java并发
线程创建的方法
Runnable
public class RunnableTest implements Runnable {
@Override
public void run() {//执行具体的逻辑
System.out.println(Thread.currentThread()+"启动");
}
}
public static void main(String[] args) throws Exception {
Runnable runnable = new RunnableTest();
Thread thread = new Thread(runnable);
thread.start();//启动线程
}
Thread
package thread;
public class MyThread extends Thread {
public MyThread(String name) {
super(name);
}
@Override
public void run() {
System.out.println(getName()+"启动");
try {
sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(currentThread());
}
}
public static void main(String[] args) throws Exception {
Thread thread = new MyThread("线程");
thread.start();
}
Callable和Future
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(1000);
return "完成了";
}
}
public static void main(String[] args) throws Exception {
Callable<String> callable = new MyCallable();
FutureTask<String> task = new FutureTask<>(callable);
Thread t = new Thread(task);
t.start();
System.out.println(task.get());
}
Callable和Runnable的主要区别是,Callable是有返回值的。
FutureTask是包装类,可将Callable转换为Future和Runable,它同时实现 了二者的接口。Future接口如下:
public interface Future<V> {
//取消未开始执行的方法,如果方法已经执行,并且mayInterruptIfRunning=true,则中断
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();//判断是否被取消
boolean isDone();//判断call是否执行完了
V get() throws InterruptedException, ExecutionException;//get()方法的调用会被堵塞,直到call方法中方法执行完成
V get(long timeout, TimeUnit unit)//调用超时时,会抛出异常
throws InterruptedException, ExecutionException, TimeoutException;
}
线程的状态
线程有六种状态,分别如下:
- New (新创建)
- Runnable (可运行)
- Blocked (被阻塞)
- Waiting (等待)
- Timed waitting (计时等待)
- Terminated (被终止)
可以通过getState()获取线程所处的状态
线程中断
void interrupt() //请求线程中断,线程不一定会中断
boolean isInterrupted() //检测当前线程是否中断,不会改变中断状态
static boolean interrupted() //检测当前线程是否中断,会重置中断状态为false
isInterrupted()和interrupted()的源码如下:
public static boolean interrupted() {
return currentThread().isInterrupted(true);
}
public boolean isInterrupted() {
return isInterrupted(false);
}
//true表示重置中断状态为false,false表示不改变中断状态
private native boolean isInterrupted(boolean ClearInterrupted);
注意:当线程处于New或Terminated状态时,中断操作无效,即中断状态不会改变; 当线程处于Runnable或Blocked时,中断操作只会改变中断状态,并不会中断程序, 这时需要我们使用if(Thread.currentThread().isInterrupted())来判断是否处于中断状态, 自己处理,这样增加了灵活性;当线程处于Waiting或Timed waitting时,中断操作会 抛出异常,并且结束程序。
过时的方法:
void stop()
void suspend()
void resume()
join方法
void join() 等待终止指定的线程
void join(long millis) 等待指定的线程死亡或者经过指定的毫秒数
等待所有的线程执行后执行main方法:
List<Thread> list = new Vector<>();
for (int i = 0; i <10 ; i++) {
Thread thread = new MyThread("线程"+i);
thread.start();
list.add(thread);
}
list.forEach(t -> {
try {
t.join();//注意,join方法只有在start方法之后调用才有效
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println("主线程执行");
线程优先级
每一个线程都有一个优先级,在默认的情况下,一个线程继承它父类线程的优先级。 可以使用setPriority(int newPriority)设置优先级。
优先级的等级在MIN_PRIORITY(默认值为1)和MAX_PRIORITY(默认值为10)之间;默认为 NORM_PRIORITY(默认值为5).
守护线程
守护线程的唯一用途是为其他线程通过服务。注意:守护线程应该永远不去 访问固有资源,如文件,数据库,因为它会在任何时刻甚至在一个操作中间 发生中断。
设置守护线程的方法setDaemon(boolean isDaemon)
未捕获异常处理器
当线程发生非受查异常时,我们可以设置异常处理器来处理这个异常,比如打印log或者报告给日志文件。
设置未捕获异常处理器的方法有
void setUncaughtExceptionHandler(UncaughtExceptionHandler eh)//UncaughtExceptionHandler处理异常的接口
static void setDefaultUncaughtExceptionHandler(UncaughtExceptionHandler eh)
注意:setUncaughtExceptionHandler的优先级高用setDefaultUncaughtExceptionHandler
未捕获异常处理器的工作流程:
当线程发生异常时,会判断该线程是否通过setUncaughtExceptionHandler(UncaughtExceptionHandler eh)设置默认处理器; 如果设置了,就直接调用,否则调用ThreadGroup(ThreadGroup实现了UncaughtExceptionHandler接口) 的void uncaughtException(Thread t, Throwable e);方法。ThreadGroup中的uncaughtException的实现如下:
public void uncaughtException(Thread t, Throwable e) {
if (parent != null) {//判断该线程是否有父线程组
parent.uncaughtException(t, e);
} else {
//在这里会判断atic void setDefaultUncaughtExceptionHandler(UncaughtExceptionHandler eh)
//方法是否设置了默认的处理器
Thread.UncaughtExceptionHandler ueh =
Thread.getDefaultUncaughtExceptionHandler();
if (ueh != null) {
ueh.uncaughtException(t, e);
} else if (!(e instanceof ThreadDeath)) {//如果没有设置默认处理器,则输出到控制台上
System.err.print("Exception in thread \""
+ t.getName() + "\" ");
e.printStackTrace(System.err);
}
}
}
竞争条件详解
public class Bank {
public static final int MAX_AMOUNT = 1000;
private static int[] account;
public Bank(int money) {
account = new int[10];
Arrays.fill(account,money);
}
public void transfer(int from,int to,int money){
if (money>account[from])//转账数量大于账户余额
return;
System.out.print(Thread.currentThread());
account[from]-=money;
System.out.print(from+"中的余额为 "+account[from]);
account[to]+=money;
System.out.print(" "+to+"中余额为 " + account[to]);
System.out.println(" "+Thread.currentThread()+" 总余额为 "+total());
}
private int total(){
int total = 0;
for (int value:account) {
total+=value;
}
return total;
}
}
public class Main {
static boolean isContinue = true;
public static void main(String[] args) throws Exception {
Bank bank = new Bank(100);
for (int i = 0; i <10 ; i++) {
int from = i;
Runnable runnable = ()->{
while (isContinue){
int toAccount = (int) (Math.random()*10);
int money = (int) (Math.random()*Bank.MAX_AMOUNT);
bank.transfer(from,toAccount,money);
}
};
Thread thread = new Thread(runnable);
thread.start();
}
Thread.sleep(3000);
isContinue = false;
}
}
运行结果为:
....
Thread[Thread-6,5,main]6中的余额为 28 5中余额为 40 Thread[Thread-6,5,main] 总余额为 934
Thread[Thread-6,5,main]6中的余额为 23 5中余额为 45 Thread[Thread-6,5,main] 总余额为 934
Thread[Thread-6,5,main]6中的余额为 18 6中余额为 23 Thread[Thread-6,5,main] 总余额为 934
Thread[Thread-6,5,main]6中的余额为 16 2中余额为 127 Thread[Thread-6,5,main] 总余额为 934
Thread[Thread-6,5,main]6中的余额为 0 7中余额为 491 Thread[Thread-6,5,main] 总余额为 934
Thread[Thread-7,5,main] 总余额为 995
Thread[Thread-4,5,main]4中的余额为 0 1中余额为 163 Thread[Thread-4,5,main] 总余额为 934
Thread[Thread-9,5,main]9中的余额为 42 6中余额为 39Thread[Thread-1,5,main]1中的余额为 159 1中余额为 163 Thread[Thread-1,5,main] 总余额为 934
Thread[Thread-1,5,main]1中的余额为 19 1中余额为 1632中的余额为 120 9中余额为 101Thread[Thread-5,5,main]5中的余额为 42 6中余额为 42 Thread[Thread-5,5,main] 总余额为 993
Thread[Thread-0,5,main] 总余额为 977
8中的余额为 2 4中余额为 03中的余额为 1 8中余额为 25Thread[Thread-0,5,main]0中的余额为 6 Thread[Thread-8,5,main] 总余额为 993
...
