MySQL 性能优化
1. 灵魂拷问
1、 MySQL的索引在执行过程中是如何被使用的?
2、 MySQL的表数据和索引在底层是如何被使用的?
3、 索引覆盖是什么?索引覆盖如何优化检索性能
4、 组合索引和单列所有哪个更好?
5、 聚集索引和非聚集索引存储方式有什么不同
6、 B+ Tree和B Tree的区别
2.1 MySQL架构
2.1.1 结构图
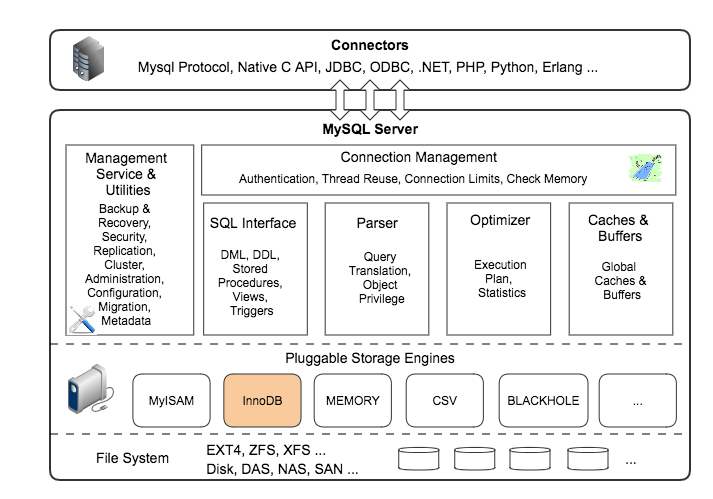
第一层负责连接管理、授权认证、安全等
第二层负责解析查询(编译SQL),并对其进行优化(如调整表的读取顺序,选择合适的索引等)。对于SELECT语句,在解析查询前,服务器会先检查查询缓存,如果能在其中找到对应的查询结果,则无需再进行查询解析、优化等过程,直接返回查询结果。存储过程、触发器、视图等都在这一层实现。
第三层是存储引擎,存储引擎负责在MySQL中存储数据、提取数据、开启一个事务等等
2.1.2Optimizer优化器
语法解析和查询重写之后,MySQL会根据语法树和数据的统计信息对SQL进行优化,包括决定表的读取顺序、选择合适的索引等,最终生成SQL的具体执行步骤
2.1.3 Pluggable Storage Engines存储引擎
| 存储引擎 | 优点 | 缺点 |
|---|---|---|
| InnoDB | 5.5版本后MySQL默认数据库,支持事务,比MyISAM处理速度稍慢 | 非常复杂,性能较一些简单的引擎要差一点儿。空间占用比较多。 |
| MyISAM | 高速引擎,拥有极高的插入,查询速度 | 不支持事务,不支持行锁、崩溃后数据不容易修复 |
| Archive | 将数据压缩后存储,非常适合存储大量的独立的,作为历史记录的数据 | 只能进行插入和查询操作,非事务型 |
| CSV | 是基于CSV格式文件存储数据(应用于跨平台数据交换) | |
| Memory | 内存存储引擎,拥有极高的插入,更新和查询效率 | 占用和数据量成正比的内存空间,只在内存上保存数据,意味着数据可能会丢失,并发能力低下。不支持BLOB或TEXT类型的列 |
| Falcon | 一种新的存储引擎,支持事务处理,传言可能是InnoDB的替代者 |
最常用的是InnoDB和MyISAM,InnoDB和MyISAM存储引擎区别
| 类别 | InnoDB | MyISAM |
|---|---|---|
| 存储文件 | .frm 表定义文件 .idb 数据文件和索引文件 |
.frm 表定义文件 .myd 数据文件 .myi 索引文件 |
| 锁 | 表锁、行锁 | 表锁 |
| 事务 | 支持 | 不支持 |
| CRUD | 读、写 | 读多 |
| count | 扫表 | 专门存储的地方 |
| 索引结构 | B+ Tree | B+ Tree |

2.1.4 MySQL物理文件
1. 日志文件(顺序IO)
MySQL通过日志记录了数据库操作信息和错误信息。常用的日志文件包括错误日志、二进制日志、查询日志、慢查询 日志和事务Redo 日志、中继日志等
