上帝之火
本系列讲述的是开源实时监控告警解决方案Prometheus,这个单词很牛逼。每次我都能联想到带来上帝之火的希腊之神,普罗米修斯。而这个开源的logo也是火,个人挺喜欢这个logo的设计。
本系列着重介绍Prometheus以及如何用它和其周边的生态来搭建一套属于自己的实时监控告警平台。
本系列受众对象为初次接触Prometheus的用户,大神勿喷,偏重于操作和实战,但是重要的概念也会精炼出提及下。系列主要分为以下几块
Prometheus各个概念介绍和搭建,如何抓取数据(本次分享内容)- 如何推送数据至
Prometheus,推送和拉取分别用于什么样的场景 Prometheus数据的结构以及查询语言PromQL的使用- Java应用如何和
Prometheus集成,如何启用服务发现,如果自定义业务指标 Prometheus如何和Grafana可视化套件进行集成和设置告警- 教你如何手写一个集成了监控Dubbo各个指标的java套件
- 实际案例分享,如何做各个业务端和系统端的监控大盘
Prometheus以及时序数据库的基本概念
Prometheus现在在Github有3w多的star,基本上过万星的开源工具,可以认为是社区里绝对的主流,社区也相当活跃,可以有大量的经验可以借鉴。在企业级系统中,可以放心的使用。
Prometheus 是由 SoundCloud开发的开源监控报警系统和时序列数据库。从字面上理解,Prometheus由两个部分组成,一个是监控报警系统,另一个是自带的时序数据库(TSDB)。
关于时序数据库(TSDB)这里要说下,我们可以简单的理解为一个优化后用来处理时间序列数据的数据库,并且数据中的数组是由时间进行索引的。相比于传统的结构化数据库主要有几个好处:
- 时间序列数据专注于海量数据的快速摄取。时序数据库视数据的每一次变化为一条新的数据,从而可以去衡量变化:分析过去的变化,监测现在的变化,以及预测未来将如何变化,传统结构化数据在数据量小的时候能做到,在数据量大的时候就需要花费大量的成本。
- 高精度数据保存时间较短,中等或更低精度的摘要数据保留时间较长。对于实时监控来说,不一定需要每一个精准的数据,而是固定时间段时间数据的摘要。这对于结构化数据库来说就意味着要进行筛选,在保证大量的写入同时还要进行帅选,这是一个超出结构化数据库设计来处理的工作量。
- 数据库本身必须连续计算来自高精度数据的摘要以进行长期存储。这些计算既包括一些简单的聚合,同时也有一些复杂计算。传统数据库无法承受那么大量的计算。因为必须去实时统计这些聚合和复杂运算。
开始搭建Prometheus
在Prometheue官网Download标签页进行下载,这里以linux版本为例:

下载好之后,解压,运行