从运行结果可知,程序出现了问题。下面详细介绍下问题的原因:
问题在于这不是原子操作,指令可能被处理如下:
1、 将accounts[to]加载到寄存器
2、 增加amount
3、 将结果写回accounts[to]
现在假设第一个线程执行了步骤1和2,然后,它被剥夺了优先权。假设第2个线程被唤醒并修改了accounts数组中同一项,然后第一个线程被唤醒并完成第3步。 这样,这一动作擦去了第二个线程所做的更新,于是总金额不再正确。
锁对象
Java中提供了两种机制防止代码块受并发访问的干扰
synchronized
synchronized实现同步的基础:
- Java中每个对象都可以作为锁。当线程试图访问同步代码时,必须先获得对象锁,退出或抛出异常时必须释放锁。
Synchronzied实现同步的表现形式分为:代码块同步 和 方法同步。
synchronized的使用场景
方法同步:
public synchronized void method1
(1)锁住的是该对象,类的其中一个实例,当该对象(仅仅是这一个对象)在不同线程中执行这个同步方法时,线程之间会形成互斥。达到同步效果,但如果不同线程同时对该类的不同对象执行这个同步方法时,则线程之间不会形成互斥,因为他们拥有的是不同的锁。
代码块同步:
synchronized(this){ //TODO }
描述同(1)
方法同步:
public synchronized static void method3
(2)锁住的是该类,当所有该类的对象(多个对象)在不同线程中调用这个static同步方法时,线程之间会形成互斥,达到同步效果。
代码块同步
synchronized(Test.class){ //TODO}
描述同(2)
代码块同步:
synchronized(o) {}
这里面的o可以是一个任何Object对象或数组,并不一定是它本身对象或者类,谁拥有o这个锁,谁就能够操作该块程序代码
ReentranLock
ReentranLock的使用:
lock.lock();//获取锁对象
try{//如果使用锁,就不能使用带资源的`try`语句。
//具体方法体
}finally {
lock.unlock();//确保释放锁
}
为Bank类加上锁:
public class Bank {
...
private Lock lock = new ReentrantLock();
public void transfer(int from,int to,int money){
lock.lock();
try{
if (money>account[from])//转账数量大于账户余额
return;
System.out.print(Thread.currentThread());
account[from]-=money;
System.out.print(from+"中的余额为 "+account[from]);
account[to]+=money;
System.out.print(" "+to+"中余额为 " + account[to]);
System.out.println(" "+Thread.currentThread()+" 总余额为 "+total());
}finally {
lock.unlock();
}
}
...
每一个Bank对象都有自己的ReentrantLock对象。如果两个线程试图访问同一个Bank对象,那么锁以串行方式提供服务。但是,如果两个线程 访问不同的Bank对象,每一个线程得到不同的锁对象,两个线程都不会发生堵塞,因为线程在操作不同的Bank实例时,线程之间不会相互影响。
ReentranLock的常用方法
void lock(): 执行此方法时,如果锁处于空闲状态,当前线程将获取到锁。相反,如果锁已经被其他线程持有,将禁用当前线程,直到当前线程获取到锁。
boolean tryLock(): 如果锁可用,则获取锁,并立即返回true,否则返回false. 该方法和lock()的区别在于,tryLock()只是"试图"获取锁,如果锁不可用,不会导致当前线程被禁用,当前线程仍然继续往下执行代码。而lock()方法则是一定要获取到锁,如果锁不可用,就一直等待,在未获得锁之前,当前线程并不继续向下执行. 通常采用如下的代码形式调用tryLock()方法:
void unlock(): 执行此方法时,当前线程将释放持有的锁. 锁只能由持有者释放,如果线程并不持有锁,却执行该方法,可能导致异常的发生.
Condition newCondition(): 条件对象,获取等待通知组件。该组件和当前的锁绑定,当前线程只有获取了锁,才能调用该组件的await()方法,而调用后,当前线程将释放锁
条件对象
在上面对转款超过自己余额的操作是直接取消这次操作,这个符合一般的常识。但是有时候我们我们会等待别人转账过来。
if (money>account[from])
return;
例如:
if (money>account[from])
wait();
但是由于这个线程获得了锁,具有排他性,因此没有别的线程可以转账,为了解决这个问题,我们可以使用条件对象(或者叫做条件变量)
package thread;
import java.util.Arrays;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class Bank {
...
private Lock lock = new ReentrantLock();
private Condition condition = lock.newCondition();
public void transfer(int from,int to,int money){
lock.lock();
try{
if (money>account[from])//转账数量大于账户余额
condition.await();//让线程等待,进入阻塞状态,并放弃锁
System.out.print(Thread.currentThread());
account[from]-=money;
System.out.print(from+"中的余额为 "+account[from]);
account[to]+=money;
System.out.print(" "+to+"中余额为 " + account[to]);
System.out.println(" "+Thread.currentThread()+" 总余额为 "+total());
condition.signalAll();//解除所有该条件等待线程的阻塞状态
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
...
注意:signalAll()方法不会立即激活一个等待线程,它仅仅解除阻塞状态,以便这些线程可以在当前线程退出同步方法后,通过 竞争实现对对象的访问。另一个方法signal()只会随机解除一个线程的阻塞状态,如果随机选择的线程仍然不能运行,就会再次阻塞, 如果没有其他线程再次调用signal(),那么系统就死锁了。
重入锁
当一个线程得到一个对象后,再次请求该对象锁时是可以再次得到该对象的锁的。 具体概念就是:自己可以再次获取自己的内部锁。 Java里面内置锁(synchronized)和Lock(ReentrantLock)都是可重入的。
public class SynchronizedTest {
public void method1() {
synchronized (SynchronizedTest.class) {
System.out.println("方法1获得ReentrantTest的锁运行了");
method2();
}
}
public void method2() {
synchronized (SynchronizedTest.class) {
System.out.println("方法1里面调用的方法2重入锁,也正常运行了");
}
}
public static void main(String[] args) {
new SynchronizedTest().method1();
}
}
上面便是synchronized的重入锁特性,即调用method1()方法时,已经获得了锁,此时内部调用method2()方法时,由于本身已经具有该锁,所以可以再次获取。
public class ReentrantLockTest {
private Lock lock = new ReentrantLock();
public void method1() {
lock.lock();
try {
System.out.println("方法1获得ReentrantLock锁运行了");
method2();
} finally {
lock.unlock();
}
}
public void method2() {
lock.lock();
try {
System.out.println("方法1里面调用的方法2重入ReentrantLock锁,也正常运行了");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
new ReentrantLockTest().method1();
}
}
上面便是ReentrantLock的重入锁特性,即调用method1()方法时,已经获得了锁,此时内部调用method2()方法时, 由于本身已经具有该锁,所以可以再次获取。
公平锁
CPU在调度线程的时候是在等待队列里随机挑选一个线程,由于这种随机性所以是无法保证线程先到先得的(synchronized控制的锁就是这种非公平锁)。
但这样就会产生饥饿现象,即有些线程(优先级较低的线程)可能永远也无法获取CPU的执行权,优先级高的线程会不断的强制它的资源。
那么如何解决饥饿问题呢,这就需要公平锁了。公平锁可以保证线程按照时间的先后顺序执行,避免饥饿现象的产生。但公平锁的效率比较低,因为要实现顺序执行,需要维护一个有序队列。
ReentrantLock便是一种公平锁,通过在构造方法中传入true就是公平锁,传入false,就是非公平锁。
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}
以下是使用公平锁实现的效果:
public class LockFairTest implements Runnable{
//创建公平锁
private static ReentrantLock lock=new ReentrantLock(true);
public void run() {
while(true){
lock.lock();
try{
System.out.println(Thread.currentThread().getName()+"获得锁");
}finally{
lock.unlock();
}
}
}
public static void main(String[] args) {
LockFairTest lft=new LockFairTest();
Thread th1=new Thread(lft);
Thread th2=new Thread(lft);
th1.start();
th2.start();
}
}
输出结果:
Thread-1获得锁
Thread-0获得锁
Thread-1获得锁
Thread-0获得锁
Thread-1获得锁
Thread-0获得锁
Thread-1获得锁
Thread-0获得锁
Thread-1获得锁
Thread-0获得锁
Thread-1获得锁
Thread-0获得锁
Thread-1获得锁
Thread-0获得锁
Thread-1获得锁
Thread-0获得锁
这是截取的部分执行结果,分析结果可看出两个线程是交替执行的,几乎不会出现同一个线程连续执行多次。
synchronized和ReentrantLock的比较
区别:
- Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
- synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;
- Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
