1、访问一个url发生了什么
当我们在浏览器的地址栏输入 www.baidu.com ,然后回车,回车这一瞬间到看到页面到底发生了什么呢?
根据域名,进行DNS解析
Chrome 浏览器会首先搜索浏览器自身的 DNS 缓存(缓存时间比较短,且只能容纳 1000 条缓存),看自身的缓存中是否有 www.baidu.com 对应的条目,而且没有过期,如果有且没有过期则解析到此结束。
如果浏览器自身的缓存里面没有找到对应的条目,那么 Chrome 会搜索操作系统自身的DNS缓存,如果找到且没有过期则停止搜索解析到此结束。
如果在系统的DNS缓存也没有找到,那么尝试读取 hosts 文件,看看这里面有没有该域名对应的IP地址,如果有则解析成功。
如果在 hosts 文件中也没有找到对应的条目,浏览器就会发起一个 DNS 的系统调用,就会向本地配置的首选 DNS 服务器发起域名解析请求,运营商的 DNS 服务器首先查找自身的缓存,找到对应的条目,且没有过期,则解析成功。如果没有找到对应的条目,则有运营商的 DNS 代我们的浏览器发起迭代 DNS 解析请求。
解析到IP地址,建立TCP连接
拿到域名对应的IP地址之后,User-Agent(一般是指浏览器)会以一个随机端口(1024 < 端口 < 65535)向服务器的WEB程序(常用的有 httpd,nginx等)80 端口发起 TCP 的连接请求。这个连接请求(原始的http请求经过TCP/IP4层模型的层层封包)到达服务器端后(这中间通过各种路由设备,局域网内除外),进入到网卡,然后是进入到内核的 TCP/IP 协议栈(用于识别该连接请求,解封包,一层一层的剥开),还有可能要经过 Netfilter 防火墙(属于内核的模块)的过滤,最终到达WEB程序(本文就以Nginx为例),最终建立了 TCP/IP 的连接。
发送HTTP请求
TCP 3 次握手之后,浏览器发起了http的请求,使用的http的方法 GET 方法,请求的URL是 / ,协议是HTTP/1.0。
服务器处理请求,并返回响应结果
服务器端 WEB 程序接收到 http 请求以后,就开始处理该请求,处理之后就返回给浏览器 html 文件。关闭TCP连接。
浏览器解析HTML
浏览器拿到index.html文件后,就开始解析其中的html代码,遇到js/css/image等静态资源时,就向服务器端去请求下载(会使用多线程下载,每个浏览器的线程数不一样),这个时候就用上 keep-alive 特性了,建立一次 HTTP 连接,可以请求多个资源,下载资源的顺序就是按照代码里的顺序,但是由于每个资源大小不一样,而浏览器又多线程请求请求资源,所以从下图看出,这里显示的顺序并不一定是代码里面的顺序。
浏览器在请求静态资源时(在未过期的情况下),向服务器端发起一个http请求(询问自从上一次修改时间到现在有没有对资源进行修改),如果服务器端返回304状态码(告诉浏览器服务器端没有修改),那么浏览器会直接读取本地的该资源的缓存文件。
浏览器布局渲染
最后,浏览器利用自己内部的工作机制,把请求到的静态资源和html代码进行渲染,渲染之后呈现给用户。
2、DNS是什么原理
当前大部分的网络访问都是基于 TCP/IP 协议开发,而 TCP/IP 是基于 IP 寻址的。又因为大多数人记不住没有意义的 ip 地址,因此希望使用一些简单的域名代替地址,而 DNS 就充当了这样一个“翻译器”。我们输入域名,DNS帮我们查询对应的域名绑定的IP地址。
3、http握手 time-wait状态
根据 tcp 关闭时四次握手流程,主动关闭方会在发送完最后的ACK包后进入time_wait 状态,该状态持续时间为 2MSL (MSL 是指报文的最大生存时间,超过 MSL 时间没被接受的数据包将会被丢弃,RFC793 中建议为 2 min (30s-2min)),时间到达后将进入 close 状态,关闭本次 tcp 连接。
主动关闭方进入2MSL的 time_wait 状态的目的有二:
保证本次tcp连接中产生的所有数据包都在网络中消亡,避免本次tcp连接中产生但延迟到达的数据包影响到新建 tcp 连接的使用;
保证被动关闭方能够收到最后的 ACK。如果最后的 ACK 在网络传递中丢失了,那么被动关闭方就会重传FIN包。而主动关闭方就能在这 2MSL 时间内接受到这个 FIN 包,并重新发送 ACK 包,重新启动 2MSL 计时。
4、为什么主动关闭链接的一方Time_wait时间是2MSL,不是MSL或者其他?