- 错误日志(errorlog) **默认是开启的,**而且从5.5.7以后无法关闭错误日志,错误日志记录了运行过程中遇到的所有严重的错误信息,以及MySQL每次启动和关闭的详细信息。
- 二进制日志(bin log) **默认是关闭的。**binlog记录了数据库所有的ddl语句和dml语句,但不包括select语句内容,语句以事件的形式保存,描述了数据 的变更顺序,binlog还包括了每个更新语句的执行时间信息。如果是DDL语句,则直接记录到binlog日志,而DML语 句,必须通过事务提交才能记录到binlog日志中。 binlog主要用于实现mysql主从复制、数据备份、数据恢复。
- 通用查询日志(general query log) 默认情况下通用查询日志是关闭的
- 慢查询日志(slow query log) 默认是关闭的。
- 重做日志(redo log) 作用:确保事务的持久性。防止在发生故障的时间点,尚有脏页未写入磁盘,在重启mysql服务的时候,根据redo log进行重做,从而达到事务的持久性这一特性。
- 回滚日志(undo log)
保存了事务发生之前的数据的一个版本,可以用于回滚,同时可以提供多版本并发控制下的读(MVCC),也即非锁定读
-
中继日志(relay log)
是在主从复制环境中产生的日志。主要作用是为了从机可以从中继日志中获取到主机同步过来的SQL语句,然后执行到从机中。
2. 数据文件(随机IO)
- InnoDB数据文件 .frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息 .ibd:使用独享表空间存储表数据和索引信息,一张表对应一个ibd文件。 ibdata文件:使用共享表空间存储表数据和索引信息,所有表共同使用一个或者多个ibdata文件
- MyIsam数据文件 .frm文件:主要存放与表相关的数据信息,主要包括表结构的定义信息 .myd文件:主要用来存储表数据信息。 .myi文件:主要用来存储表数据文件中任何索引的数据树。
3. 顺序IO和随机IO
- 顺序I/O一般只需扫描一次数据、所以、缓存对它用处不大
- 顺序I/O比随机I/O快
- 随机I/O通常只要查找特定的行、但I/O的粒度是页级的、其中大部分是浪费的,而顺序I/O所读取的数据、通常发生在想要的数据块上的所有行更加符合成本效益
2.1.5 MySQL执行流程
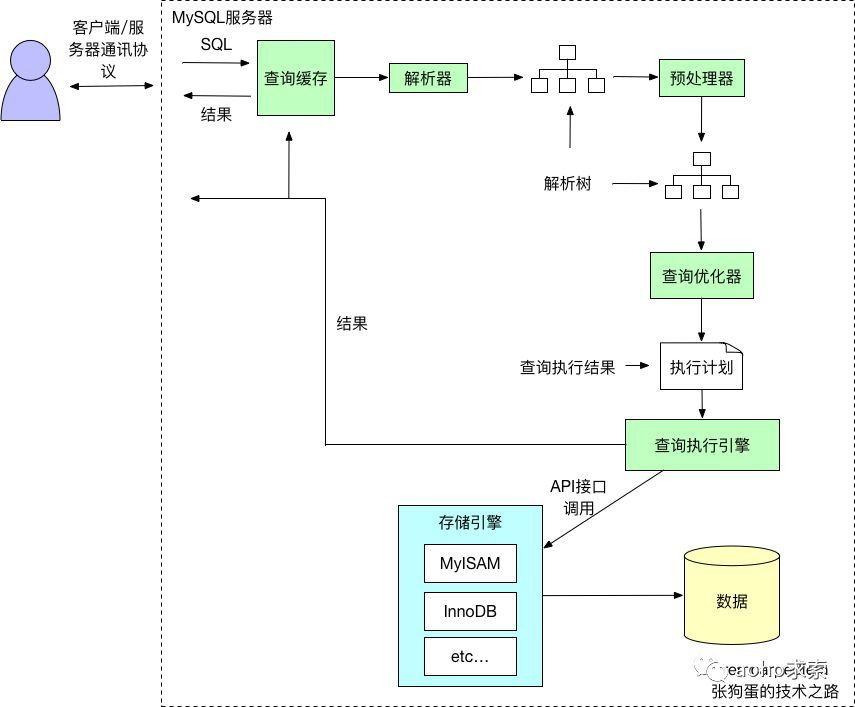
1、 客户端发送一条查询给服务器;
2、 服务器通过权限检查之后,先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
3、 服务器端进行SQL解析、预处理,再由优化器根据该SQL所涉及到的数据表的统计信息进行计算,生成对应的执行计划;
4、 MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
5、 将结果返回给客户端。