nohup /data/prometheus/prometheus --web.listen-address=0.0.0.0:9090 --config.file=/data/prometheus/prometheus.yml --web.enable-lifecycle --storage.tsdb.path=/data/prometheus/data --storage.tsdb.retention.time=15d &
这样,就简单的搭建起来Prometheus服务端了。这时候,我们可以在web上访问
就可以访问到管理页面
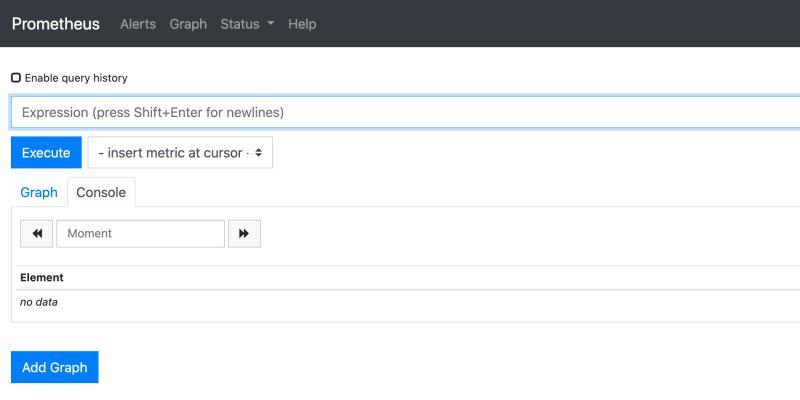
界面上几个标签说明下:
Alert:用来配置告警规则。之后我们会用Grafana自身的告警界面配置来代替这个。
Graph:用来运行PromQL语句的一个控制台,并且可以把运行出来的语句用用图形化进行展示,此块我们后面章节会介绍到。
Status:包含系统信息,系统状态,配置信息,目标节点的状态,服务发现状态等元信息的查看。
Prometheus整体架构以及生态
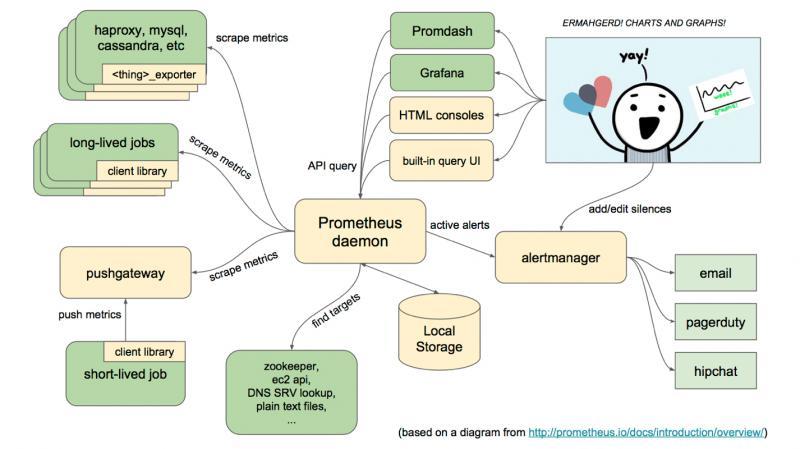
这张图是官方的整体架构图。米黄色部分是Prometheus自己的组件,绿色的为第三方的中间件和应用。
简单介绍下整个Prometheus的生态架构:
1、 Prometheus获取数据的方式只有一种,就是scrape,也称作pull,意为拉取。Prometheus每隔一段时间会从目标(target)这里以Http协议拉取指标(metrics),这些目标可以是应用,也可以是代理,缓存中间件,数据库等等一些中间件。
2、 拉取出来的数据Prometheus会存到自己的TSDB数据库。自己的WebUI控制台以及Grafana可以对其数据进行时间范围内的不断查询,绘制成实时图表工展现。
3、 Prometheus 支持例如zookeeper,consul之类的服务发现中间件,用以对目标(target)的自动发现。而不用一个个去配置target了。
4、 alertManager组件支持自定义告警规则,告警渠道也支持很多种
拉取数据
Prometheus主要是通过拉取的方式获取数据,说简单点,就是每隔固定时间去访问配置的target,target就是一个获取数据的url。
现在我们就来模拟一个数据源,并让prometheus去拉取。
新建一个springboot的web项目,pom依赖加上
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
application.properties里加上
server.port=8080
anagement.endpoints.web.exposure.include=*
启动完毕后,我们就可以在页面上访问如下地址:
得到如下数据:
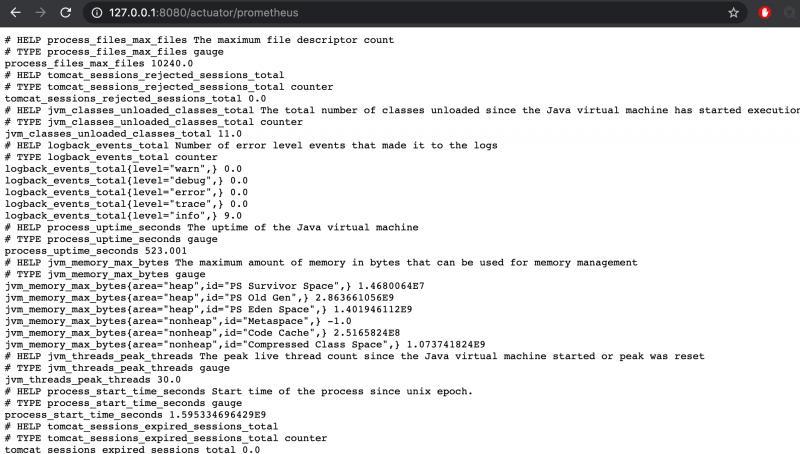