TIMEWAIT状态本身和应用层的客户端或者服务器是没有关系的。仅仅是主动关闭的一方,在使用FIN|ACK|FIN|ACK四分组正常关闭TCP连接的时候会出现这个TIMEWAIT。服务器在处理客户端请求的时候,如果你的程序设计为服务器主动关闭,那么你才有可能需要关注这个TIMEWAIT状态过多的问题。如果你的服务器设计为被动关闭,那么你首先要关注的是CLOSE_WAIT。
是这样的:以客户端主动关闭的情况为例。
在服务端向客户端发送FIN,到客户端向服务端发送ACK确认的过程中。最长等待时间为2MSL。
考虑最坏的情况下,需要等待的最长时间是
去向ACK消息最大存活时间(MSL) + 来向FIN消息的最大存活时间(MSL),这恰恰就是2MSL( Maximum Segment Life)。
等待2MSL时间,A就可以放心地释放TCP占用的资源、端口号,此时可以使用该端口号连接任何服务器。
如果不等,释放的端口可能会重连刚断开的服务器端口,这样依然存活在网络里的老的TCP报文可能与新TCP连接报文冲突,造成数据冲突,为避免此种情况,需要耐心等待网络老的TCP连接的活跃报文全部死翘翘,2MSL时间可以满足这个需求(尽管非常保守)!
5、出现大量time-wait状态的原因及解决办法?
原因:
在高并发短连接的TCP服务器上,当服务器处理完请求后立刻主动正常关闭连接。这个场景下会出现大量socket处于TIME_WAIT状态。如果客户端的并发量持续很高,此时部分客户端就会显示连接不上。
为什么我们要关注这个高并发短连接呢?有两个方面需要注意:
1、 高并发可以让服务器在短时间范围内同时占用大量端口,而端口有个0~65535的范围,并不是很多,刨除系统和其他服务要用的,剩下的就更少了。
2、 在这个场景中,短连接表示“业务处理+传输数据的时间 远远小于 TIMEWAIT超时的时间”的连接。
解决办法:
编辑内核文件/etc/sysctl.conf,加入以下内容:
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
net.ipv4.tcp_fin_timeout 修改系默认的 TIMEOUT 时间
然后执行 /sbin/sysctl -p 让参数生效.
简单来说,就是打开系统的TIMEWAIT重用和快速回收。
如果以上配置调优后性能还不理想,可继续修改一下配置:
vi /etc/sysctl.conf
net.ipv4.tcp_keepalive_time = 1200
#表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 1024 65000
#表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为1024到65000。
net.ipv4.tcp_max_syn_backlog = 8192
#表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000
#表示系统同时保持TIME_WAIT套接字的最大数量,如果超过这个数字,TIME_WAIT套接字将立刻被清除并打印警告信息。
默认为180000,改为5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量,但是对于 Squid,效果却不大。此项参数可以控制TIME_WAIT套接字的最大数量,避免Squid服务器被大量的TIME_WAIT套接字拖死。
6、Tcp滑动窗口相关概念(超时重传机制和数据包的序列号保证了TCP传输的顺序性)
大家都知道,我们从一台机器向另外一台机器发送数据的时候,数据并不是一口气也不可能一口气传输给接收方。这个并不难理解,因为网络环境特别的复杂,有些地方快有些地方慢。所以,操作系统把这些数据写成连续的数据包,并且以一定的速率发给对方。
