本次讲解通过requests获取某一个网站,网址:http://www.gxccedu.com/sp2017/zli/index.html
然后使用xpath提取页面中的“专利名称”。

步骤:
1、使用pycharm新建项目,新建的时候记得勾选“Inherit global site-packages”否则可能找不到requests类库
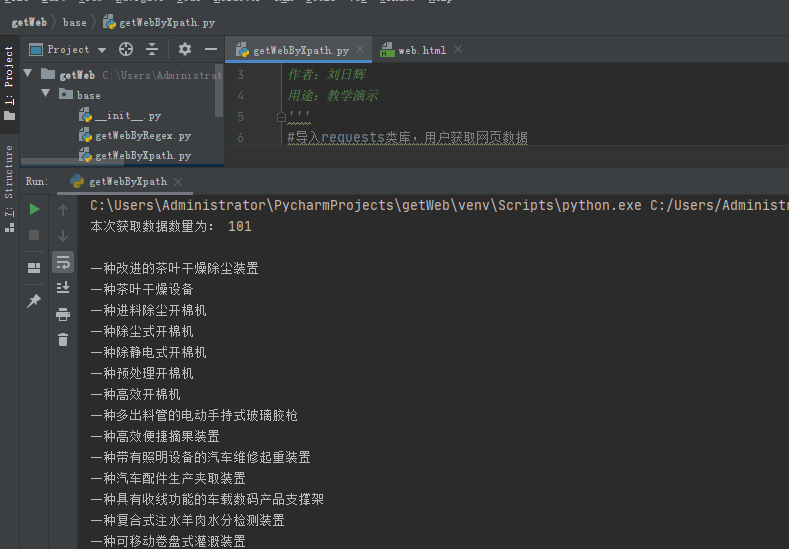
2、编写代码,我们看到网页上的数据量是101行,如下所示:

代码如下:
项目结构(不重要):
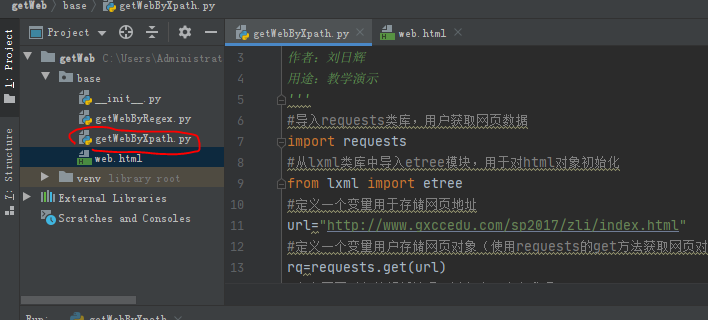
程序代码:
首先我们要分析网页的源码,在浏览器按F12可以查看到源码,把源码全选复制到一个pycharm新建的HTML文档,可以看到对应的树形结构。