> SQL执行的最大瓶颈在于磁盘的IO,即数据的读取 ;不同SQL的写法,会造成不同的执行计划的执行,而不同的执行计划在IO的上面临完全不一样的数量级,从而造成性能的差距; 所以,我们说,优化SQL,其实就是让查询优化器根据程序猿的计划选择匹配的执行计划,来减少查询中产生的IO;
2.1.6 SQL解析顺序
SELECT DISTINCT
< select_list >
FROM
< left_table > < join_type >
JOIN < right_table > ON < join_condition >
WHERE
< where_condition >
GROUP BY
< group_by_list >
HAVING
< having_condition >
ORDER BY
< order_by_condition >
LIMIT < limit_number >
执行顺序:
FROM <left_table>
ON <join_condition>
<join_type> JOIN <right_table>
WHERE <where_condition>
GROUP BY <group_by_list>
HAVING <having_condition>
SELECT
DISTINCT <select_list>
ORDER BY <order_by_condition>
LIMIT <limit_number>
2.2 MySQL索引
2.2.1 索引是什么
1、 高效获取数据的数据结构,相当于书的目录
2、 使用B+树结构(多路搜索树,并不一定是二叉的)
3、 索引是存储在磁盘文件中的(可能单独的索引文件中,也可能和数据一起存储在数据文件中)
2.2.2 索引的优势和劣势
优势:
1、 可以提高数据检索的效率,降低数据库的IO成本
2、 通过索引对数据进行排序,降低数据排序的成本,降低CPU消耗
劣势:
1、 空间换时间,索引会占据磁盘空间
2、 能提高效率,但是降低更新表的效率
2.2.3 常用索引分类
1、 单列索引
- 普通索引:MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值,纯粹为了查询数 据更快一点。
- 唯一索引:索引列中的值必须是唯一的,但是允许为空值。
- 主键索引:是一种特殊的唯一索引,不允许有空值
1、 组合索引
- 在表中的多个字段组合上创建的一个索引
- 组合索引的使用,需要遵循最左前缀原则(最左匹配原则)。
- 一般情况下,建议使用组合索引代替单列索引(主键索引除外)。
2.2.4 索引的存储结构
1、 索引是在存储引擎中实现的。
MyISAM和InnoDB存储引擎:只支持BTREE索引, 也就是说默认使用BTREE,不能够更换
2.2.5 B树和B+树
1、 数据结构在线演示
[www.cs.usfca.edu/~galles/vis…][www.cs.usfca.edu_galles_vis]
2、 B树结构
B树是为了磁盘或其它存储设备而设计的一种多叉平衡查找树(下面你会看到,相对于二叉,B树每个内结点有多个分支,即多叉)
