
️1. 介 绍
在记录日志中, 可能你知道 logging, 或者是使用你自己定义的方式记录到文件内, 但是我介绍的这款记录器可能会达到你的记录要求 — eliot
- 结构化输出日志信息,能够对输出一目了然
- 可以用于解析和过滤日志
- 不仅记录简单信息,还可以追踪程序的执行过程
- 性能非常好,使用非堵塞IO
- 可以结合 Logstash / Elasticsearch 使用
2. 安 装
python3 -m pip install eliot eliot-tree
3. 使 用
在 medusa.py 中键入以下内容:
#!/usr/bin/env python
# _*_ Coding: UTF-8 _*_
import time
from eliot import *
to_file(open('./medusa_log.log', 'w', encoding='UTF-8'))
def __worker(i):
""" 真正执行任务工作的函数 """
with start_action(action_type="__worker", urls=i):
time.sleep(4)
print(i)
def medusa(_: (list, tuple)):
""" 定义一个执行任务工作的函数 """
with start_action(action_type="worker", urls=_):
for i in _:
__worker(i)
if __name__ == '__main__':
bui = 1, 'MedusaSorcerer'
medusa(bui)
解析代码:
- 代码中我们定义了一个
bui的元组对象, 这是交给工作函数的参数 - 工作函数
medusa将接收的参数进行遍历, 将每个遍历的元素交付至__worker函数 to_file函数声明日志内容保存的方式是文件, 并指定了文件对象
4. 运 行
再运行 python3 medusa.py 的时候会在同一目录下创建 medusa_log.log 文件, 打开并查阅内容:
{"urls": [1, "MedusaSorcerer"], "action_status": "started", "timestamp": 1595313658.5557268, "task_uuid": "58b309ff-ab22-40bb-89c6-bfd951ce4f4a", "action_type": "worker", "task_level": [1]}
{"urls": 1, "action_status": "started", "timestamp": 1595313658.556727, "task_uuid": "58b309ff-ab22-40bb-89c6-bfd951ce4f4a", "action_type": "__worker", "task_level": [2, 1]}