- 通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
- Lock可以提高多个线程进行读操作的效率。
总结:ReentrantLock相比synchronized,增加了一些高级的功能。但也有一定缺陷。 在ReentrantLock类中定义了很多方法,比如:
isFair() //判断锁是否是公平锁
isLocked() //判断锁是否被任何线程获取了
isHeldByCurrentThread() //判断锁是否被当前线程获取了
hasQueuedThreads() //判断是否有线程在等待该锁
两者在锁的相关概念上区别:
1)可中断锁
顾名思义,就是可以响应中断的锁。
在Java中,synchronized就不是可中断锁,而Lock是可中断锁。如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。 lockInterruptibly()的用法体现了Lock的可中断性。
2)公平锁
公平锁即尽量以请求锁的顺序来获取锁。比如同是有多个线程在等待一个锁,当这个锁被释放时,等待时间最久的线程(最先请求的线程)会获得该锁(并不是绝对的,大体上是这种顺序),这种就是公平锁。 非公平锁即无法保证锁的获取是按照请求锁的顺序进行的。这样就可能导致某个或者一些线程永远获取不到锁。 在Java中,synchronized就是非公平锁,它无法保证等待的线程获取锁的顺序。ReentrantLock可以设置成公平锁。
3)读写锁
读写锁将对一个资源(比如文件)的访问分成了2个锁,一个读锁和一个写锁。 正因为有了读写锁,才使得多个线程之间的读操作可以并发进行,不需要同步,而写操作需要同步进行,提高了效率。 ReadWriteLock就是读写锁,它是一个接口,ReentrantReadWriteLock实现了这个接口。 可以通过readLock()获取读锁,通过writeLock()获取写锁。
4)绑定多个条件
一个ReentrantLock对象可以同时绑定多个Condition对象,而在synchronized中,锁对象的wait()和notify()或notifyAll()方法可以实现一个隐含的条件,如果要和多余一个条件关联的时候,就不得不额外地添加一个锁,而ReentrantLock则无须这么做,只需要多次调用new Condition()方法即可。
3、性能比较
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而 当竞争资源非常激烈时(即有大量线程同时竞争),此时ReentrantLock的性能要远远优于synchronized 。所以说,在具体使用时要根据适当情况选择。
在JDK1.5中,synchronized是性能低效的。因为这是一个重量级操作,它对性能最大的影响是阻塞的是实现,挂起线程和恢复线程的操作都需要转入内核态中完成,这些操作给系统的并发性带来了很大的压力。相比之下使用Java提供的ReentrankLock对象,性能更高一些。
到了JDK1.6,发生了变化,对synchronize加入了很多优化措施,有自适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在JDK1.6上synchronize的性能并不比Lock差。官方也表示,他们也更支持synchronize,在未来的版本中还有优化余地,所以还是提倡在synchronized能实现需求的情况下,优先考虑使用synchronized来进行同步。
volatile关键字
Java内存模型
想要理解volatile为什么能确保可见性,就要先理解Java中的内存模型是什么样的。
Java内存模型规定了所有的变量都存储在主内存中。每条线程中还有自己的工作内存,线程的工作内存中保存了被该线程所使用到的变量(这些变量是从主内存中拷贝而来)。线程对变量的所有操作(读取,赋值)都必须在工作内存中进行。不同线程之间也无法直接访问对方工作内存中的变量,线程间变量值的传递均需要通过主内存来完成。
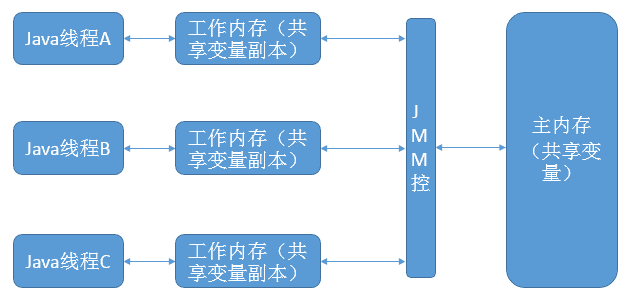
基于此种内存模型,便产生了多线程编程中的数据“脏读”等问题。 举个简单的例子:在java中,执行下面这个语句:
i = 10;
执行线程必须先在自己的工作线程中对变量i所在的缓存行进行赋值操作,然后再写入主存当中。而不是直接将数值10写入主存当中。
比如同时有2个线程执行这段代码,假如初始时i的值为10,那么我们希望两个线程执行完之后i的值变为12。但是事实会是这样吗?
可能存在下面一种情况:初始时,两个线程分别读取i的值存入各自所在的工作内存当中,然后线程1进行加1操作,然后把i的最新值11写入到内存。此时线程2的工作内存当中i的值还是10,进行加1操作之后,i的值为11,然后线程2把i的值写入内存。 最终结果i的值是11,而不是12。这就是著名的缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
那么如何确保共享变量在多线程访问时能够正确输出结果呢?
在解决这个问题之前,我们要先了解并发编程的三大概念:原子性,有序性,可见性。
原子性
1、定义
原子性:即一个操作或者多个操作,要么全部执行,并且执行的过程不会被任何因素打断,要么就都不执行。
2、实例
一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。 试想一下,如果这2个操作不具备原子性,会造成什么样的后果。假如从账户A减去1000元之后,操作突然中止。这样就会导致账户A虽然减去了1000元,但是账户B没有收到这个转过来的1000元。 所以这2个操作必须要具备原子性才能保证不出现一些意外的问题。
同样地反映到并发编程中会出现什么结果呢?
举个最简单的例子,大家想一下假如为一个32位的变量赋值过程不具备原子性的话,会发生什么后果?
i = 9;
假若一个线程执行到这个语句时,我暂且假设为一个32位的变量赋值包括两个过程:为低16位赋值,为高16位赋值。 那么就可能发生一种情况:当将低16位数值写入之后,突然被中断,而此时又有一个线程去读取i的值,那么读取到的就是错误的数据。
3、Java中的原子性
在Java中,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。 上面一句话虽然看起来简单,但是理解起来并不是那么容易。看下面一个例子i: 请分析以下哪些操作是原子性操作:
x = 10; //语句1
y = x; //语句2
x++; //语句3
x = x + 1; //语句4
咋一看,可能会说上面的4个语句中的操作都是原子性操作。其实只有语句1是原子性操作,其他三个语句都不是原子性操作。
- 语句1是直接将数值10赋值给x,也就是说线程执行这个语句的会直接将数值10写入到工作内存中。
- 语句2实际上包含2个操作,它先要去读取x的值,再将x的值写入工作内存,虽然读取x的值以及将x的值写入工作内存,这2个操作都是原子性操作,但是合起来就不是原子性操作了。
- 同样的,x++和 x = x+1包括3个操作:读取x的值,进行加1操作,写入新的值。
所以上面4个语句只有语句1的操作具备原子性。 也就是说,只有简单的读取、赋值(而且必须是将数字赋值给某个变量,变量之间的相互赋值不是原子操作)才是原子操作。
从上面可以看出,Java内存模型只保证了基本读取和赋值是原子性操作,如果要实现更大范围操作的原子性,可以通过synchronized和Lock来实现。由于synchronized和Lock能够保证任一时刻只有一个线程执行该代码块,那么自然就不存在原子性问题了,从而保证了原子性。
可见性
1、定义
可见性是指当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
2、实例
举个简单的例子,看下面这段代码:
//线程1执行的代码
int i = 0;
i = 10;
//线程2执行的代码
j = i;
由上面的分析可知,当线程1执行 i =10这句时,会先把i的初始值加载到工作内存中,然后赋值为10,那么在线程1的工作内存当中i的值变为10了,却没有立即写入到主存当中。 此时线程2执行 j = i,它会先去主存读取i的值并加载到线程2的工作内存当中,注意此时内存当中i的值还是0,那么就会使得j的值为0,而不是10. 这就是可见性问题,线程1对变量i修改了之后,线程2没有立即看到线程1修改的值。
Java中的可见性
对于可见性,Java提供了volatile关键字来保证可见性。
当一个共享变量被volatile修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。 而普通的共享变量不能保证可见性,因为普通共享变量被修改之后,什么时候被写入主存是不确定的,当其他线程去读取时,此时内存中可能还是原来的旧值,因此无法保证可见性。 另外,通过synchronized和Lock也能够保证可见性,synchronized和Lock能保证同一时刻只有一个线程获取锁然后执行同步代码,并且在释放锁之前会将对变量的修改刷新到主存当中。因此可以保证可见性。
有序性
1、定义
有序性:即程序执行的顺序按照代码的先后顺序执行。
2、实例
举个简单的例子,看下面这段代码:
int i = 0;
boolean flag = false;
i = 1; //语句1
flag = true; //语句2
上面代码定义了一个int型变量,定义了一个boolean类型变量,然后分别对两个变量进行赋值操作。从代码顺序上看,语句1是在语句2前面的,那么JVM在真正执行这段代码的时候会保证语句1一定会在语句2前面执行吗?不一定,为什么呢?这里可能会发生指令重排序(Instruction Reorder)。
下面解释一下什么是指令重排序,一般来说,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。
比如上面的代码中,语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。 但是要注意,虽然处理器会对指令进行重排序,但是它会保证程序最终结果会和代码顺序执行结果相同,那么它靠什么保证的呢?再看下面一个例子:
int a = 10; //语句1
int r = 2; //语句2
a = a + 3; //语句3
r = a*a; //语句4
这段代码有4个语句,那么可能的一个执行顺序是: 那么可不可能是这个执行顺序呢: 语句2 语句1 语句4 语句3 不可能,因为处理器在进行重排序时是会考虑指令之间的数据依赖性,如果一个指令Instruction 2必须用到Instruction 1的结果,那么处理器会保证Instruction 1会在Instruction 2之前执行。 虽然重排序不会影响单个线程内程序执行的结果,但是多线程呢?下面看一个例子:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
上面代码中,由于语句1和语句2没有数据依赖性,因此可能会被重排序。假如发生了重排序,在线程1执行过程中先执行语句2,而此是线程2会以为初始化工作已经完成,那么就会跳出while循环,去执行doSomethingwithconfig(context)方法,而此时context并没有被初始化,就会导致程序出错。
从上面可以看出,指令重排序不会影响单个线程的执行,但是会影响到线程并发执行的正确性。 也就是说,要想并发程序正确地执行,必须要保证原子性、可见性以及有序性。只要有一个没有被保证,就有可能会导致程序运行不正确。
Java中的有序性
在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。 在Java里面,可以通过volatile关键字来保证一定的“有序性”。另外可以通过synchronized和Lock来保证有序性,很显然,synchronized和Lock保证每个时刻是有一个线程执行同步代码,相当于是让线程顺序执行同步代码,自然就保证了有序性。