![94\_5.png][94_5.png]
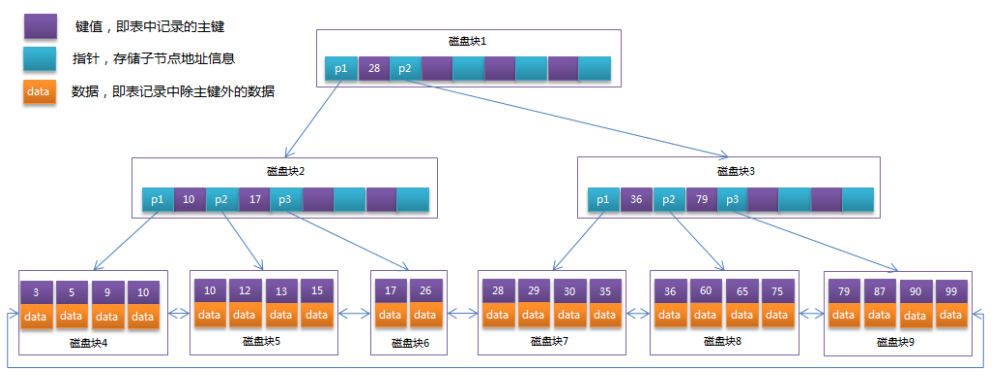
- B树的高度一般都是在2-4这个高度,树的高度直接决定IO读写的次数以及查询时间复杂度(log(n))。
- B树三层可以存储bigint类型的主键10亿条
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针 类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为 是估值,为方便计算,这里的K取值为〖10〗^3)。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
- 如果是三层树结构—支撑的数据可以达到20G,如果是四层树结构—支撑的数据可以达到几十T
1、 B树和B+树的区别
- B树是非叶子节点和叶子节点都会存储数据。
- B+树只有叶子节点才会存储数据,而且存储的数据都是在一行上,而且这些数据都是有指针指向的,是有顺链表
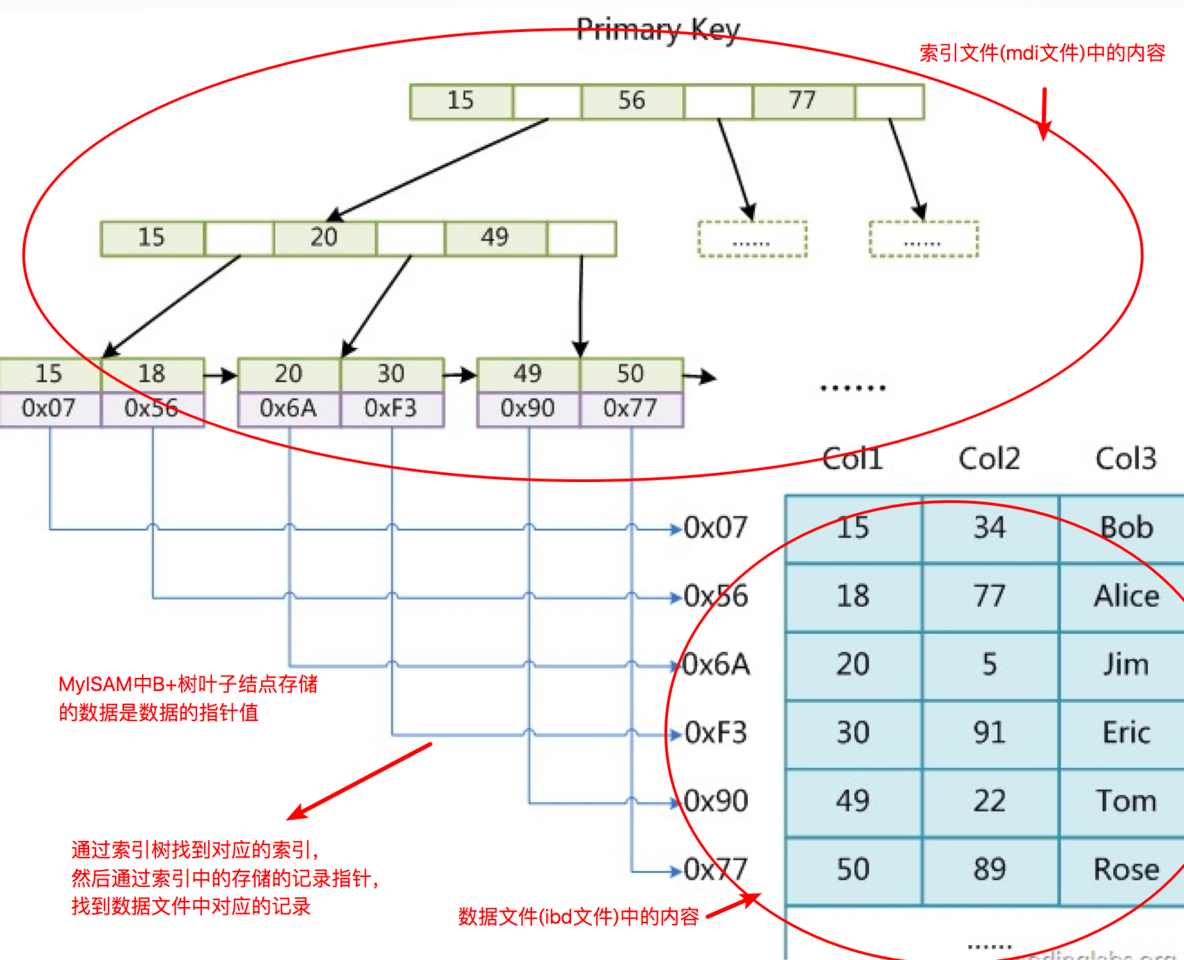
2.2.6 聚集索引(InnoDB)
InnoDB存储引擎的数据组织方式,是聚簇索引表:完整的记录,存储在主键索引中,通过主键索引,就可以获取记录所有的列,也就是说表数据和索引是在一起,这就是聚集索引
InnoDB要求表必须有主键(MyISAM 可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL 自动为 InnoDB 表生成一个隐含字段作为主键,类型为长整形。
1、 主键索引
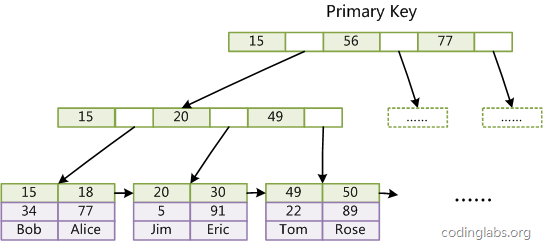
1、 辅助索引
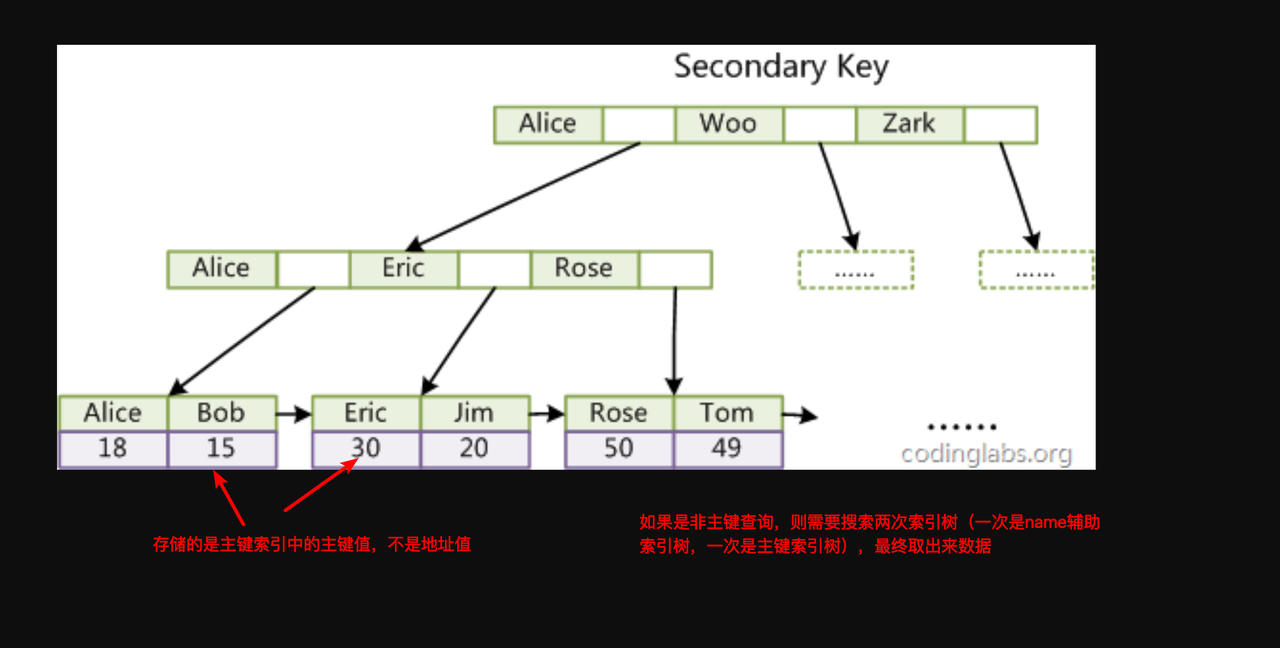
聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主
键,然后用主键到主索引中检索获得记录
2.2.7 非聚集索引(MyISAM)
B+树叶子节点只会存储数据行(数据文件)的指针,简单来说数据和索引不在一起,就是非聚集索引。非聚集索引中的主键索引和辅助索引都会存储指针的值
1、 主键索引
1、 非主键索引
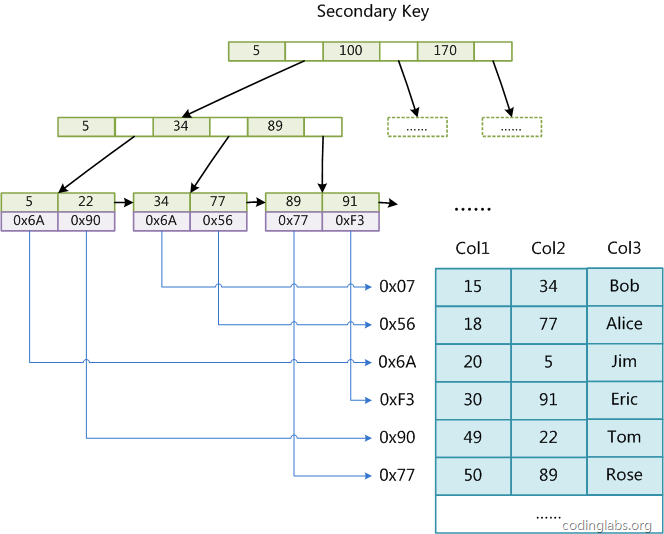
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。
2.2.8 组合索引使用
为了节省mysql索引存储空间以及提升搜索性能,可建立组合索引(能使用组合索引就不使用单列索引)
例如:创建如下的一个组合索引,相当于建立了col1,col1 col2,col1 col2 col3三个索引:
以下语句会创建一颗B+tree,但是它相对于三颗索引树的功效
ALTER TABLE 'table_name' ADD INDEX index_name('col1','col2','col3')
如何选择哪些列用来创建组合索引?