{"action_status": "succeeded", "timestamp": 1595313662.562169, "task_uuid": "58b309ff-ab22-40bb-89c6-bfd951ce4f4a", "action_type": "__worker", "task_level": [2, 2]}
{"urls": "MedusaSorcerer", "action_status": "started", "timestamp": 1595313662.562169, "task_uuid": "58b309ff-ab22-40bb-89c6-bfd951ce4f4a", "action_type": "__worker", "task_level": [3, 1]}
{"action_status": "succeeded", "timestamp": 1595313666.5714984, "task_uuid": "58b309ff-ab22-40bb-89c6-bfd951ce4f4a", "action_type": "__worker", "task_level": [3, 2]}
{"action_status": "succeeded", "timestamp": 1595313666.5714984, "task_uuid": "58b309ff-ab22-40bb-89c6-bfd951ce4f4a", "action_type": "worker", "task_level": [4]}
- 第一行:执行
medusa()的时候创建了任务日志 - 第二行:记录了将数组遍历代入
__worker()的时候创建的任务日志 - 第三行:记录了第一个代入
__worker()的数据执行完成后的结束日志 - 第四行:记录了第二个遍历代入
__worker()的任务日志 - 第五行:记录了第二个代入
__worker()的数据执行完成后的结束日志 - 第六行:记录了
medusa任务执行完成后的任务日志
接下来怎么实现过滤呢?
5. 过 滤
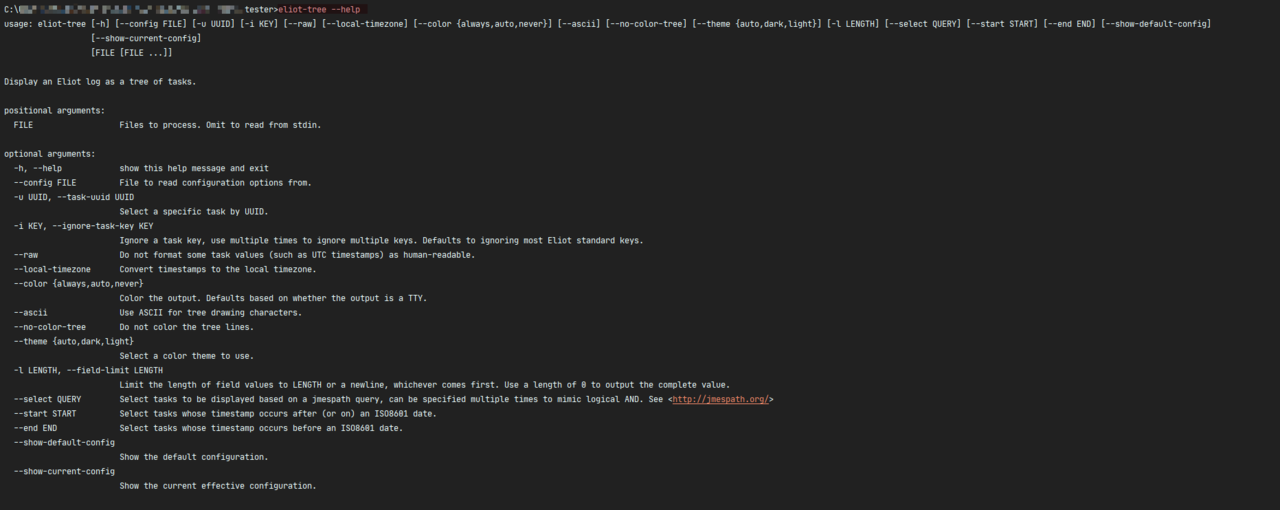
使用 eliot-tree --help 查阅相关帮助信息:
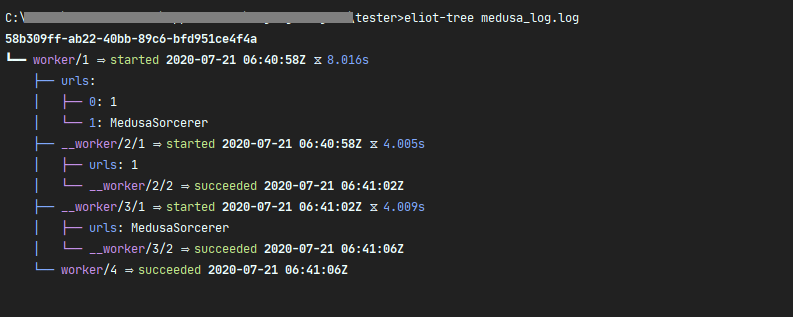
格式化输出日志内容:
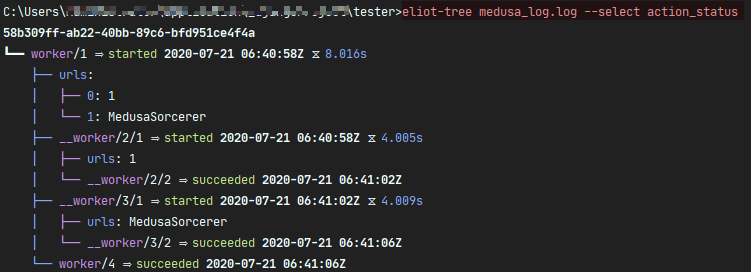
检索有包含 action_status Key 的日志内容:
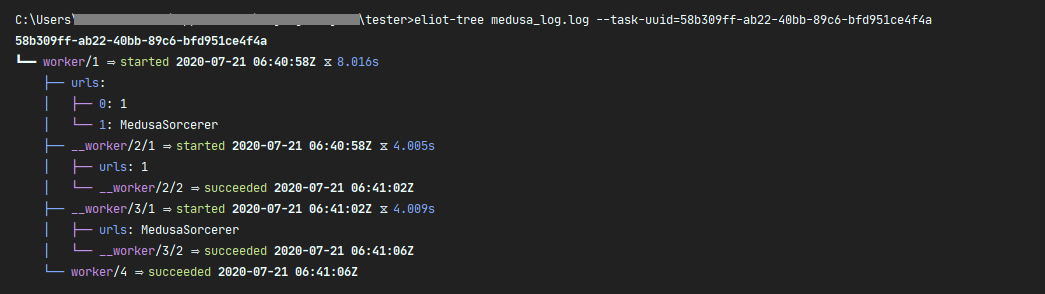
检索指定的任务 UUID:
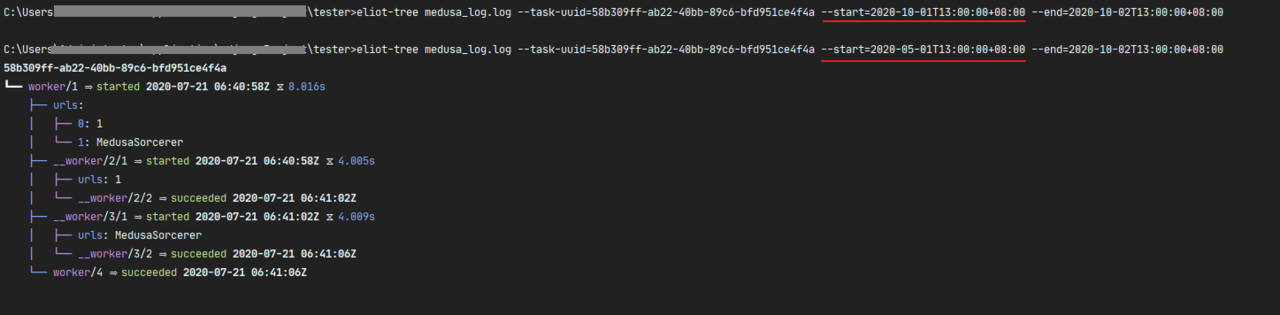
检索时间区间的任务:
需要注意的是时间的格式需要符合 ISO8601 标准。
你的世界是一个怎样的世界?