另外,Java内存模型具备一些先天的“有序性”,即不需要通过任何手段就能够得到保证的有序性,这个通常也称为 happens-before 原则。如果两个操作的执行次序无法从happens-before原则推导出来,那么它们就不能保证它们的有序性,虚拟机可以随意地对它们进行重排序。
下面就来具体介绍下happens-before原则(先行发生原则):
- 程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作
- 锁定规则:一个unLock操作先行发生于后面对同一个锁的lock操作
- volatile变量规则:对一个变量的写操作先行发生于后面对这个变量的读操作
- 传递规则:如果操作A先行发生于操作B,而操作B又先行发生于操作C,则可以得出操作A先行发生于操作C
- 线程启动规则:Thread对象的start()方法先行发生于此线程的每个一个动作
- 线程中断规则:对线程interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生
- 线程终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行
- 对象终结规则:一个对象的初始化完成先行发生于他的finalize()方法的开始
这8条规则中,前4条规则是比较重要的,后4条规则都是显而易见的。
下面我们来解释一下前4条规则:
对于程序次序规则来说,就是一段程序代码的执行在单个线程中看起来是有序的。注意,虽然这条规则中提到“书写在前面的操作先行发生于书写在后面的操作”,这个应该是程序看起来执行的顺序是按照代码顺序执行的,但是虚拟机可能会对程序代码进行指令重排序。虽然进行重排序,但是最终执行的结果是与程序顺序执行的结果一致的,它只会对不存在数据依赖性的指令进行重排序。因此,在单个线程中,程序执行看起来是有序执行的,这一点要注意理解。事实上,这个规则是用来保证程序在单线程中执行结果的正确性,但无法保证程序在多线程中执行的正确性。 第二条规则也比较容易理解,也就是说无论在单线程中还是多线程中,同一个锁如果处于被锁定的状态,那么必须先对锁进行了释放操作,后面才能继续进行lock操作。 第三条规则是一条比较重要的规则。直观地解释就是,如果一个线程先去写一个变量,然后一个线程去进行读取,那么写入操作肯定会先行发生于读操作。 第四条规则实际上就是体现happens-before原则具备传递性。
深入理解volatile关键字
volatile保证可见性
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1、 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2、 禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行:
//线程1
boolean stop = false;
while(!stop){
doSomething();
}
//线程2
stop = true;
这段代码是很典型的一段代码,很多人在中断线程时可能都会采用这种标记办法。但是事实上,这段代码会完全运行正确么?即一定会将线程中断么?不一定,也许在大多数时候,这个代码能够把线程中断,但是也有可能会导致无法中断线程(虽然这个可能性很小,但是只要一旦发生这种情况就会造成死循环了)。
下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。 那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
那么在线程2修改stop值时(当然这里包括2个操作,修改线程2工作内存中的值,然后将修改后的值写入内存),会使得线程1的工作内存中缓存变量stop的缓存行无效,然后线程1读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。 那么线程1读取到的就是最新的正确的值。
volatile不能确保原子性
下面看一个例子:
public class Nothing {
private volatile int inc = 0;
private volatile static int count = 10;
private void increase() {
++inc;
}
public static void main(String[] args) {
int loop = 10;
Nothing nothing = new Nothing();
while (loop-- > 0) {
nothing.operation();
}
}
private void operation() {
final Nothing test = new Nothing();
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 1000000; j++) {
test.increase();
}
--count;
}).start();
}
// 保证前面的线程都执行完
while (count > 0) {
}
System.out.println("最后的数据为:" + test.inc);
}
}
运行结果为:
最后的数据为:5919956
最后的数据为:3637231
最后的数据为:2144549
最后的数据为:2403538
最后的数据为:1762639
最后的数据为:2878721
最后的数据为:2658645
最后的数据为:2534078
最后的数据为:2031751
最后的数据为:2924506
大家想一下这段程序的输出结果是多少?也许有些朋友认为是1000000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于1000000的数字。 可能有的朋友就会有疑问,不对啊,上面是对变量inc进行自增操作,由于volatile保证了可见性,那么在每个线程中对inc自增完之后,在其他线程中都能看到修改后的值啊,所以有10个线程分别进行了1000000次操作,那么最终inc的值应该是1000000*10=10000000。
这里面就有一个误区了,volatile关键字能保证可见性没有错,但是上面的程序错在没能保证原子性。 可见性只能保证每次读取的是最新的值,但是volatile没办法保证对变量的操作的原子性。 在前面已经提到过,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现: 假如某个时刻变量inc的值为10,线程1对变量进行自增操作,线程1先读取了变量inc的原始值,然后线程1被阻塞了;
然后线程2对变量进行自增操作,线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓存行无效,也不会导致主存中的值刷新, 所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
然后线程1接着进行加1操作,由于已经读取了inc的值,注意此时在线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。 那么两个线程分别进行了一次自增操作后,inc只增加了1。
根源就在这里,自增操作不是原子性操作,而且volatile也无法保证对变量的任何操作都是原子性的。
解决方案:可以通过synchronized或lock,进行加锁,来保证操作的原子性。也可以通过AtomicInteger。
在java 1.5的java.util.concurrent.atomic包下提供了一些原子操作类,即对基本数据类型的 自增(加1操作),自减(减1操作)、以及加法操作(加一个数),减法操作(减一个数)进行了封装,保证这些操作是原子性操作。atomic是利用CAS来实现原子性操作的(Compare And Swap),CAS实际上是利用处理器提供的CMPXCHG指令实现的,而处理器执行CMPXCHG指令是一个原子性操作。
volatile保证有序性
在前面提到volatile关键字能禁止指令重排序,所以volatile能在一定程度上保证有序性。
volatile关键字禁止指令重排序有两层意思:
1、 当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没有进行;
2、 在进行指令优化时,不能将在对volatile变量的读操作或者写操作的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
可能上面说的比较绕,举个简单的例子:
// x、y为非volatile变量
// flag为volatile变量
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
并且volatile关键字能保证,执行到语句3时,语句1和语句2必定是执行完毕了的,且语句1和语句2的执行结果对语句3、语句4、语句5是可见的。 那么我们回到前面举的一个例子:
//线程1:
context = loadContext(); //语句1
inited = true; //语句2
//线程2:
while(!inited ){
sleep()
}
doSomethingwithconfig(context);
前面举这个例子的时候,提到有可能语句2会在语句1之前执行,那么久可能导致context还没被初始化,而线程2中就使用未初始化的context去进行操作,导致程序出错。 这里如果用volatile关键字对inited变量进行修饰,就不会出现这种问题了,因为当执行到语句2时,必定能保证context已经初始化完毕。
volatile的实现原理
可见性
处理器为了提高处理速度,不直接和内存进行通讯,而是将系统内存的数据独到内部缓存后再进行操作,但操作完后不知什么时候会写到内存。 如果对声明了volatile变量进行写操作时,JVM会向处理器发送一条Lock前缀的指令,将这个变量所在缓存行的数据写会到系统内存。 这一步确保了如果有其他线程对声明了volatile变量进行修改,则立即更新主内存中数据。
但这时候其他处理器的缓存还是旧的,所以在多处理器环境下,为了保证各个处理器缓存一致,每个处理会通过嗅探在总线上传播的数据来检查 自己的缓存是否过期, 当处理器发现自己缓存行对应的内存地址被修改了,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作时,会强制重新从系统内存把数据读到处理器缓存里。 这一步确保了其他线程获得的声明了volatile变量都是从主内存中获取最新的。
有序性
Lock前缀指令实际上相当于一个内存屏障(也成内存栅栏),它确保指令重排序时不会把其后面的指令排到内存屏障之前的位置,也不会把前面的指令排到内存屏障的后面;即在执行到内存屏障这句指令时,在它前面的操作已经全部完成。
volatile的应用场景
synchronized关键字是防止多个线程同时执行一段代码,那么就会很影响程序执行效率,而volatile关键字在某些情况下性能要优于synchronized,但是要注意volatile关键字是无法替代synchronized关键字的,因为volatile关键字无法保证操作的原子性。通常来说,使用volatile必须具备以下2个条件:
1、 对变量的写操作不依赖于当前值
2、 该变量没有包含在具有其他变量的不变式中
下面列举几个Java中使用volatile的几个场景。
①.状态标记量
volatile boolean flag = false;
//线程1
while(!flag){
doSomething();
}
//线程2
public void setFlag() {
flag = true;
}
根据状态标记,终止线程。
②.单例模式中的double check
class Singleton {
private volatile static Singleton instance = null;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null)
instance = new Singleton();
}
}
return instance;
}
}
为什么要使用volatile 修饰instance?