我们要考虑到带宽缓冲区等因素,如果一下子发送所有的数据只会加大网络压力,造成丢包重试,轻则传输更慢,重则网络崩溃。因为TCP是顺序发送的,操作系统将这些数据包一批一批的发送给对方,就像一个窗口,不停地往后移动,所以,我们称之为TCP滑动窗口协议。
在TCP中,窗口的大小是在TCP三次握手后协定的,并且窗口的大小并不是固定的,而是会随着网络的情况进行调整。TCP为了更好的传输效率,就会调整窗口的大小。TCP 通过滑动窗口机制检测丢包,并在丢包发生时调整数据传输速率。
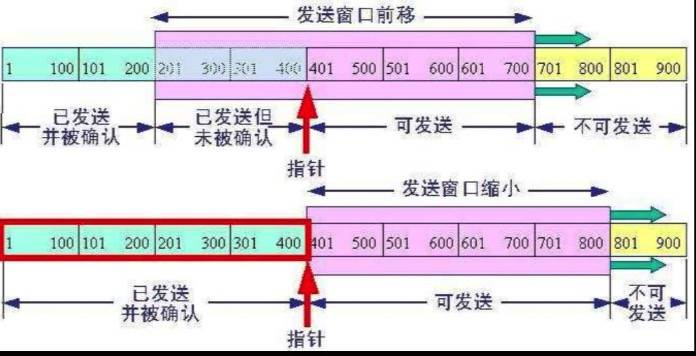
对于发送端来说,即将要发送的数据包排成一个队列,对于发送者来说,数据包总共分成四类。分别是在窗口前的,已经发送给接收方,并且收到了接收方的答复,我们称之为已发送。在窗口中的,有两种状态,一个是已经发送给接收方,但是接收方还没确认送达,我们称之为已发送未确认,另外一个是可以发送了,但是还没有发送,我们称之为允许发送未发送。最后的是在窗口外面的,我们称之为不可发送,除非窗口滑到此处,否则不会进行发送。
一旦前面的数据已经得到服务端确认了,这个窗口就会慢慢地往后滑,如下图所示,P1,P2两个数据包被确认之后,窗口就往后移动,后面新的数据包就由不可发送待发送变成了可发送状态了。
TCP的滑动窗口协议有什么意义呢?首先当然是可靠性,滑动窗口只有在队列前部的被确认之后,才会往后移动,保证数据包被接收方确认并接收。其次是传输效率,假如没有窗口,服务端是杂乱无章地进行发包,因为TCP的队首效应,如果有前面的包没有发送成功,就会不停的重试,反而造成更差的传输效率。最后是稳定性,TCP的滑动窗口大小,是整个复杂网络商榷的结果,会进行动态调整,可以尽量地避免网络拥塞,更加稳定。
7、Http相关
HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传送协议。基于TCP的应用层协议,它不关心数据传输的细节,HTTP(超文本传输协议)是一个基于请求与响应模式的、无状态的、应用层的协议,只有遵循统一的 HTTP 请求格式,服务器才能正确解析不同客户端发的请求,同样地,服务器遵循统一的响应格式,客户端才得以正确解析不同网站发过来的响应。
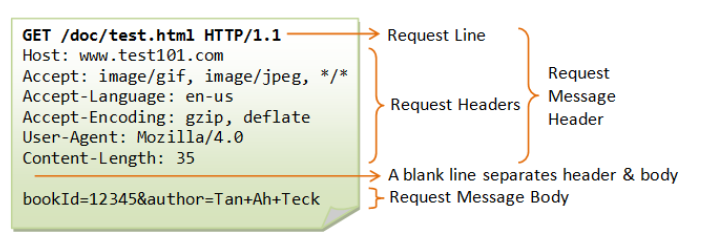
HTTP 请求由请求行、请求头、空行、请求体组成。
请求行:请求方法 + URL + 协议版本
常见的请求方法有 GET、POST、PUT、DELETE、HEAD
客户端要获取的资源路径(所谓的 URL)
客户端使用的 HTTP 协议版本号(使用的是 http1.1)
请求头: 客户端向服务器发送请求的补充说明:
host:请求地址
User-Agent: 客户端使用的操作系统和浏览器的名称和版本.
Content-Length:发送给HTTP服务器数据的长度
Content-Type:参数的数据类型
Cookie:将cookie的值发送给HTTP 服务器
Accept-Charset:自己接收的字符集
Accept-Language:浏览器自己接收的语言
Accept:浏览器接受的媒体类型
请求体: 一般携带的请求参数
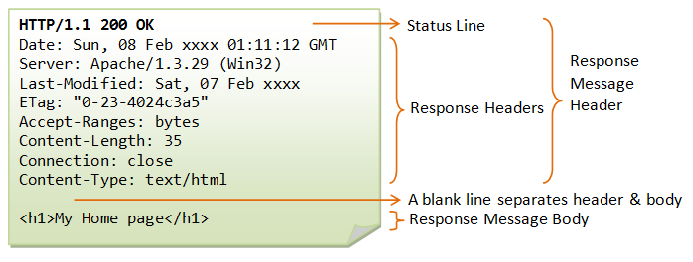
Http响应结构:
8、HTTPS相关理论
因为http的内容是明文传输的,明文数据会经过中间代理服务器、路由器、wifi热点、通信服务运营商等多个物理节点,如果信息在传输过程中被劫持,传输的内容就完全暴露了,他还可以篡改传输的信息且不被双方察觉,这就是中间人攻击。所以我们才需要对信息进行加密。最简单容易理解的就是对称加密 。
HTTPS 并不是新协议,而是让 HTTP 先和 SSL(Secure Sockets Layer)通信,再由 SSL 和 TCP 通信,也就是说HTTPS 使用了隧道进行通信。
1、什么是对称加密?