关于actuator如何监控应用指标以及自定义指标我会在之后的系列里单独分析,这里只要理解成我们启动了一个服务,提供了一个url能列出一些kv形式的指标就行了。
例如jvm_memory_max_bytes{area="heap",id="PS Old Gen",} 2.863661056E9这个指标,前面是key,后面为value。
其中key上又分key name和key labels,key name就是``jvm_memory_max_bytes,key labels有2个。
这个指标提供了jvm的最大内存,其中area为heap,表明这是堆内存区域,id为PS Old Gen,表明这是老年代。综合起来看,这个指标就是jvm中老年代的最大值。数值类型是byte,换算下来大概是286M左右。
我们有指标的数据源后,再在prometheus 的根目录下编辑prometheus.yml文件,添加如下配置:
- job_name: 'test'
scrape_interval: 5s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['localhost:8080']
labels:
instance: demo
这个配置表示:prometheue每隔5秒钟从http://localhost:8080/actuator/prometheus这个url拉取指标,并且为每个指标添加instance这个标签。
添加完毕后,重启prometheus。进入web页面中的targets页面。如果前面步骤没问题的话,会看到:

状态为UP表明prometheue已经成功获取到了这个target 的数据。
在查询页面上输入刚才那个指标的key:
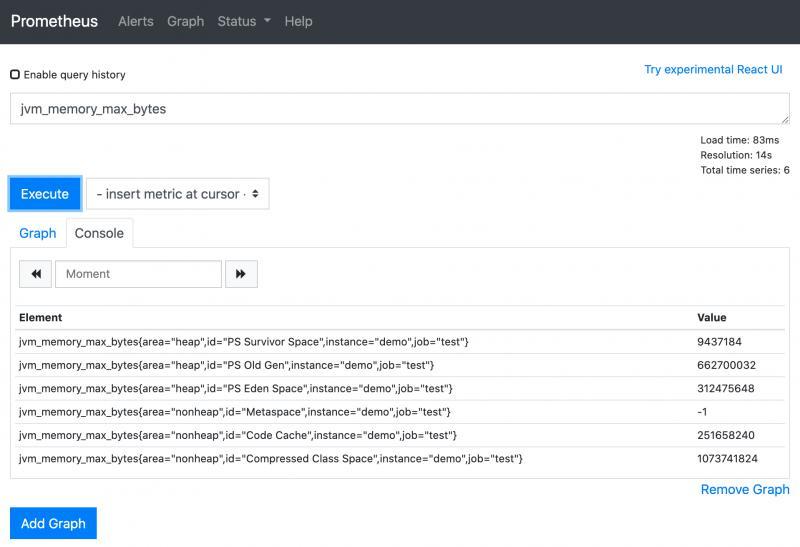
这里每个value都是prometheus最近一次抓取的数据。你每执行一次,数据都会变。
这里为什么会有多条数据呢,是因为每个指标他们的标签不一样。完全一样的标签会被归为一种指标。
点Graph这标签可以看到在时间序列下,某个指标的变化趋势
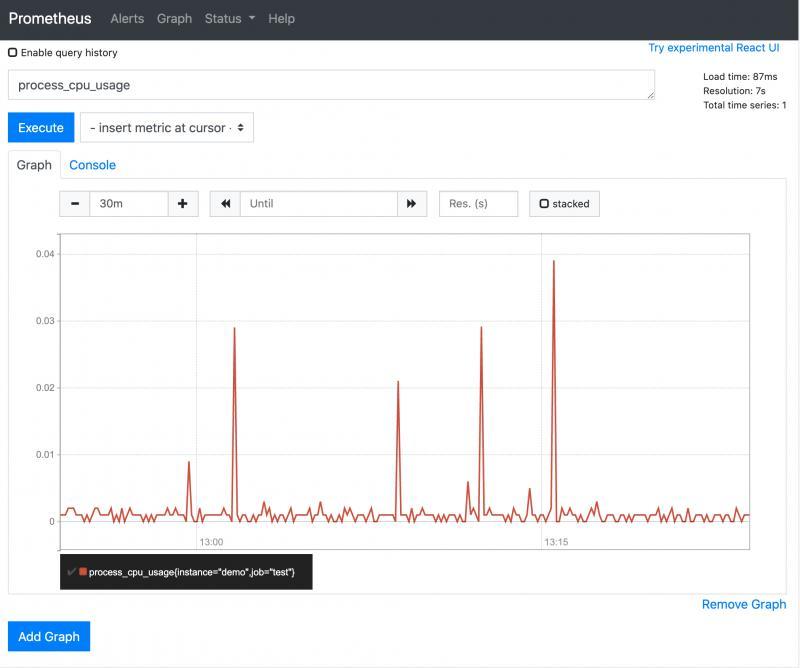
上图展示了系统cpu指标的变化图。
最后
如今微服务盛行,小规模的企业的微服务节点也快上百了,Prometheus生态能够用最小的代价使所有的数据实时可视化。这对于开发和运维来说,意义在于,所有的数据不再是黑盒了,至少我个人觉得所有的数据能够被观测和分析,是具有安全感的。
这个系列旨在利用实战操作教你一步步搭建自己系统和业务监控大盘。后面会继续更新。下一个章节将分析:搭建pushgateway去push数据到prometheus,以及2种不同的数据获取方式分别用于什么样的场景。
联系作者
欢迎微信公众号关注 「元人部落」
关注后回复“资料”免费获取50G的技术资料,包括整套企业级微服务课程和秒杀课程