主要在于instance = new Singleton()这句,这并非是一个原子操作,事实上在 JVM 中这句话大概做了下面 3 件事情:
1、 给 instance 分配内存
2、 调用 Singleton 的构造函数来初始化成员变量
3、 将instance对象指向分配的内存空间(执行完这步 instance 就为非 null 了)。
但是在 JVM 的即时编译器中存在指令重排序的优化。也就是说上面的第二步和第三步的顺序是不能保证的,最终的执行顺序可能是 1-2-3 也可能是 1-3-2。如果是后者,则在 3 执行完毕、2 未执行之前,被线程二抢占了,这时 instance 已经是非 null 了(但却没有初始化),所以线程二会直接返回 instance,然后使用,然后顺理成章地报错。
ThreadLocal
public class RunnableTest implements Runnable {
private static final ThreadLocal<Integer> value = new ThreadLocal<>();
@Override
public void run() {
for (int i = 0; i < 3; i++) {
value.set(i);
System.out.println(Thread.currentThread()+" value = "+value.get());
}
}
}
public static void main(String[] args) throws Exception {
for (int i = 0; i < 2; i++) {
Runnable r = new RunnableTest();
Thread t = new Thread(r);
t.setName("thread"+i);
t.start();
}
}
运行结果:
Thread[thread0,5,main] value = 0
Thread[thread1,5,main] value = 0
Thread[thread1,5,main] value = 1
Thread[thread1,5,main] value = 2
Thread[thread0,5,main] value = 1
Thread[thread0,5,main] value = 2
如上的结果可知,调用ThreadLocal的get方法只返回属于当前线程的那个实例。
ThreadLocal的方法介绍
T get() 得到这个线程的当前值,如果首次调用(之前没有set),会调用initialize这个来得到这个值
protected initialize() 应该覆盖这个方法来提供一个初始值,默认情况下,这个方法返回null
void set(T t) 为这个线程设置一个新值
void remove() 删除对应这个线程的值
static <S> ThreadLocal<S> withInitial(Supplier<? extends S> supp) 创建一个线程局部变量,其初始值通过Supplier生成
还有一个ThreadLocalRandom的current()的产生当前线程的Random类的快捷方法。
Java序列化
深入理解 Java 序列化
:notebook: 本文已归档到:「blog」
:keyboard: 本文中的示例代码已归档到:「javacore」
简介
- 序列化(serialize) – 序列化是将对象转换为字节流。
- 反序列化(deserialize) – 反序列化是将字节流转换为对象。
序列化用途
- 序列化可以将对象的字节序列持久化——保存在内存、文件、数据库中。
- 在网络上传送对象的字节序列。
- RMI(远程方法调用)
:bell: 注意:使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
序列化和反序列化
Java 通过对象输入输出流来实现序列化和反序列化:
java.io.ObjectOutputStream 类的 writeObject() 方法可以实现序列化;
java.io.ObjectInputStream 类的 readObject() 方法用于实现反序列化。
序列化和反序列化示例:
public class SerializeDemo01 {
enum Sex {
MALE,
FEMALE
}
static class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name = null;
private Integer age = null;
private Sex sex;
public Person() { }
public Person(String name, Integer age, Sex sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
@Override
public String toString() {
return "Person{" + "name='" + name + '\'' + ", age=" + age + ", sex=" + sex + '}';
}
}
/**
* 序列化
*/
private static void serialize(String filename) throws IOException {
File f = new File(filename); // 定义保存路径
OutputStream out = new FileOutputStream(f); // 文件输出流
ObjectOutputStream oos = new ObjectOutputStream(out); // 对象输出流
oos.writeObject(new Person("Jack", 30, Sex.MALE)); // 保存对象
oos.close();
out.close();
}
/**
* 反序列化
*/
private static void deserialize(String filename) throws IOException, ClassNotFoundException {
File f = new File(filename); // 定义保存路径
InputStream in = new FileInputStream(f); // 文件输入流
ObjectInputStream ois = new ObjectInputStream(in); // 对象输入流
Object obj = ois.readObject(); // 读取对象
ois.close();
in.close();
System.out.println(obj);
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
final String filename = "d:/text.dat";
serialize(filename);
deserialize(filename);
}
}
// Output:
// Person{name='Jack', age=30, sex=MALE}
Serializable 接口
被序列化的类必须属于 Enum、Array 和 Serializable 类型其中的任何一种。
如果不是 Enum、Array 的类,如果需要序列化,必须实现 java.io.Serializable 接口,否则将抛出 NotSerializableException 异常。这是因为:在序列化操作过程中会对类型进行检查,如果不满足序列化类型要求,就会抛出异常。
我们不妨做一个小尝试:将 SerializeDemo01 示例中 Person 类改为如下实现,然后看看运行结果。
public class UnSerializeDemo {
static class Person { // 其他内容略 }
// 其他内容略
}
输出:结果就是出现如下异常信息。
Exception in thread "main" java.io.NotSerializableException:
...
serialVersionUID
请注意 serialVersionUID 字段,你可以在 Java 世界的无数类中看到这个字段。 serialVersionUID 有什么作用,如何使用 serialVersionUID?