1、 常出现在where条件中的列,建议用来创建组合索引,至于组合索引中的顺序,是很重要的,因为组合索引会使用到最左前缀原则。但是因为MySQL中存在查询优化器,所以你的书写SQL条件的顺序,不一定是执行时候的where条件顺序。
2、 常出现在order by和group by语句中的列。最后按照顺序去创建组合索引。
3、 常出现在select语句中的列,也建议按照顺序,创建组合索引
最左前缀原则
顾名思义,就是最左优先,这个最左是针对于组合索引和前缀索引,理解如下:
1、 最左前缀匹配原则,非常重要的原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
2、 =和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式
2.2.9 如何使用索引
哪些情况需要创建索引
1、 主键自动建立唯一索引
2、 频繁作为查询条件的字段应该创建索引(业务)
3、 多表关联查询中,关联字段应该创建索引
4、 查询中统计或者分组字段,应该创建索引
5、 查询中排序的字段,应该创建索引
哪些情况不需要创建索引
1、 表记录太少
2、 经常进行增删改操作的表
3、 频繁更新的字段
4、 where条件里使用频率不高的字段
2.3 MySQL性能优化
| 类型 | 解释 |
|---|---|
| id | SELECT 查询的标识符. 每个 SELECT 都会自动分配一个唯一的标识符. |
| select_type | SELECT 查询的类型. table: 查询的是哪个表partitions: 匹配的分区 |
| type | join 类型 |
| possible_keys | 此次查询中可能选用的索引key: 此次查询中确切使用到的索引. |
| ref | 哪个字段或常数与 key 一起被使用 |
| rows | 显示此查询一共扫描了多少行. 这个是一个估计值. filtered: 表示此查询条件所过滤的数据的百分比 |
| extra | 额外的信息 |
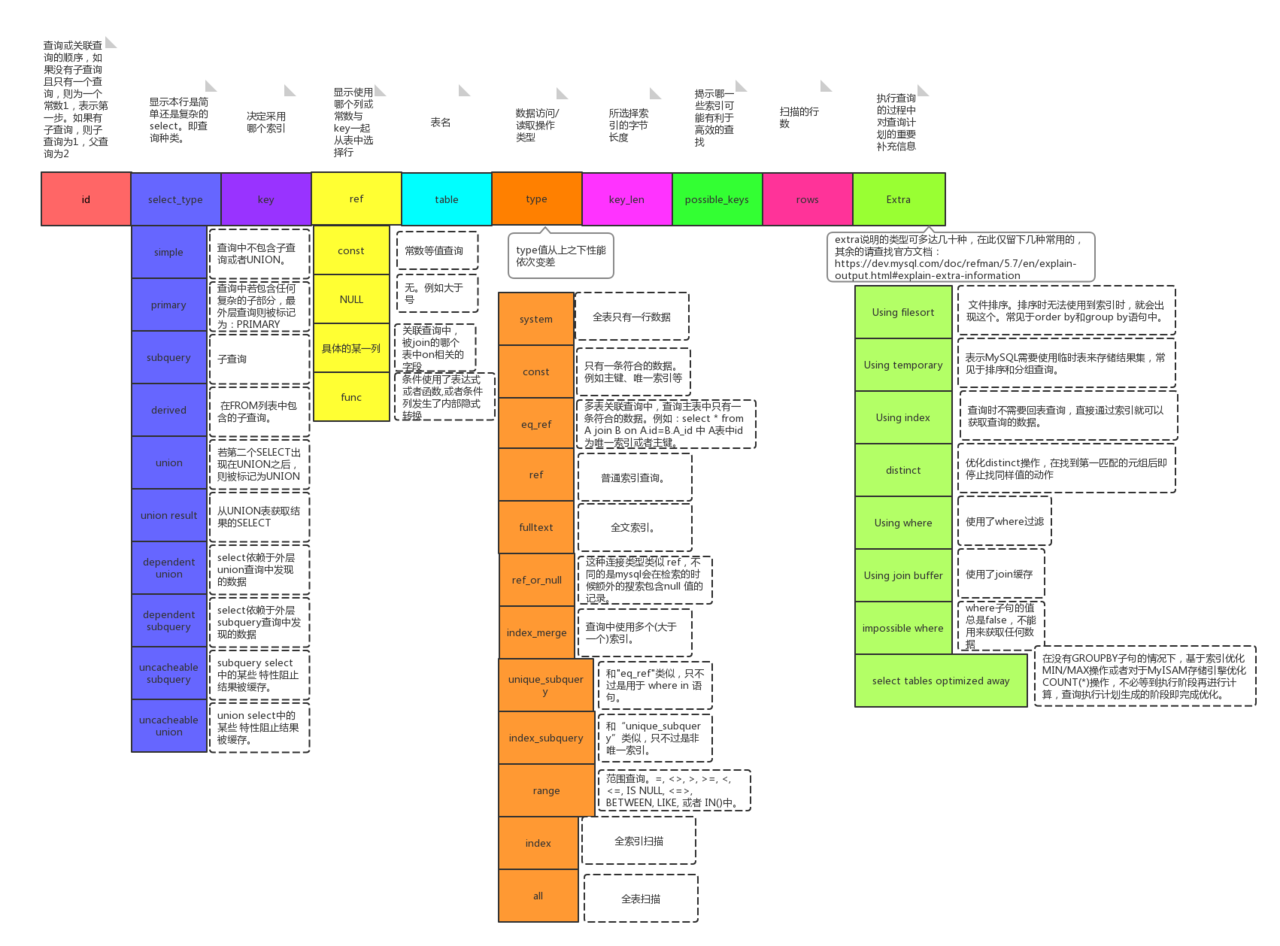
2.3.1 type讲解
显示的是单位查询的连接类型或者理解为访问类型,访问性能依次从好到差
1. system
2. const
3. eq_ref
4. ref
5. fulltext
6. ref_or_null
7. unique_subquery
8. index_subquery
9. range
10. index_merge
11. index
12. ALL
- 除了all之外,其他的type都可以使用到索引
- 除了index_merge之外,其他的type只可以用到一个索引
- 最少要使用到range级别
默认数据导入:github.com/datacharmer…
1、 System
表中只有一行数据或者是空表
![94\_12.png][94_12.png]
2、 const
使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
![94\_13.png][94_13.png]
