二级缓存
二级缓存也被称为应用级缓存,与一级缓存不同的是它的作用范围是整个应用。而且可以跨线程使用。所以二级缓存有更高的命中率,适用于缓存修改较少的数据
如何使用二级缓存
全局配置
<settings>
<!-- 开启缓存,默认为true。即默认开启缓存 -->
<setting name="cacheEnabled" value="true" />
</settings>
mapper配置
除了全局配置,还需要配置 mapper 的缓存命名空间。
注解方式
通过 @CacheNamespace 注解
// 通过注解定义缓存命名空间
@CacheNamespace
public interface AuthorMapper {
@Select("select * from author where id = #{id}")
Author selectById(Long id);
}
XML配置方式
通过 节点配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="org.mybatis.example.BlogMapper">
<!-- 定义缓存命名空间 -->
<cache />
<select id="selectBlog" resultType="Blog">
select *
from blog
where id = #{id}
</select>
</mapper>
执行查询
二级缓存是用来支持在多个SqlSession之间,跨线程共享数据的。因此我们的测试代码使用了两个 SqlSession来执行查询,看看经过添加了缓存配置之后,能否进行缓存命中
public class SecondLevelCacheTest {
private SqlSessionFactory sqlSessionFactory;
@Before
public void before() throws IOException {
String resource = "mybatis-config.xml";
InputStream inputStream = Resources.getResourceAsStream(resource);
sqlSessionFactory = new SqlSessionFactoryBuilder().build(inputStream);
inputStream.close();
}
@Test
public void test() {
SqlSession sqlSession = sqlSessionFactory.openSession(true);
SqlSession sqlSession1 = sqlSessionFactory.openSession(true);
AuthorMapper mapper = sqlSession.getMapper(AuthorMapper.class);
AuthorMapper mapper1 = sqlSession1.getMapper(AuthorMapper.class);
// 第一次查询
Author author = mapper.selectById(1L);
// 第二次查询
Author author1 = mapper1.selectById(1L);
System.out.println(author == author1);
}
}
通过执行上述代码,可以猜测下第二次查询是否可以命中缓存?

从日志看,第二次查询并没有命中缓存。因为需要提交事务才会保存到二级缓存。为什么要有这种规定?
二级缓存是针对不同会话间的缓存,一个会话对数据的修改、新增,需要在提交后才能被另外的会话读取。因此只有提交后的数据才能被二级缓存保留下来,否则将会导致数据不一致
二级缓存的执行细节
二级缓存由谁来负责?
在一级缓存中,缓存的执行流程是由 BaseExecutor 负责的。那么二级缓存中的执行流程又是由哪个类来负责的呢?
在执行查询的入口 DefaultSqlSession 打个断点看下,将断点打在第5行之后,执行测试用例
@Override
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}

可以看到这里的 Executor 对象是 CachingExecutor,那么二级缓存的流程是由它负责的吗?继续跟进看个究竟。
最终,在以下代码中可以发现,在 CachingExecutor 内部中,会首先通过它的成员变量 tcm 的 getObject 获取数据,当获取到的数据为null时,才会通过其成员变量 delegate 进行数据库查询,这里的 delegate 就是 ReuseExecutor 对象。

到这里,我们已经清楚了,CachingExecutor 就是负责维护二级缓存的类。其内部通过代理对象 delegate (ReuseExecutor,是否为 ReuseExecutor 取决于我们配置了哪个默认Executor类型)进行真正的数据库查询。
CachingExecutor的结构
public class CachingExecutor implements Executor {
private final Executor delegate;
private final TransactionalCacheManager tcm = new TransactionalCacheManager();
public CachingExecutor(Executor delegate) {
this.delegate = delegate;
delegate.setExecutorWrapper(this);
}
// ... 省略其他方法实现
}

CachingExecutor 实现了 Executor 接口,其内部持有了一个 Executor 的实现类对象。这其实是一种装饰器模式的应用,把装饰器的逻辑包装到被装饰类对象的逻辑之上,在这里装饰器就是 CachingExecutor,被装饰类对象就是 Executor 的实现类对象。通过这种设计,可以将缓存和核心的执行器逻辑解耦出来。
CachingExecutor 通过 TransactionalCacheManager 来管理缓存,而 TransactionalCacheManager 通过操作 TransactionalCache 的接口来维护缓存。
我们来看一下 TransactionalCache 的源码
TransactionalCache, 是二级缓存事务缓冲区。这个类包含了所有在会话期间要添加到二级缓存的缓存条目。
调用提交时,将条目发送到缓存,如果会话回滚则丢弃缓存条目。
添加了 Blocking cache 的支持,任何调用 get() 方法但未命中缓存的调用,都将跟着一个 put() 调用,以便可以释放与该键关联的任何锁
public class TransactionalCache implements Cache {
// 缓存接口实现类对象,即真正持有缓存的 Cache 实现类
private final Cache delegate;
private boolean clearOnCommit;
// 暂存缓存条目的map
private final Map<Object, Object> entriesToAddOnCommit;
// 记录未未命中缓存的 key,以便在会话提交时设置一个 null 值到缓存中,防止缓存穿透。
private final Set<Object> entriesMissedInCache;
public TransactionalCache(Cache delegate) {
this.delegate = delegate;
this.clearOnCommit = false;
this.entriesToAddOnCommit = new HashMap<>();
this.entriesMissedInCache = new HashSet<>();
}
}
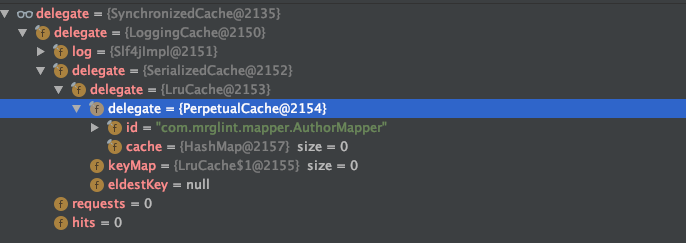
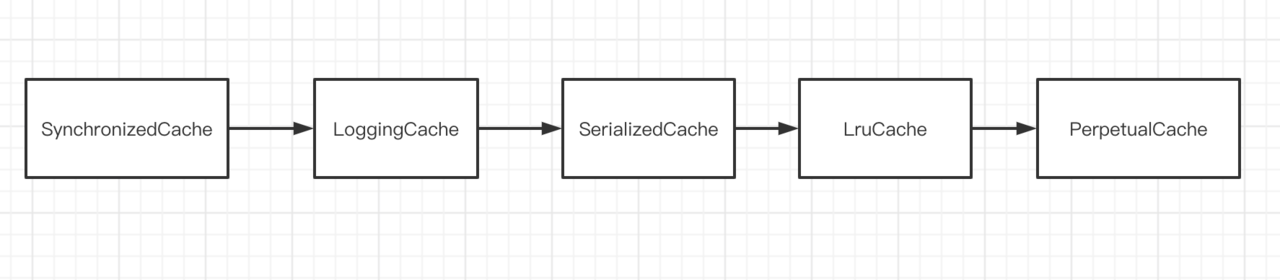
可以看出,TransactionalCache 也是利用了装饰器模式,内部持有一个 Cache 缓存接口实现类对象,通过TransactionalCache这个装饰器,将缓存事务缓冲区的功能封装在 Cache 缓存接口实现类对象的逻辑之上。解耦了两者(TransactionalCache 作为装饰器的逻辑、Cache 接口实现类对象作为被装饰器的逻辑)。
另外,这个 delegate 对象本身也是一个层层装饰的对象。每个装饰器只负责自己的功能,符合单一职责原则,耦合性低
二级缓存操作流程
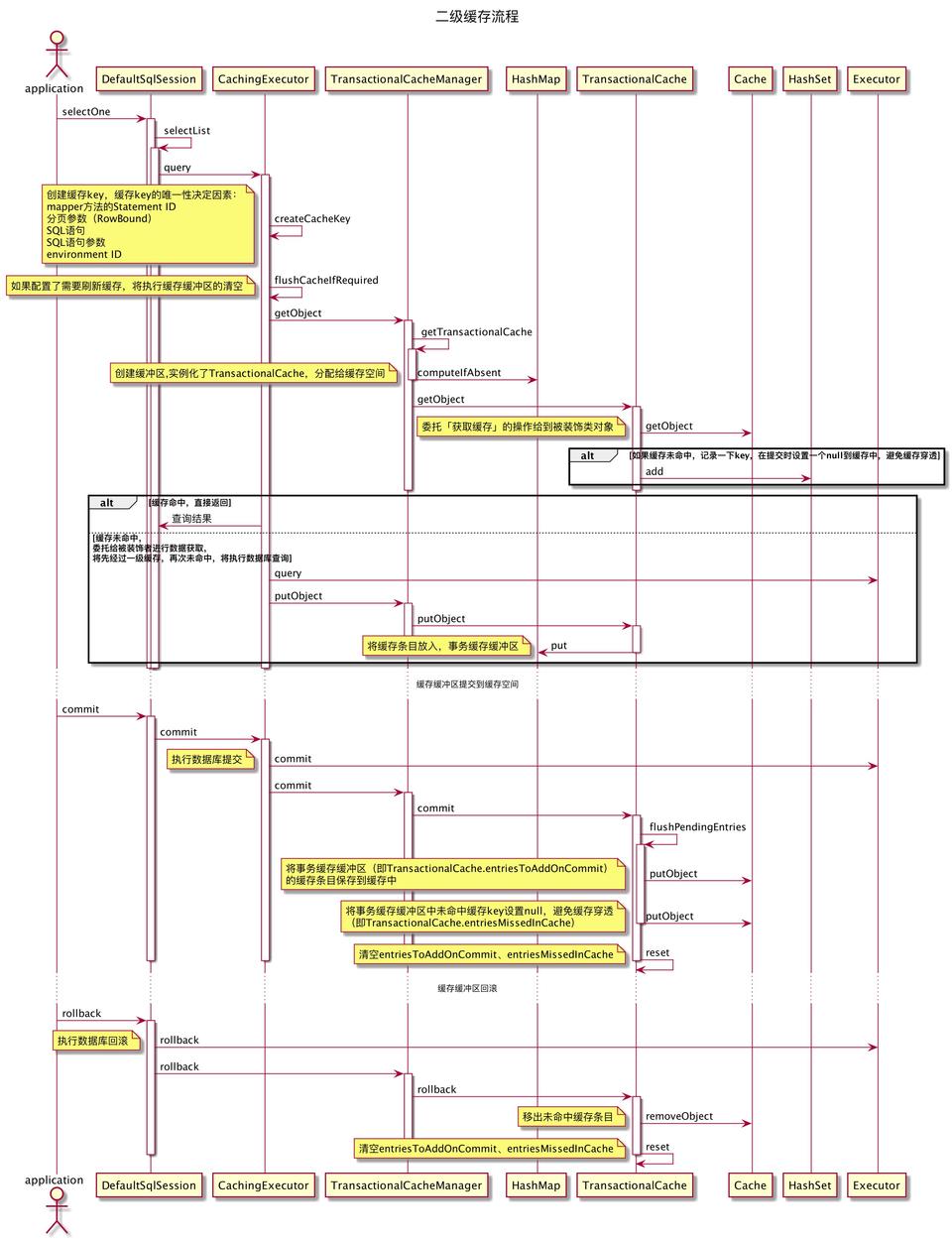
这里有两个疑问:
- 为什么提交时,对于未命中的缓存key,要设置null值?
- 为什么回滚时,对于未命中的缓存key,要删除缓存key?
对于第一个疑问比较好理解,如果提交时将未命中的缓存key设置null到缓存中,可以避免缓存穿透;
第二个疑问,暂时不知道为什么要这样写,我的理解是当这个被回滚的会话在回滚时,其实它并未将entriesMissedInCache设置到缓存中。
从整个流程来看,CachingExecutor 通过与 TransactionalCacheManager 交互,达到控制 TransactionalCache 的目的。而 TransactionalCache 装饰了真正的缓存空间,TransactionalCache 只是提供了一个暂存功能,以便在会话提交时真正的将数据刷写到缓存中;或者回滚时清空暂存区。本质上,TransactionalCacheManager 只是将 TransactionalCache 封装起来,对 CachingExecutor 暴露了接口,是一种门面模式的应用。
CachingExecutor怎么被构造出来的
在通过 DefaultSqlSessionFactory 创建SqlSession时,CachingExecutor 被创建。
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 创建 Executor
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
// 如果打开了缓存开关,那么设置到 SqlSession 的 Executor 就是通过 CachingExecutor 装饰过的
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}