serialVersionUID 是 Java 为每个序列化类产生的版本标识。它可以用来保证在反序列时,发送方发送的和接受方接收的是可兼容的对象。如果接收方接收的类的 serialVersionUID 与发送方发送的 serialVersionUID 不一致,会抛出 InvalidClassException。
如果可序列化类没有显式声明 serialVersionUID,则序列化运行时将基于该类的各个方面计算该类的默认 serialVersionUID 值。尽管这样,还是建议在每一个序列化的类中显式指定 serialVersionUID 的值。因为不同的 jdk 编译很可能会生成不同的 serialVersionUID 默认值,从而导致在反序列化时抛出 InvalidClassExceptions 异常。 serialVersionUID 字段必须是 static final long 类型。
我们来举个例子: (1)有一个可序列化类 Person
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
private String address;
// 构造方法、get、set 方法略
}
(2)开发过程中,对 Person 做了修改,增加了一个字段 email,如下:
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name;
private Integer age;
private String address;
private String email;
// 构造方法、get、set 方法略
}
由于这个类和老版本不兼容,我们需要修改版本号: private static final long serialVersionUID = 2L;
再次进行反序列化,则会抛出 InvalidClassException 异常。 综上所述,我们大概可以清楚:serialVersionUID 用于控制序列化版本是否兼容。若我们认为修改的可序列化类是向后兼容的,则不修改 serialVersionUID。
默认序列化机制
如果仅仅只是让某个类实现 Serializable 接口,而没有其它任何处理的话,那么就会使用默认序列化机制。
使用默认机制,在序列化对象时,不仅会序列化当前对象本身,还会对其父类的字段以及该对象引用的其它对象也进行序列化。同样地,这些其它对象引用的另外对象也将被序列化,以此类推。所以,如果一个对象包含的成员变量是容器类对象,而这些容器所含有的元素也是容器类对象,那么这个序列化的过程就会较复杂,开销也较大。
注意:这里的父类和引用对象既然要进行序列化,那么它们当然也要满足序列化要求:被序列化的类必须属于 Enum、Array 和 Serializable 类型其中的任何一种。 非默认序列化机制
在现实应用中,有些时候不能使用默认序列化机制。比如,希望在序列化过程中忽略掉敏感数据,或者简化序列化过程。下面将介绍若干影响序列化的方法。 transient 关键字 当某个字段被声明为 transient 后,默认序列化机制就会忽略该字段。
我们将 SerializeDemo01 示例中的内部类 Person 的 age 字段声明为 transient,如下所示:
public class SerializeDemo02 {
static class Person implements Serializable {
transient private Integer age = null;
// 其他内容略
}
// 其他内容略
}
// Output:
// name: Jack, age: null, sex: MALE
从输出结果可以看出,age 字段没有被序列化。
Externalizable 接口
无论是使用 transient 关键字,还是使用 writeObject() 和 readObject() 方法,其实都是基于 Serializable 接口的序列化。 JDK 中提供了另一个序列化接口–Externalizable。
可序列化类实现 Externalizable 接口之后,基于 Serializable 接口的默认序列化机制就会失效。 我们来基于 SerializeDemo02 再次做一些改动,代码如下:
public class ExternalizeDemo01 {
static class Person implements Externalizable {
transient private Integer age = null;
// 其他内容略
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException { }
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException { }
}
// 其他内容略
}
// Output:
// call Person()
// name: null, age: null, sex: null
从该结果,一方面可以看出 Person 对象中任何一个字段都没有被序列化。另一方面,如果细心的话,还可以发现这此次序列化过程调用了 Person 类的无参构造方法。
Externalizable 继承于 Serializable,它增添了两个方法:writeExternal() 与 readExternal()。这两个方法在序列化和反序列化过程中会被自动调用,以便执行一些特殊操作。当使用该接口时,序列化的细节需要由程序员去完成。如上所示的代码,由于 writeExternal() 与 readExternal() 方法未作任何处理,那么该序列化行为将不会保存/读取任何一个字段。这也就是为什么输出结果中所有字段的值均为空。
另外,若使用 Externalizable 进行序列化,当读取对象时,会调用被序列化类的无参构造方法去创建一个新的对象;然后再将被保存对象的字段的值分别填充到新对象中。这就是为什么在此次序列化过程中 Person 类的无参构造方法会被调用。由于这个原因,实现 Externalizable 接口的类必须要提供一个无参的构造方法,且它的访问权限为 public。 对上述 Person 类作进一步的修改,使其能够对 name 与 age 字段进行序列化,但要忽略掉 gender 字段,如下代码所示:
public class ExternalizeDemo02 {
static class Person implements Externalizable {
transient private Integer age = null;
// 其他内容略
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
@Override
public void writeExternal(ObjectOutput out) throws IOException {
out.writeObject(name);
out.writeInt(age);
}
@Override
public void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {
name = (String) in.readObject();
age = in.readInt();
}
}
// 其他内容略
}
// Output:
// call Person()
// name: Jack, age: 30, sex: null
Externalizable 接口的替代方法
实现 Externalizable 接口可以控制序列化和反序列化的细节。它有一个替代方法:实现 Serializable 接口,并添加 writeObject(ObjectOutputStream out) 与 readObject(ObjectInputStream in) 方法。序列化和反序列化过程中会自动回调这两个方法。 示例如下所示:
public class SerializeDemo03 {
static class Person implements Serializable {
transient private Integer age = null;
// 其他内容略
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
// 其他内容略
}
// 其他内容略
}
// Output:
// name: Jack, age: 30, sex: MALE
在 writeObject() 方法中会先调用 ObjectOutputStream 中的 defaultWriteObject() 方法,该方法会执行默认的序列化机制,如上节所述,此时会忽略掉 age 字段。然后再调用 writeInt() 方法显示地将 age 字段写入到 ObjectOutputStream 中。readObject() 的作用则是针对对象的读取,其原理与 writeObject() 方法相同。
注意:writeObject() 与 readObject() 都是 private 方法,那么它们是如何被调用的呢?毫无疑问,是使用反射。详情可见 ObjectOutputStream 中的 writeSerialData 方法,以及 ObjectInputStream 中的 readSerialData 方法。
readResolve() 方法
当我们使用 Singleton 模式时,应该是期望某个类的实例应该是唯一的,但如果该类是可序列化的,那么情况可能会略有不同。此时对第 2 节使用的 Person 类进行修改,使其实现 Singleton 模式,如下所示:
public class SerializeDemo04 {
enum Sex {
MALE, FEMALE
}
static class Person implements Serializable {
private static final long serialVersionUID = 1L;
private String name = null;
transient private Integer age = null;
private Sex sex;
static final Person instatnce = new Person("Tom", 31, Sex.MALE);
private Person() {
System.out.println("call Person()");
}
private Person(String name, Integer age, Sex sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public static Person getInstance() {
return instatnce;
}
private void writeObject(ObjectOutputStream out) throws IOException {
out.defaultWriteObject();
out.writeInt(age);
}
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
public String toString() {
return "name: " + this.name + ", age: " + this.age + ", sex: " + this.sex;
}
}
/**
* 序列化
*/
private static void serialize(String filename) throws IOException {
File f = new File(filename); // 定义保存路径
OutputStream out = new FileOutputStream(f); // 文件输出流
ObjectOutputStream oos = new ObjectOutputStream(out); // 对象输出流
oos.writeObject(new Person("Jack", 30, Sex.MALE)); // 保存对象
oos.close();
out.close();
}
/**
* 反序列化
*/
private static void deserialize(String filename) throws IOException, ClassNotFoundException {
File f = new File(filename); // 定义保存路径
InputStream in = new FileInputStream(f); // 文件输入流
ObjectInputStream ois = new ObjectInputStream(in); // 对象输入流
Object obj = ois.readObject(); // 读取对象
ois.close();
in.close();
System.out.println(obj);
System.out.println(obj == Person.getInstance());
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
final String filename = "d:/text.dat";
serialize(filename);
deserialize(filename);
}
}
// Output:
// name: Jack, age: null, sex: MALE
// false
值得注意的是,从文件中获取的 Person 对象与 Person 类中的单例对象并不相等。为了能在单例类中仍然保持序列的特性,可以使用 readResolve() 方法。在该方法中直接返回 Person 的单例对象。我们在 SerializeDemo04 示例的基础上添加一个 readObject 方法, 如下所示:
public class SerializeDemo05 {
// 其他内容略
static class Person implements Serializable {
// 添加此方法
private void readObject(ObjectInputStream in) throws IOException, ClassNotFoundException {
in.defaultReadObject();
age = in.readInt();
}
// 其他内容略
}
// 其他内容略
}
// Output:
// name: Tom, age: 31, sex: MALE
序列化工具
Java 官方的序列化存在许多问题,因此,很多人更愿意使用优秀的第三方序列化工具来替代 Java 自身的序列化机制。
Java 官方的序列化主要体现在以下方面:
- Java 官方的序列化性能不高,序列化后的数据相对于一些优秀的序列化的工具,还是要大不少,这大大影响存储和传输的效率。
- Java 官方的序列化一定需要实现 Serializable 接口。
- Java 官方的序列化需要关注 serialVersionUID。
- Java 官方的序列无法跨语言使用。
当然我们还有更加优秀的一些序列化和反序列化的工具,根据不同的使用场景可以自行选择! thrift、protobuf – 适用于对性能敏感,对开发体验要求不高的内部系统。 hessian – 适用于对开发体验敏感,性能有要求的内外部系统。 jackson、gson、fastjson – 适用于对序列化后的数据要求有良好的可读性(转为 json 、xml 形式)。 小结
参考资料:
- Java 编程思想
- JAVA 核心技术(卷 1)
- www.hollischuang.com/archives/11…
- www.codenuclear.com/serializati…
- www.blogjava.net/jiangshachi…
- Java 序列化的高级认识
- agapple.iteye.com/blog/859052
java常用类
Math
转载这里
Java 的 Math 包含了用于执行基本数学运算的属性和方法,如初等指数、对数、平方根和三角函数。 Math 的方法都被定义为 static 形式,通过 Math 类可以在主函数中直接调用。下面是Math的常用方法
public class Demo{
public static void main(String args[]){
/**
*Math.sqrt()//计算平方根
*Math.cbrt()//计算立方根
*Math.pow(a, b)//计算a的b次方
*Math.max( , );//计算最大值
*Math.min( , );//计算最小值
*/
System.out.println(Math.sqrt(16)); //4.0
System.out.println(Math.cbrt(8)); //2.0
System.out.println(Math.pow(3,2)); //9.0
System.out.println(Math.max(2.3,4.5));//4.5
System.out.println(Math.min(2.3,4.5));//2.3
/**
* abs求绝对值
*/
System.out.println(Math.abs(-10.4)); //10.4
System.out.println(Math.abs(10.1)); //10.1
/**
* ceil天花板的意思,就是返回大的值
*/
System.out.println(Math.ceil(-10.1)); //-10.0
System.out.println(Math.ceil(10.7)); //11.0
System.out.println(Math.ceil(-0.7)); //-0.0
System.out.println(Math.ceil(0.0)); //0.0
System.out.println(Math.ceil(-0.0)); //-0.0
System.out.println(Math.ceil(-1.7)); //-1.0
/**
* floor地板的意思,就是返回小的值
*/
System.out.println(Math.floor(-10.1)); //-11.0
System.out.println(Math.floor(10.7)); //10.0
System.out.println(Math.floor(-0.7)); //-1.0
System.out.println(Math.floor(0.0)); //0.0
System.out.println(Math.floor(-0.0)); //-0.0
/**
* random 取得一个大于或者等于0.0小于不等于1.0的随机数
*/
System.out.println(Math.random()); //小于1大于0的double类型的数
System.out.println(Math.random()*2);//大于0小于1的double类型的数
System.out.println(Math.random()*2+1);//大于1小于2的double类型的数
/**
* rint 四舍五入,返回double值
* 注意.5的时候会取偶数 异常的尴尬=。=
*/
System.out.println(Math.rint(10.1)); //10.0
System.out.println(Math.rint(10.7)); //11.0
System.out.println(Math.rint(11.5)); //12.0
System.out.println(Math.rint(10.5)); //10.0
System.out.println(Math.rint(10.51)); //11.0
System.out.println(Math.rint(-10.5)); //-10.0
System.out.println(Math.rint(-11.5)); //-12.0
System.out.println(Math.rint(-10.51)); //-11.0
System.out.println(Math.rint(-10.6)); //-11.0
System.out.println(Math.rint(-10.2)); //-10.0
/**
* round 四舍五入,float时返回int值,double时返回long值
*/
System.out.println(Math.round(10.1)); //10
System.out.println(Math.round(10.7)); //11
System.out.println(Math.round(10.5)); //11
System.out.println(Math.round(10.51)); //11
System.out.println(Math.round(-10.5)); //-10
System.out.println(Math.round(-10.51)); //-11
System.out.println(Math.round(-10.6)); //-11
System.out.println(Math.round(-10.2)); //-10
}
}
Number类
转自这里
大多数时候,在使用java中的数字时,我们使用原始数据类型。但是,Java还在java.lang包中的抽象类Number下提供了各种数字包装子类。Number类下主要有6个子类。这些子类定义了一些在处理数字时经常使用的有用方法。byte, integer, double, short, float, long
为什么要在原始数据上使用Number类对象?
数字类定义的常量(如MIN_VALUE和MAX_VALUE)提供数据类型的上限和下限,非常有用。 Number类对象可以用作期望对象的方法的参数(通常用于处理数字集合)。 类方法可用于将值转换为其他基本类型以及从其他基本类型转换值,用于转换字符串和从字符串转换,以及用于在数字系统(十进制,八进制,十六进制,二进制)之间进行转换。
Number的所有子类通用的方法
xxx xxxValue():这里xxx表示原始数字数据类型(byte,short,int,long,float,double)。此方法用于将此 Number对象的值转换为指定的基本数据类型。
句法 :
byte byteValue()
short shortValue()
int intValue()
long longValue()
float floatValue()
double doubleValue()
参数:
----
返回:
此对象表示的数值
转换为指定类型后
示例:
//Java program to demonstrate xxxValue() method
public class Test
{
public static void main(String[] args)
{
// Creating a Double Class object with value "6.9685"
Double d = new Double("6.9685");
// Converting this Double(Number) object to
// different primitive data types
byte b = d.byteValue();
short s = d.shortValue();
int i = d.intValue();
long l = d.longValue();
float f = d.floatValue();
double d1 = d.doubleValue();
System.out.println("value of d after converting it to byte : " + b);
System.out.println("value of d after converting it to short : " + s);
System.out.println("value of d after converting it to int : " + i);
System.out.println("value of d after converting it to long : " + l);
System.out.println("value of d after converting it to float : " + f);
System.out.println("value of d after converting it to double : " + d1);
}
}
输出:
value of d after converting it to byte : 6
value of d after converting it to short : 6
value of d after converting it to int : 6
value of d after converting it to long : 6
value of d after converting it to float : 6.9685
value of d after converting it to double : 6.9685
注意:转换时,可能会发生精度损失。例如,我们可以看到在从Double对象转换为int数据类型时,小数部分(“.9685”)已被省略。
JAVA的Random类的用法详解
转载这里
Random类主要用来生成随机数,本文详解介绍了Random类的用法,希望能帮到大家。
Random类中实现的随机算法是伪随机,也就是有规则的随机。在进行随机时,随机算法的起源数字称为种子数(seed),在种子数的基础上进行一定的变换,从而产生需要的随机数字。 相同种子数的Random对象,相同次数生成的随机数字是完全相同的。也就是说,两个种子数相同的Random对象,第一次生成的随机数字完全相同,第二次生成的随机数字也完全相同。这点在生成多个随机数字时需要特别注意。
下面介绍一下Random类的使用,以及如何生成指定区间的随机数组以及实现程序中要求的几率。
Random对象的生成
Random类包含两个构造方法,下面依次进行介绍:
public Random()
该构造方法使用一个和当前系统时间对应的相对时间有关的数字作为种子数,然后使用这个种子数构造Random对象。
public Random(long seed)
该构造方法可以通过制定一个种子数进行创建。
Random r = new Random();
Random r1 = new Random(10);
再次强调:种子数只是随机算法的起源数字,和生成的随机数字的区间无关。
Random类中的常用方法
Random类中的方法比较简单,每个方法的功能也很容易理解。需要说明的是,Random类中各方法生成的随机数字都是均匀分布的,也就是说区间内部的数字生成的几率是均等的。下面对这些方法做一下基本的介绍:
a、public boolean nextBoolean()
该方法的作用是生成一个随机的boolean值,生成true和false的值几率相等,也就是都是50%的几率。
b、public double nextDouble()
该方法的作用是生成一个随机的double值,数值介于[0,1.0)之间。
c、public int nextInt()
该方法的作用是生成一个随机的int值,该值介于int的区间,也就是-231到231-1之间。
如果需要生成指定区间的int值,则需要进行一定的数学变换,具体可以参看下面的使用示例中的代码。
d、public int nextInt(int n)
该方法的作用是生成一个随机的int值,该值介于[0,n)的区间,也就是0到n之间的随机int值,包含0而不包含n。
如果想生成指定区间的int值,也需要进行一定的数学变换,具体可以参看下面的使用示例中的代码。
e、public void setSeed(long seed)
该方法的作用是重新设置Random对象中的种子数。设置完种子数以后的Random对象和相同种子数使用new关键字创建出的Random对象相同。
Random类使用示例
使用Random类,一般是生成指定区间的随机数字,下面就一一介绍如何生成对应区间的随机数字。以下生成随机数的代码均使用以下Random对象r进行生成: Random r = new Random();
//生成[0,1.0)区间的小数
double d1 = r.nextDouble();
//生成[0,5.0)区间的小数
double d2 = r.nextDouble() * 5;
//生成[1,2.5)区间的小数
double d3 = r.nextDouble() * 1.5 + 1;
//生成任意整数
int n1 = r.nextInt();
//生成[0,10)区间的整数
int n2 = r.nextInt(10);
n2 = Math.abs(r.nextInt() % 10);
/*以上两行代码均可生成[0,10)区间的整数。
第一种实现使用Random类中的nextInt(int n)方法直接实现。
第二种实现中,首先调用nextInt()方法生成一个任意的int数字,该数字和10取余以后生成的数字区间为(-10,10),然后再对该区间求绝对值,则得到的区间就是[0,10)了。
同理,生成任意[0,n)区间的随机整数,都可以使用如下代码:
*/
int n2 = r.nextInt(n);
n2 = Math.abs(r.nextInt() % n);
//生成[0,10]区间的整数
int n3 = r.nextInt(11);
n3 = Math.abs(r.nextInt() % 11);
//g、生成[-3,15)区间的整数
int n4 = r.nextInt(18) - 3;
n4 = Math.abs(r.nextInt() % 18) - 3;
几率实现
按照一定的几率实现程序逻辑也是随机处理可以解决的一个问题。下面以一个简单的示例演示如何使用随机数字实现几率的逻辑。 在前面的方法介绍中,nextInt(int n)方法中生成的数字是均匀的,也就是说该区间内部的每个数字生成的几率是相同的。那么如果生成一个[0,100)区间的随机整数,则每个数字生成的几率应该是相同的,而且由于该区间中总计有100个整数,所以每个数字的几率都是1%。按照这个理论,可以实现程序中的几率问题。 示例:随机生成一个整数,该整数以55%的几率生成1,以40%的几率生成2,以5%的几率生成3。实现的代码如下:
int n5 = r.nextInt(100);
int m; //结果数字
if(n5 < 55){ //55个数字的区间,55%的几率
m = 1;
}else if(n5 < 95){//[55,95),40个数字的区间,40%的几率
m = 2;
}else{
m = 3;
}
因为每个数字的几率都是1%,则任意55个数字的区间的几率就是55%,为了代码方便书写,这里使用[0,55)区间的所有整数,后续的原理一样。 当然,这里的代码可以简化,因为几率都是5%的倍数,所以只要以5%为基础来控制几率即可,下面是简化的代码实现:
int n6 = r.nextInt(20);
int m1;
if(n6 < 11){
m1 = 1;
}else if(n6 < 19){
m1 = 2;
}else{
m1 = 3;
}
在程序内部,几率的逻辑就可以按照上面的说明进行实现。
其它问题
a、相同种子数Random对象问题
前面介绍过,相同种子数的Random对象,相同次数生成的随机数字是完全相同的,下面是测试的代码:
Random r1 = new Random(10);
Random r2 = new Random(10);
for(int i = 0;i < 2;i++){
System.out.println(r1.nextInt());
System.out.println(r2.nextInt());
}
在该代码中,对象r1和r2使用的种子数都是10,则这两个对象相同次数生成的随机数是完全相同的。 如果想避免出现随机数字相同的情况,则需要注意,无论项目中需要生成多少个随机数字,都只使用一个Random对象即可。
b、关于Math类中的random方法
