本文是一个开坑文,列出了所有笔者能想到以及接触到的微服务场景下用到的技术栈以及技术选型,将来会详细展开每一个内容
从tomcat服务到微服务的进化史
梦开始的地方
很多人刚入门时候都是从tomcat开始的,下载一个tomcat容器,然后启动startup.sh,在浏览器输入经典的http://localhost:8080,就看到那个画风诡异的汤姆猫了(啊,爷春回)
 web服务早期的模式其实也是如此,一台暴露在公用ip的服务器,接收来自网民的请求。
web服务早期的模式其实也是如此,一台暴露在公用ip的服务器,接收来自网民的请求。 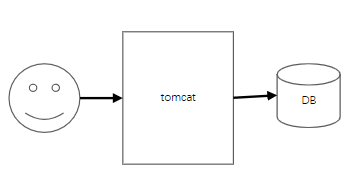
多台服务器–nginx反向代理
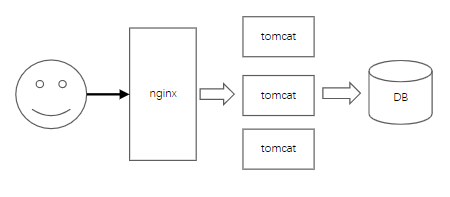
访问量多了以后,一台服务器肯定是承受不住的,所以需要引入nginx反向代理,根据一定的负载均衡算法将流量路由到不同的服务器上,就会变成这样
业务规模的膨胀–服务拆分
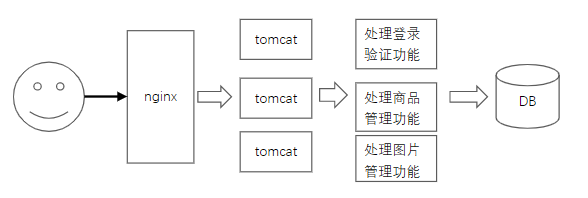
起初,网站的功能很简单的时候,上面的结构就足以处理请求了,但是当业务规模逐渐扩大后会遇到很多问题:
1、 开发人员需要分工 各个业务的功能糅合在一起,代码复杂度升高,负责服务不同模块的开发人员没有必要都在同一个模块上开发
2、 应用服务器的数量增加,导致连接池的连接增加,加大了数据的连接数压力
所以提出了一种将模块的调用当做方法调用一样实现的结构,也就是微服务。不同模块提供一类业务相关功能的子集,然后通过RPC框架来相互调用
RPC框架主要功能及技术选型
总体结构
RPC框架要做的事情大体上就是如下图
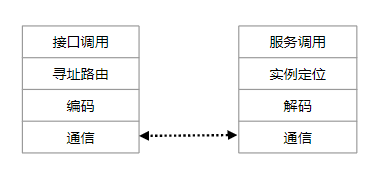
接口调用
通过动态代理技术将一个RPC调用的过程伪装成普通的方法调用,例如代码
int result = calculator.add(a, b);
calculator类的add()方法就可以是通过动态代理生成的一个代理方法,背后执行的是RPC的操作
寻址路由
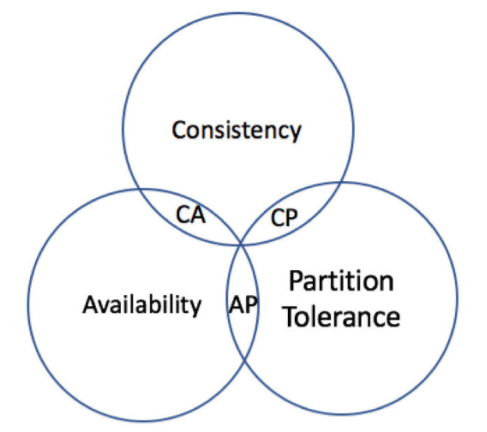
调用方请求提供方时需要实时的知晓提供方的ip和端口,用来发送请求,这里就需要用到ZooKeeper或者Eureka来实现服务发现功能,这里的选型涉及到分布式领域的CAP定理,ZooKeeper是CP,Eureka是AP
编码/解码
即序列化/反序列化,也就是把内存中的对象转为二进制的字节用于在网络中传输,编码解码可选择的方案有:
1、 Java自带序列化
2、 xml
3、 json
4、 protobuf
序列化需要关注的能力包括:
1、 序列化/反序列化的性能
2、 压缩量,压缩量高的序列化可以减小网络的传输,不过大部分机器都是在局域网中,网络可能并不是太大的瓶颈,而且普通请求的参数和返回不是特别大的话区别不是很明显
3、 向后兼容的能力,普通日常开发中最经典的操作就是加字段了,如果每次加字段都会需要通知所有使用方一起升级API版本肯定是无法接受的
4、 跨平台能力
负载均衡能力
RPC框架需要支持负载均衡的能力,常见的负载均衡算法有随机、轮询、权重(动态权重,根据响应时间等参数来进行计算)
- 一般默认都会支持轮询的算法,一种实现方式就是通过在调用方通过维护一个AtomicInteger通过CAS乐观锁累加,实现轮询
- 权重则是更高级的负载均衡算法,静态或者动态采集下游的CPU占用、内存、线程数、相应时间来决定不同下游的优先级
- 基于方法或者接口的路由,因为会存在这样的情况,有两个方法,方法1耗时5s,方法2耗时50ms,在两个方法请求量差不多的情况下,如果在服务器线程数不足的时候,线程池中迟早都会堆满方法1,所以需要对不同方法或者接口路由到不同的下游
流量控制
调用端可以搞一个流控的功能,控制发送请求的流量,可以通过维护一个ConcurrentHashMap,key是接口或者方法,value是正在处理中的请求数量,可以针对不同的方法设置不同的阈值,当正在处理中的请求量到达一定阈值的时候选择快速失败或者队列
网络通信实现的选择
Java的BIO、NIO、AIO的功能对比 可以使用mina或netty这样的框架来通过NIO来处理高并发请求场景,这样也更符合大部分网络服务的请求规律,即高频零碎的低耗时请求
配置文件的统一管理
微服务下同样的模块会部署在n台机器上,这n台机器的配置需要有一个系统来进行统一的管理,可能的实现方案有:
- ZooKeeper 基于ZooKeeper实现配置中心系统
- Eureka
- git
微服务下DB的进化
- 微服务下,不只是服务在进化,db也在经历着从单库单表到分库分表的进化
- 分库分表时如何能保证生成全局唯一的主键
- 分库分表带来的是程序开发的复杂性,解决方案:
- 本地依赖的框架实现分库分表逻辑
- 提供一个DB的中间代理层来屏蔽分库分表的逻辑
网关系统–微服务下web和API接口的统一管理
随着业务的做大,我们会需要一个服务来统一管理微服务下web和API接口