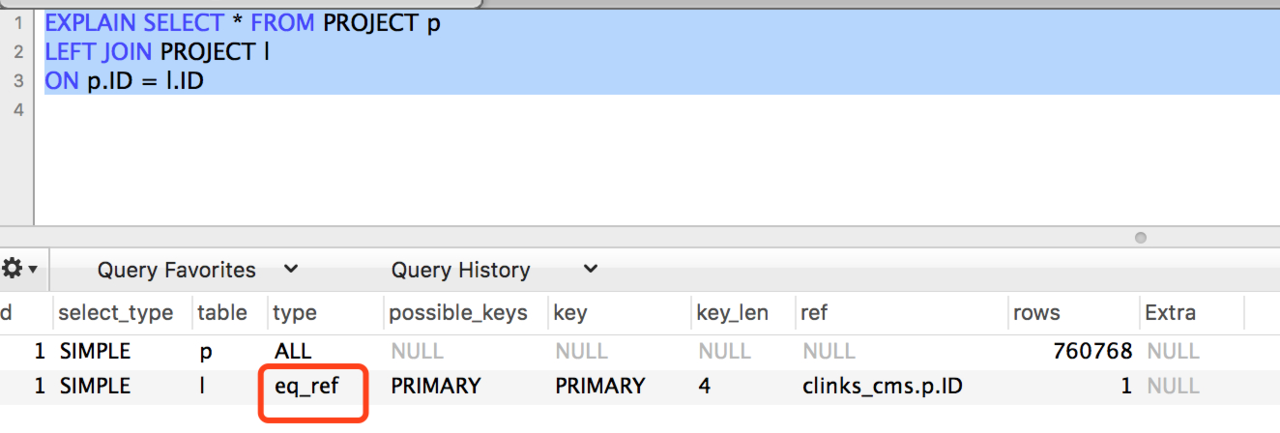
3、 eq_ref
此类型通常出现在多表的 join 查询, 表示对于前表的每一个结果, 都只能匹配到后表的一行结果. 并且查询的比较操作通常是 =, 查询效率较高
1、 ref
针对非唯一性索引,使用等值(=)查询。或者是使用了最左前缀规则索引的查询。
* 组合索引
![94\_15.png][94_15.png]
* 非唯一索引
![94\_16.png][94_16.png]
2、 fulltext
全文索引检索,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
3、 req_or_null
与ref方法类似,只是增加了null值的比较。实际用的不多。
4、 unique_subquery
用于where中的in形式子查询,子查询返回不重复值唯一值
5、 index_subquery
用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重
6、 range
索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中
![94\_17.png][94_17.png]
![94\_18.png][94_18.png]
7、 index_merge
表示查询使用了两个以上的索引,最后取交集或者并集,常见and,or的条件使用了不同的索引,官方排序这个在ref\_or\_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
8、 index
select结果列中使用到了索引,type会显示为index。
索引扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理
![94\_19.png][94_19.png]
9、 All
2.3.2 extra讲解
1、 using index
查询时不需要回表查询,直接通过索引就可以获取查询的结果数据
* 表示相应的SELECT查询中使用到了覆盖索引(covering index),避免访问表的数据行
* 如果同时出现using where,说明索引被用来执行查找索引键值
* 如果没有出现using where,表明索引用来读取数据而非执行查找动作
2、 using where
表示Mysql将对storage engine提取的结果进行过滤,过滤条件字段无索引
3、 using index condition
Using index condition 会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行
4、 using filesort
排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中说明MySQL会使用一个外部的索引排序,而不是按照索引顺序进行
2.3.3 优化SQL语句
创建索引注意:
- 为搜索字段(where中的条件)、排序字段、select查询列,创建合适的索引,
- 不过要考虑数据的业务场景:查询多还是增删多?