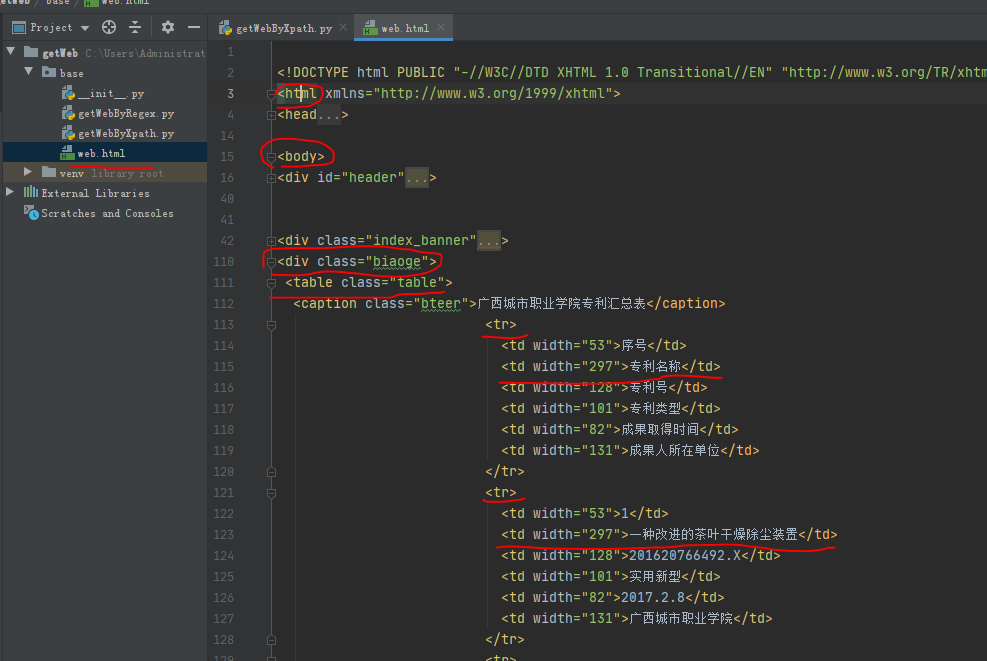
我们可以看到,在左边的编辑框这里,凡是有“-”号的,都是在树形结构内的。由此我们可以知道,如果想要获取到td,则完整的树形结构是:
html-body-div-table-tr-td
但是tr是多个的,并且第一个是表头,所以第一个不是我们想要的,所以我们要对第一个的表头抛弃掉。
另外td也是多个的,并且我们只需要每个tr里面的第二个td,所以我们可以采用下标的方式来获取。
最终完整的树形结构是:/html/body/div/table/tr[postion()>1]/td[2]
所以,代码如下:
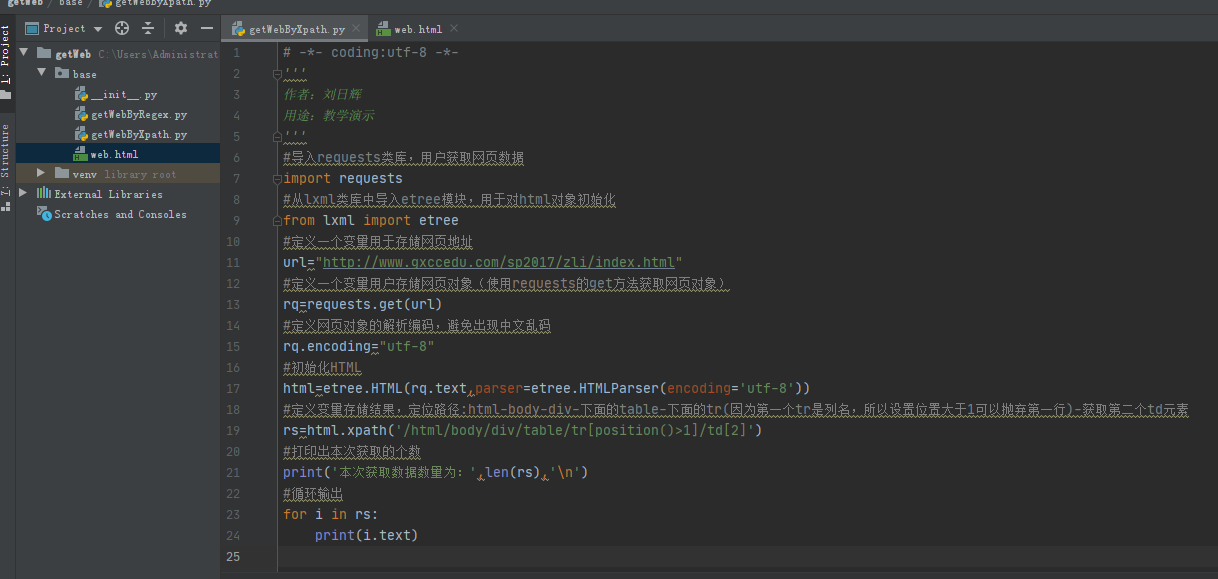
最后,运行结果: