在写爬虫之前,还是需要了解一些爬虫的基础知识,如 HTTP 原理、网页的基础知识、爬虫的基本原理、Cookies 基本原理等。
网络蜘蛛是一个很形象的名字。如果把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过 网页的链接地址来寻找网页,从 网站某一个页面开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接 地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。
爬虫流程:
1、设置采集目标网站(主页)并获取网站数据。
2、当服务器无法访问时,按照指定的重试次数尝试重新下载页面。
3、在需要的时候设置用户代理或隐藏真实IP,否则可能无法访问页面。
4、对获取的页面进行必要的解码操作然后抓取出需要的信息。
5、在获取的页面中通过某种方式(如正则表达式)抽取出页面中的链接信息。
6、对链接进行进一步的处理(获取页面并重复上面的动作)。
7、 将有用的信息进行持久化以备后续的处理。
爬虫的解析与储存
1、解析
对于解析来说,对于 HTML 类型的页面来说,常用的解析方法其实无非那么几种,正则、XPath、CSS Selector,另外对于某些接口,常见的可能就是 JSON、XML 类型,使用对应的库进行处理即可。

这些规则和解析方法其实写起来是很繁琐的,如果我们要爬上万个网站,如果每个网站都去写对应的规则,那么不就太累了吗?所以智能解析便是一个需求。
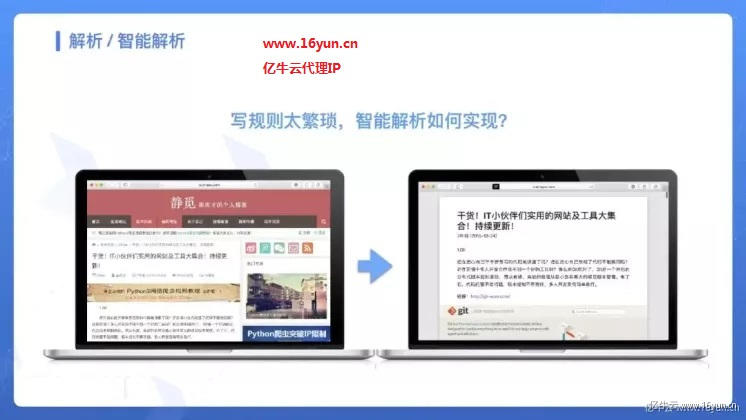
智能解析意思就是说,如果能提供一个页面,算法可以自动来提取页面的标题、正文、日期等内容,同时把无用的信息给刨除,例如上图,这是 Safari 中自带的阅读模式自动解析的结果。
对于智能解析,下面分为四个方法进行了划分:
- readability 算法,这个算法定义了不同区块的不同标注集合,通过权重计算来得到最可能的区块位置。
- 疏密度判断,计算单位个数区块内的平均文本内容长度,根据疏密程度来大致区分。
- Scrapyly 自学习,是 Scrapy 开发的组件,指定⻚页⾯面和提取结果样例例,其可⾃自学习提取规则,提取其他同类⻚页⾯面。
- 深度学习,使⽤用深度学习来对解析位置进⾏行行有监督学习,需要⼤大量量标注数据。
如果能够容忍一定的错误率,可以使用智能解析来大大节省时间。

目前这部分内容我也还在探索中,准确率有待继续提高。
2、存储
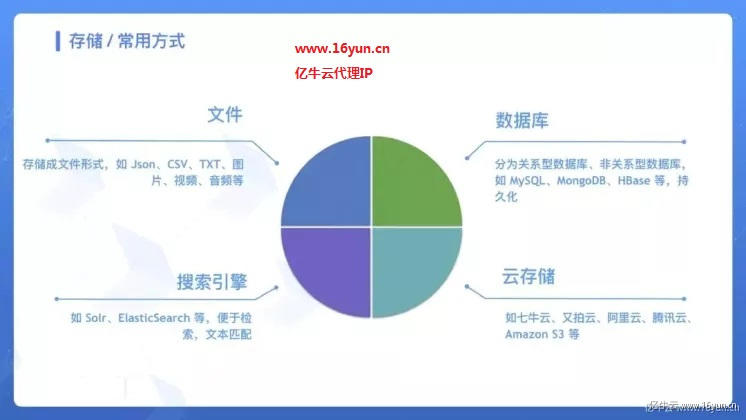
存储,即选用合适的存储媒介来存储爬取到的结果,这里还是分为四种存储方式来进行介绍。
- 文件,如 JSON、CSV、TXT、图⽚、视频、⾳频等,常用的一些库有 csv、xlwt、json、pandas、pickle、python-docx 等。
- 数据库,分为关系型数据库、非关系型数据库,如 MySQL、MongoDB、HBase 等,常用的库有 pymysql、pymssql、redis-py、pymongo、py2neo、thrift。
- 搜索引擎,如 Solr、ElasticSearch 等,便于检索和实现⽂本匹配,常用的库有 elasticsearch、pysolr 等。
- 云存储,某些媒体文件可以存到如七⽜牛云、又拍云、阿里云、腾讯云、Amazon S3 等,常用的库有 qiniu、upyun、boto、azure-storage、google-cloud-storage 等。

这部分的关键在于和实际业务相结合,看看选用哪种方式更可以应对业务需求。
爬虫注意事项:
1、处理相对连接,有时我们从网页中获取的连接不是一个完整的绝对连接,而是一个相对连接,这种情况下将其URL后缀进行拼接( urllib.parse中的urljoin()函数可以完成此项操作 )
2、设置代理服务。有些网站会限制访问区域, 例如美国的Netflix屏蔽了很多国家的访问),有些爬虫需要隐藏自己的身份,在这 种情况下可以设置使用代理服务器,亿牛云爬虫代理一般稳定性和可用性都更好,可以通过urllib.request中的ProxyHandler来为请求设置代理。
3、限制下载速度, 如果我们的爬虫获取网页的速度过快,可能就会面临被封禁或者产生“损害动产”的风险(这个可能会导致吃官司且败诉),可以在两次下载之间添加延时从而对爬虫进行限速。
4、避免爬虫陷阱。 有些网站会动态生成页面内容,这会导致产生无限多的页面(例如在线万年历通常会有无穷无尽的链接)。可以通过记录到达当前页面经过了多少个链接(链接深度)来解决该问题,当达到事先设定的最大深度时爬虫就不再像队列中添加该网页中的链接了。