- 尽量建立组合索引并注意组合索引的创建顺序,按照顺序组织查询条件、尽量将筛选粒度大的查询条件放到最左边。
- 尽量使用覆盖索引
- SELECT语句中尽量不要使用*。
- order by、group by语句要尽量使用到索引
索引优化
1、 全值匹配
2、 最佳左前缀法则( 带头索引不能死,中间索引不能断)
3、 不要在索引上做计算
4、 范围条件右边的列失效
5、 尽量使用覆盖索引( 尽量使用覆盖索引(只查询索引的列),也就是索引列和查询列一致,减少select)
6、 索引字段上不要使用不等
7、 索引字段上不要判断null(索引字段上使用 is null / is not null 判断时,会导致索引失效而转向全表扫描)
8、 索引字段使用like不以通配符开头(索引字段使用like以通配符开头(‘%字符串’)时,会导致索引失效而转向全表扫描)
9、 索引字段字符串要加单引号
10、 索引字段不要使用or
11、 JOIN两张表的关联字段最好都建立索引,而且最好字段类型是一样的
其他优化
1、 WHERE条件中尽量不要使用1=1、not in语句(建议使用not exists)
2、 不用 MYSQL 内置的函数,因为内置函数不会建立查询缓存。
3、 尽量不使用count(*)、尽量使用count(主键)
总结
假设index(a,b,c)
| where语句 | 索引是否被引用 |
|---|---|
| where a = 3 | |
| where a = 3 and b = 5 | |
| where a = 3 and b = 5 and c = 4 | |
| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | |
| where a = 3 and c = 5 | |
| where a = 3 and b > 4 and c = 5 | |
| where a = 3 and b like ‘kk%’ and c = 4 | |
| where a = 3 and b like ‘%kk’ and c = 4 | |
| where a = 3 and b like ‘%kk%’ and c = 4 | |
| where a = 3 and b like ‘k%kk%’ and c = 4 |
| where语句 | 索引是否被引用 |
|---|---|
| where a = 3 | Yes,使用到a |
| where a = 3 and b = 5 | Yes,使用到a,b |
| where a = 3 and b = 5 and c = 4 | Yes,使用到a,b,c |
| where b = 3 或者 where b = 3 and c = 4 或者 where c = 4 | No |
| where a = 3 and c = 5 | Yes,使用到了a,但是c不可以,因为b断了 |
| where a = 3 and b > 4 and c = 5 | Yes,使用到了a和b,c不能在范围之后,b断了 |
| where a = 3 and b like ‘kk%’ and c = 4 | Yes,使用到a,b,c |
| where a = 3 and b like ‘%kk’ and c = 4 | Yes,使用到了a |
| where a = 3 and b like ‘%kk%’ and c = 4 | Yes,使用到了a |
| where a = 3 and b like ‘k%kk%’ and c = 4 | Yes,使用到a,b,c |
2.3.4 服务器参数调优
1、 设置足够大的innodb_buffer_pool_size,将数据读取到内存中(建议innodb_buffer_pool_size设置为总内存大小的3/4或者4/5.)
怎样确定 innodb_buffer_pool_size 足够大。数据是从内存读取而不是硬盘? SHOW GLOBAL STATUS LIKE ‘innodb_buffer_pool_pages_%’;
1、 内存预热
将磁盘数据在MySQL Server启动的时候,读取到内存中。
1、 降低磁盘写入次数
* 对于生产环境来说,很多日志是不需要开启的,比如:通用查询日志
* 慢查询日志、错误日志使用足够大的写入缓存 innodb\_log\_file\_size
> 推荐 innodb\_log\_file\_size 设置为 0.25 \* innodb\_buffer\_pool\_size
* 设置合适的innodb\_flush\_log\_at\_trx\_commit,和日志落盘有关系
提高磁盘读写
可以考虑使用SSD硬盘,不过得考虑成本是否合适
2.3.5 硬件选购和参数优化
1、 内存相关
内存的 IO 比硬盘的速度快很多,可以增加系统的缓冲区容量,使数据在内存停留的时间更长,以减少磁盘的 IO
1、 磁盘 I/O 相关
- 使用 SSD 或 PCle SSD 设备,至少获得数百倍甚至万倍的 IOPS 提升
- 购置阵列卡同时配备 CACHE 及 BBU 模块,可以明显提升 IOPS
- 尽可能选用 RAID-10,而非 RAID-5
1、 配置 CUP 相关
- 在服务器的 BIOS 设置中,调整如下配置:
- 选择 Performance Per Watt Optimized(DAPC)模式,发挥 CPU 最大性能
- 关闭 C1E 和 C States 等选项,提升 CPU 效率
- Memory Frequency(内存频率)选择 Maximum Performance
2.3.6 SQL设计层面优化
1、 表设计
- 设计中间表,一般针对于统计分析功能,或者实时性不高的需求(OLTP、OLAP)
- 为减少关联查询,创建合理的冗余字段(考虑数据库的三范式和查询性能的取舍,创建冗余字段还需要注意数据一致性问题
- 每张表建议都要有一个主键(主键索引),而且主键类型最好是int类型,建议自增主键(不考虑分布式系统的情况下)
1、 选择合适的数据类型
- 使用可以存下数据最小的数据类型
- 使用简单的数据类型。int 要比 varchar 类型在mysql处理简单
- 尽量使用 tinyint、smallint、mediumint 作为整数类型而非 int
- 尽可能使用 not null 定义字段,因为 null 占用4字节空间
- 尽量少用 text 类型,非用不可时最好考虑分表
- 尽量使用 timestamp 而非 datetime
- 单表不要有太多字段,建议在 20 以内
1、 拆分表
对于表中经常不被使用的字段或者存储数据比较多的字段,考虑拆表
对于字段太多的大表,考虑垂直拆表(比如一个表有100多个字段
> 比如商品表中会存储商品介绍,此时可以将商品介绍字段单独拆解到另一个表中,使用商品ID关联)
- 垂直拆分:将表中多个列分开放到不同的表中。例如用户表中一些字段经常被访问,将这些字段放在一张表中,另外一些不常用的字段放在另一张表中。插入数据时,使用事务确保两张表的数据一致性。
- 水平拆分:按照行进行拆分。例如用户表中,使用用户ID,对用户ID取10的余数,将用户数据均匀的分配到0~9的10个用户表中。查找时也按照这个规则查询数据。
1、 读写分离
一般情况下对数据库而言都是“读多写少”。换言之,数据库的压力多数是因为大量的读取数据的操作造成的。我们可以采用数据库集群的方案,使用一个库作为主库,负责写入数据;其他库为从库,负责读取数据。这样可以缓解对数据库的访问压力。
2.3.7 数据库架构调优
1、 分区分表
2、 业务分库
3、 主从同步与读写分离
4、 数据缓存
5、 主从热备与HA双活
2.4 实战优化
1、 慢SQL优化挑战赛
> 表结构
CREATE TABLE `a` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`seller_id` bigint(20) DEFAULT NULL,
`seller_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_bin DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=32744 DEFAULT CHARSET=utf8;
CREATE TABLE `b` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`seller_name` varchar(100) DEFAULT NULL,
`user_id` varchar(50) DEFAULT NULL,
`user_name` varchar(100) DEFAULT NULL,
