放到word Text对象中
word.set(itr.nextToken());
//通过context对象,将map的输出逐个输出
context.write(word, one);
}
}
}
/**
* reduce类,实现reduce函数
* * KEYIN 即k2 表示每一行中的每个单词
* * VALUEIN 即v2 表示每一行中每个单词出现次数,固定值1
* * KEYOUT 即k3 表示整个文件中的不同单词
* * VALUEOUT 即v3 表示整个文件中的不同单词的出现总次数
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
//核心reduce方法的具体实现,逐个<key,List(v1,v2)>去处理
@Override
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
//暂存每个key组中计算总和
int sum = 0;
//加强型for,依次获取迭代器中的每个元素值,即为一个一个的词频数值
for (IntWritable val : values) {
//将key组中的每个词频数值sum到一起
sum += val.get();
}
//将该key组sum完成的值放到result IntWritable中,使可以序列化输出
result.set(sum);
//将计算结果逐条输出
context.write(key, result);
}
}
/**
* 启动mr的driver方法
*/
public static void main(String[] args) throws Exception {
//得到集群配置参数
Configuration conf = new Configuration();
//设置到本次的job实例中
Job job = Job.getInstance(conf, WordCountApp.class.getSimpleName());
//指定本次执行的主类是WordCount
job.setJarByClass(WordCountApp.class);
//指定map类
job.setMapperClass(TokenizerMapper.class);
//指定combiner类,要么不指定,如果指定,一般与reducer类相同
job.setCombinerClass(IntSumReducer.class);
//指定reducer类
job.setReducerClass(IntSumReducer.class);
//指定job输出的key和value的类型,如果map和reduce输出类型不完全相同,需要重新设置map的output的key和value的class类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定输入数据的路径
FileInputFormat.addInputPath(job, new Path(args[0]));
//指定输出路径,并要求该输出路径一定是不存在的
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//指定job执行模式,等待任务执行完成后,提交任务的客户端才会退出!
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Pom文件
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<configuration>
<archive>
<manifest>
<mainClass>com.hadoop.demo.WordCountApp</mainClass>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
</manifest>
</archive>
<classesDirectory>
</classesDirectory>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
最后生成Jar包 word-count-1.0-SNAPSHOT.jar
2、需要统计单词的原文
$ mkdir -p data/source
$ vim wc1
# ---- 以下是原文,随意复制的一段英文----
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.StringTokenizer;
$ mkdir -p data/apps
# 将word-count-1.0-SNAPSHOT.jar 上传么data/apps
3、通过hadoop 执行mapredurce
# 上传原文件到HDFS
$ bin/hdfs dfs -put data/source/wc1 /
# 执行Jar包
$ bin/hadoop jar data/apps/word-count-***.jar /wc1 /out
# 输出执行进度-->
20/07/23 01:33:55 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
20/07/23 01:33:55 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
20/07/23 01:33:55 INFO input.FileInputFormat: Total input paths to process : 1
20/07/23 01:33:56 INFO mapreduce.JobSubmitter: number of splits:1
20/07/23 01:33:56 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1595434593584_0001
20/07/23 01:33:56 INFO impl.YarnClientImpl: Submitted application application_1595434593584_0001
20/07/23 01:33:56 INFO mapreduce.Job: The url to track the job: http://localhost:8088/proxy/application_1595434593584_0001/
20/07/23 01:33:56 INFO mapreduce.Job: Running job: job_1595434593584_0001
20/07/23 01:34:06 INFO mapreduce.Job: Job job_1595434593584_0001 running in uber mode : false
20/07/23 01:34:06 INFO mapreduce.Job: map 0% reduce 0%
20/07/23 01:34:12 INFO mapreduce.Job: map 100% reduce 0%
20/07/23 01:34:17 INFO mapreduce.Job: map 100% reduce 100%
20/07/23 01:34:18 INFO mapreduce.Job: Job job_1595434593584_0001 completed successfully
# 将结果导出到本地
$ bin/hadoop fs -get /out /opt/data
# 查看
$ ll /opt/data
total 4
-rw-r--r--. 1 root root 372 Jul 23 01:52 part-r-00000
-rw-r--r--. 1 root root 0 Jul 23 01:52 _SUCCESS
执行结果:
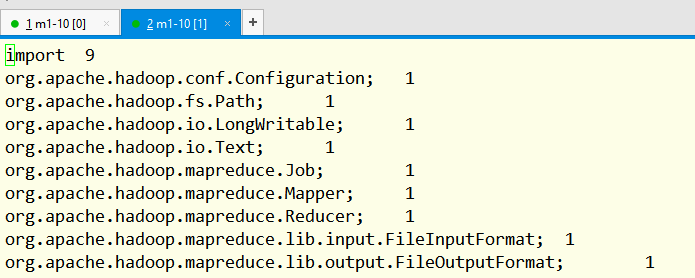
4、将任务交给yarn进行调度
# 上传原文件到HDFS 略(同上)
# yarn 执行任务
$ yarn jar data/apps/word-count-***.jar /wc1 /out
# 导出结果,查看 略(同上)
在Yarn中查看执行状态
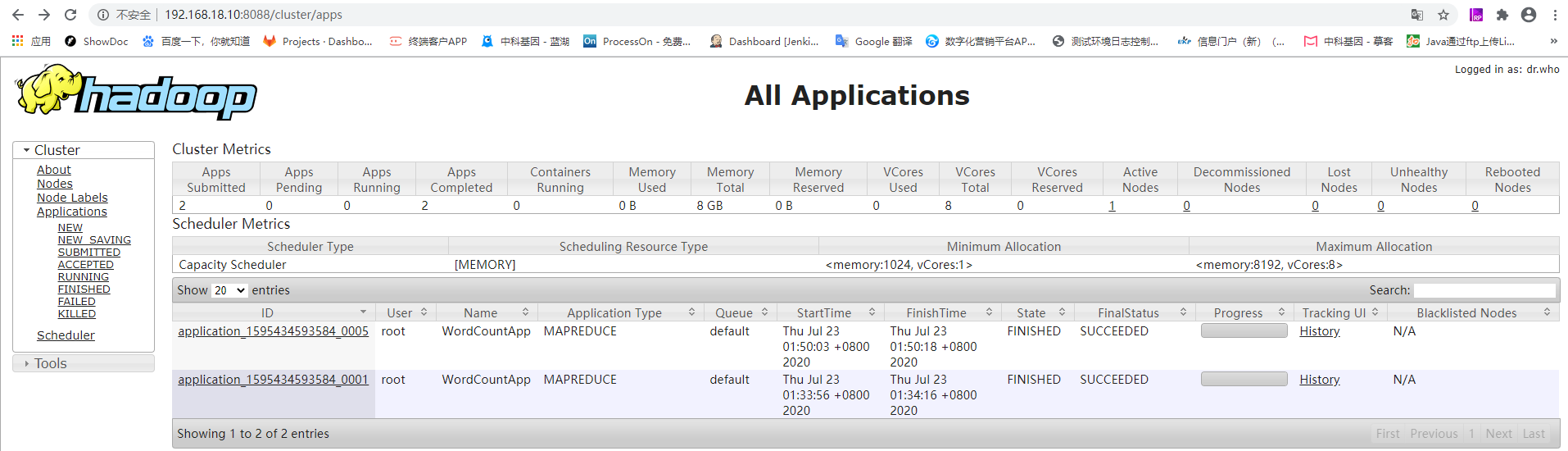
MapRedurce工作原理,参考:
https://blog.csdn.net/mucaoyx/article/details/82078226
https://tech.souyunku.com/mingyueguli/p/10368427.html