就是有一个密钥,它可以对一段内容加密,加密后只能用它才能解密看到原本的内容,和我们日常生活中用的钥匙作用差不多。
用对称加密可行吗?
如果通信双方都各自持有同一个密钥,且没有别人知道,这两方的通信安全当然是可以被保证的。
然而最大的问题就是这个密钥怎么让传输的双方知晓,同时不被别人知道。如果由服务器生成一个密钥并传输给浏览器,那这个传输过程中密钥被别人劫持弄到手了怎么办?之后他就能用密钥解开双方传输的任何内容了,所以这么做当然不行。
2、什么是非对称加密
有两把密钥,通常一把叫做公钥、一把叫做私钥,用公钥加密的内容必须用私钥才能解开,同样,私钥加密的内容只有公钥能解开。
用非对称加密可行吗?
鉴于非对称加密的机制,我们可能会有这种思路:服务器先把公钥直接明文传输给浏览器,之后浏览器向服务器传数据前都先用这个公钥加密好再传,这条数据的安全似乎可以保障了!因为只有服务器有相应的私钥能解开这条数据。
然而由服务器到浏览器的这条路怎么保障安全?如果服务器用它的的私钥加密数据传给浏览器,那么浏览器用公钥可以解密它,而这个公钥是一开始通过明文传输给浏览器的,这个公钥被谁劫持到的话,他也能用该公钥解密服务器传来的信息了。所以目前似乎只能保证由浏览器向服务器传输数据时的安全性(其实仍有漏洞,下文会说),那利用这点你能想到什么解决方案吗?
3、Https用的加密方式:非对称加密+对称加密
既然非对称加密耗时,非对称加密+对称加密结合可以吗?而且得尽量减少非对称加密的次数。当然是可以的,而且非对称加密、解密各只需用一次即可。
请看一下这个过程:
1、 某网站拥有用于非对称加密的公钥A、私钥A’。
2、 浏览器像网站服务器请求,服务器把公钥A明文给传输浏览器。
3、 浏览器随机生成一个用于对称加密的密钥X,用公钥A加密后传给服务器。
4、 服务器拿到后用私钥A’解密得到密钥X。
5、 这样双方就都拥有密钥X了,且别人无法知道它。之后双方所有数据都用密钥X加密解密。
存在问题:
中间人的确无法得到浏览器生成的密钥B,这个密钥本身被公钥A加密了,只有服务器才有私钥A’解开拿到它呀!然而中间人却完全不需要拿到密钥A’就能干坏事了。请看:
1、 某网站拥有用于非对称加密的公钥A、私钥A’。
2、 浏览器向网站服务器请求,服务器把公钥A明文给传输浏览器。
3、 中间人劫持到公钥A,保存下来,把数据包中的公钥A替换成自己伪造的公钥B(它当然也拥有公钥B对应的私钥B’)。
4、 浏览器随机生成一个用于对称加密的密钥X,用公钥B(浏览器不知道公钥被替换了)加密后传给服务器。
5、 中间人劫持后用私钥B’解密得到密钥X,再用公钥A加密后传给服务器。
6、 服务器拿到后用私钥A’解密得到密钥X。
如何证明浏览器收到的公钥一定是该网站的公钥?
数字证书:
网站在使用HTTPS前,需要向“CA机构”申请颁发一份数字证书,数字证书里有证书持有者、证书持有者的公钥等信息,服务器把证书传输给浏览器,浏览器从证书里取公钥就行了,证书就如身份证一样,可以证明“该公钥对应该网站”。然而这里又有一个显而易见的问题了,证书本身的传输过程中,如何防止被篡改?即如何证明证书本身的真实性?身份证有一些防伪技术,数字证书怎么防伪呢?解决这个问题我们就基本接近胜利了!
如何防止数字证书被篡改?
我们把证书内容生成一份“签名”,比对证书内容和签名是否一致就能察觉是否被篡改。这种技术就叫数字签名:
Https的缺点
因为需要进行加密解密等过程,因此速度会更慢;
需要支付证书授权的高额费用。
Http与Https的区别
1、 https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。
2、 http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、 http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、 http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
注:SSL与TSL是一种协议的不同叫法。
9、URI与URL、URN
URI包括URL和URN