`sales` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=32744 DEFAULT CHARSET=utf8;
CREATE TABLE `c` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` varchar(50) DEFAULT NULL,
`order_id` varchar(100) DEFAULT NULL,
`state` bigint(20) DEFAULT NULL,
`gmt_create` varchar(30) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=458731 DEFAULT CHARSET=utf8;
> 待优化SQL
select
a.seller_id,
a.seller_name,
b.user_name,
c.state
from a,b,c
where a.seller_name = b.seller_name
and b.user_id = c.user_id
and c.user_id = 17
and a.gmt_create BETWEEN DATE_ADD(NOW(), INTERVAL 600 MINUTE) and DATE_ADD(NOW(), INTERVAL 600 MINUTE)
order by a.gmt_create;
> 创建索引
-- A表上创建索引:
Alter table a add index ind_a_gmt_create(gmt_create);
-- B表上创建索引:
Alter table b add index ind_b_seller_name(seller_name);
-- C表创建索引:
Alter table c add index ind_c_user_id(user_id);
> 隐式转换
-- a表:gmt_create使用了varchar来存储,在5.6支持更高时间精度后,将会发生隐式转换。
-- b表:a表和b表的seller_name字段在COLLATE定义上不一致,也会导致隐式转换。
-- c表:b表和c表的user_id字段都定义为了varchar,但是SQL传入为数字,也会导致隐式转换。
alter table a modify column gmt_create datetime;
alter table a modify column seller_name varchar(100) ;
alter table c modify column user_id bigint;
2、 ##### 优化LIMIT分页 #####
> 尽可能的使用覆盖索引扫描
SELECT ID, ADDRESS FROM PROJECT ORDER BY STATUS LIMIT 64000, 100
SELECT SQL_NO_CACHE `b_regbroker`.*,`db`.`name`,db.sub_branch,db.account,db.card_img,mu.UserName,pb.broker_name,pb.mobile_tel
from b_regbroker
LEFT JOIN myuser mu on mu.UserGUID=b_regbroker.ModifiedBy
LEFT JOIN b_regbroker pb on pb.b_regbrokerId=b_regbroker.parent_brokerId
LEFT JOIN b_regbroker_bank db on db.regbroker_id = b_regbroker.b_regbrokerId
and isdel=0 and isdefault=1
where b_regbroker.`status` in (1,2)
and b_regbroker.token='rkqqnn1427611021'
and b_regbroker.is_delete=0
and IFNULL(b_regbroker.capacity_des,'') <> '9108'
ORDER BY CreatedOn desc
LIMIT 126000, 3000;
SELECT p.ID,p.ADDRESS
FROM PROJECT p
INNER JOIN (
SELECT ID FROM PROJECT ORDER BY STATUS LIMIT 64000, 100
) AS tmp
ON p.ID = tmp.ID
SELECT SQL_NO_CACHE `b_regbroker`.*,`db`.`name`,db.sub_branch,db.account,db.card_img,mu.UserName,pb.broker_name,pb.mobile_tel
from b_regbroker
LEFT JOIN myuser mu on mu.UserGUID=b_regbroker.ModifiedBy
LEFT JOIN b_regbroker pb on pb.b_regbrokerId=b_regbroker.parent_brokerId
LEFT JOIN b_regbroker_bank db on db.regbroker_id = b_regbroker.b_regbrokerId
and isdel=0 and isdefault=1
where b_regbroker.`status` in (1,2)
and b_regbroker.token='rkqqnn1427611021'
and b_regbroker.is_delete=0
and IFNULL(b_regbroker.capacity_des,'') <> '9108'
AND b_regbroker.CreatedOn <= '2016-07-23 14:19:04'
ORDER BY CreatedOn desc
LIMIT 3000;
3. 参考
1、 zhaox.github.io/2016/06/24/…
2、 segmentfault.com/a/119000001…
3、 www.jianshu.com/p/1f17a496f…
4、 tech.souyunku.com/wy123/p/710… 物理文件体系结构的简单整理说明】
5、 database.51cto.com/art/201901/…【一份超详细的MySQL高性能优化实战总结!】
6、 blog.csdn.net/asdfsadfasd… I/O & 顺序 I/O】
7、 tech.souyunku.com684490… 性能优化技巧】
8、 tech.souyunku.com/nullzx/p/87…
9、 blog.51cto.com/13912525/23…
10、 www.kancloud.cn/kancloud/th…
11、 www.jianshu.com/p/5600781f6… 【聊一聊B+树】
12、 www.jianshu.com/c/cd1570246…
13、 blog.csdn.net/qq_26222859…
14、 tech.souyunku.com684490…
15、 tech.souyunku.com684490… SQL 优化】
16、 tech.souyunku.com684490… 中NULL和空值的区别?】
17、 my.oschina.net/benhaile/bl…
18、 yq.aliyun.com/articles/64…
19、 blog.csdn.net/weixin_3915…
20、 www.bilibili.com/video/av564…
21、 cloud.tencent.com/developer/a…
22、 www.centos.bz/2017/09/mys…
23、 www.365jz.com/article/247…
24、 tech.souyunku.com684490…
25、 tech.souyunku.com684490…
26、 tech.souyunku.com684490… 必知必会》读书笔记,请您笑纳!】
27、 www.jianshu.com/p/9fab9266b…
28、 www.jianshu.com/p/569569b8b…
29、 www.jianshu.com/p/a14ea51a4…
30、 yq.aliyun.com/articles/13…
31、 cloud.tencent.com/developer/a…
32、 tech.souyunku.com/annsshadow/…>查询执行流程->SQL解析顺序】
33、 github.com/datacharmer… test_db】