其实在Math类中也有一个random方法,该random方法的工作是生成一个[0,1.0)区间的随机小数。 通过阅读Math类的源代码可以发现,Math类中的random方法就是直接调用Random类中的nextDouble方法实现的。 只是random方法的调用比较简单,所以很多程序员都习惯使用Math类的random方法来生成随机数字。
System
转载这里
System 类代表系统,系统级的很多属性和控制方法都放置在该类的内部。该类位于 java. lang 包。由于该类的构造方法是 private 的,所以无法创建该类的对象,也就是无法实例化该类。
System 类内部的成员变量和成员方法都是 static 的,所以可以方便地进行调用。 System 类的成员变量 System 类有 3 个静态成员变量,分别是 PrintStream out、InputStream in 和 PrintStream err。
PrintStream out
标准输出流。此流已打开并准备接收输出数据。通常,此流对应于显示器输出或者由主机环境或用户指定的另一个输出目标。 例如,编写一行输出数据的典型方式是
System.out.println(data);
其中,println 方法是属于流类 PrintStream 的方法,而不是 System 中的方法。
InputStream in
标准输入流。此流已打开并准备提供输入数据。通常,此流对应于键盘输入或者由主机环境或用户指定的另一个输入源。
PrintStream err
标准的错误输出流。其语法与 System.out 类似,不需要提供参数就可输出错误信息。也可以用来输出用户指定的其他信息,包括变量的值。 例 1 编写一个 Java 程序,使用本节介绍的 System 类实现从键盘输入字符并显示出来。 具体实现代码如下:
import java.io.IOException;
public class Test06
{
public static void main(String[] args)
{
System.out.println("请输入字符,按回车键结束输入:");
int c;
try
{
c=System.in.read(); //读取输入的字符
while(c!='\r')
{ //判断输入的字符是不是回车
System.out.print((char) c); //输出字符
c=System.in.read();
}
}
catch(IOException e)
{
System.out.println(e.toString());
}
finally
{
System.err.println();
}
}
}
以上代码中,System.in.read() 语句读入一个字符,read() 方法是 InputStream 类拥有的方法。变量 c 必须用 int 类型而不能用 char 类型,否则会因为丢失精度而导致编译失败。
以上的程序如果输入汉字将不能正常输出。如果要正常输出汉字,需要把 System.in 声明为 InputStreamReader 类型的实例,最终在 try 语句块中的代码为
InputStreamReader in=new InputStreamReader(System.in);
c=in.read();
while(c!='\r')
{
System.out.print((char) c);
c=in.read();
}
System 类的成员方法
System 类中提供了一些系统级的操作方法,常用的方法有 arraycopy()、currentTimeMillis()、exit()、gc() 和 getProperty()。
1、 arraycopy() 方法
该方法的作用是数组复制,即从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。该方法的具体定义如下: public static void arraycopy(Object src,int srcPos,Object dest,int destPos,int length) 其中,src 表示源数组,srcPos 表示从源数组中复制的起始位置,dest 表示目标数组,destPos 表示要复制到的目标数组的起始位置,length 表示复制的个数。 例 2 下面的示例代码演示了 arraycopy() 方法的使用:
public class System_arrayCopy
{
public static void main(String[] args)
{
char[] srcArray={'A','B','C','D'};
char[] destArray={'E','F','G','H'};
System.arraycopy(srcArray,1,destArray,1,2);
System.out.println("源数组:");
for(int i=0;i<srcArray.length;i++)
{
System.out.println(srcArray[i]);
}
System.out.println("目标数组:");
for(int j=0;j<destArray.length;j++)
{
System.out.println(destArray[j]);
}
}
}
如上述代码,将数组 srcArray 中,从下标 1 开始的数据复制到数组 destArray 从下标 1 开始的位置,总共复制两个。也就是将 srcArray1 复制给 destArray1,将 srcArray2 复制给 destArray2。这样经过复制之后,数组 srcArray 中的元素不发生变化,而数组 destArray 中的元素将变为 E、B、C、 H,下面为输出结果:
源数组:
A
B
C
D
目标数组:
E
B
C
H
1、 currentTimeMillis() 方法
该方法的作用是返回当前的计算机时间,时间的格式为当前计算机时间与 GMT 时间(格林尼治时间)1970 年 1 月 1 日 0 时 0 分 0 秒所差的毫秒数,例如: long m=System.currentTimeMillis(); 上述语句将获得一个长整型的数字,该数字就是以差值表达的当前时间。
例 3 使用 currentTimeMillis() 方法来显示时间不够直观,但是可以很方便地进行时间计算。例如,计算程序运行需要的时间就可以使用如下的代码:
public class System_currentTimeMillis
{
public static void main(String[] args)
{
long start=System.currentTimeMillis();
for(int i=0;i<100000000;i++)
{
int temp=0;
}
long end=System.currentTimeMillis();
long time=end-start;
System.out.println("程序执行时间"+time+"秒");
}
}
上述代码中的变量 time 的值表示代码中 for 循环执行所需要的毫秒数,使用这种方法可以测试不同算法的程序的执行效率高低,也可以用于后期线程控制时的精确延时实现。
1、 exit() 方法
该方法的作用是终止当前正在运行的 Java 虚拟机,具体的定义格式如下: public static void exit(int status) 其中,status 的值为 0 时表示正常退出,非零时表示异常退出。使用该方法可以在图形界面编程中实现程序的退出功能等。
1、 gc() 方法
该方法的作用是请求系统进行垃圾回收。至于系统是否立刻回收,取决于系统中垃圾回收算法的实现以及系统执行时的情况。定义如下: public static void gc()
1、 getProperty() 方法
该方法的作用是获得系统中属性名为 key 的属性对应的值,具体的定义如下: public static String getProperty(String key)
系统中常见的属性名以及属性的说明如表 1 所示。 表1 系统常见属性
| 属性名 | 属性说明 |
|---|---|
| java. version | Java 运行时琢境版本 |
| java.home | Java 安装目录 |
| os.name | 操作系统的名称 |
| os.version | 操作系统的版本 |
| user.name | 用户的账户名称 |
| user.home | 用户的主目录 |
| user.dir | 用户的当前工作目录 |
例 4 下面的示例演示了 getProperty() 方法的使用。
public class System_getProperty
{
public static void main(String[] args)
{
String jversion=System.getProperty("java.version");
String oName=System.getProperty("os.name");
String user=System.getProperty("user.name");
System.out.println("Java 运行时环境版本:"+jversion);
System.out.println("当前操作系统是:"+oName);
System.out.println("当前用户是:"+user);
}
}
运行该程序,输出的结果如下:
Java 运行时环境版本:1.6.0_26
当前操作系统是:Windows 7
当前用户是:Administrator
提示:使用 getProperty() 方法可以获得很多系统级的参数以及对应的值,这里不再一一举例。
log4j详解
转载详解log4j2(上) – 从基础到实战
转载详解log4j2(下) – Async/MongoDB/Flume Appender 按日志级别区分文件输出
官方教程
uri和url详解
概述
URI是统一资源标识符,由某个协议方案表示的资源的定位标识符;URL是统一资源定位器;URN是统一资源命名。 URL和URN都属于URI。
URI格式
[scheme:][//user:password@]host[:port][/path][?query][#fragment]
如上是URI的具体格式,下面介绍其意义:
scheme::是协议方案,比如http:,https:,file:等,此项可选可不选[//[user:password@]:指定用户名和密码作为从服务器获取资源时必要的登陆信息,此项是可选项host:服务器地址,例如www.runoob.com[:port]:服务器端口号,例如:8080,此项是可选项[/path]:指定服务器上的文件路径来定位特指的资源[?query]:查询字符串,例如?id=123&pas=123[#fragment]:片段标识符