Executor的类体系结构和接口
Executor 接口定义了数据库操作的基本接口,包含几大类:
- 查询操作
- 更新操作
- 提交、回滚操作
- 缓存相关
- 懒加载
在了解这些接口的实现之前,先来看下 Executor 接口相关的类体系结构。
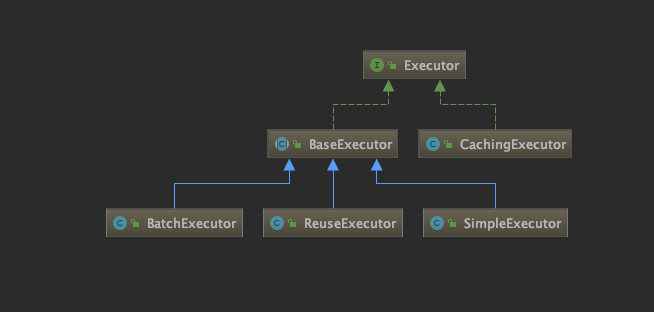
如何执行SQL的
mybatis 配置如下
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<settings>
<setting name="logImpl" value="SLF4J"/>
<!-- 这篇文章,只描述执行器 Executor 的实现逻辑,这里先关闭二级缓存,以免造成干扰 -->
<setting name="cacheEnabled" value="false" />
</settings>
<typeAliases>
<package name="com.mrglint.model"/>
</typeAliases>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url"
value="jdbc:mysql://IP:3306/mybatisdemo?useUnicode=true&characterEncoding=UTF8&autoReconnect=true"/>
<property name="username" value="root"/>
<property name="password" value="password"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/BlogMapper.xml"/>
<package name="com.mrglint.mapper"/>
</mappers>
</configuration>
CREATE TABLE `author` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
单元测试
@Test
public void simpleExecutorTest() throws IOException {
SqlSession sqlSession = sqlSessionFactory.openSession(true);
Author o = sqlSession.selectOne("com.mrglint.mapper.AuthorMapper.selectById", 1L);
System.out.println(o);
}
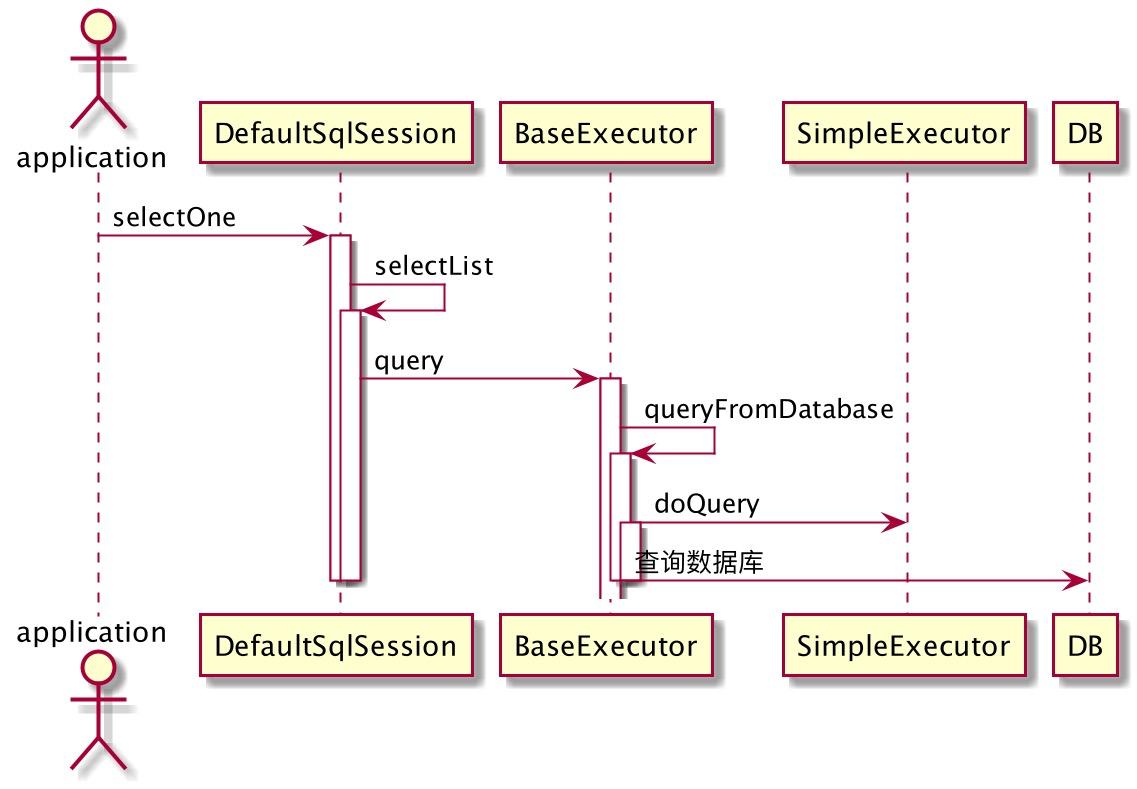
看一下 BaseExecutor 的 queryFromDatabase 方法源码可以发现,其内部调用的是自身的一个抽象方法 doQuery,而这个抽象方法由其子类实现。
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// doQuery 由子类实现 doQuery 方法
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
BaseExecutor 的子类有 SimpleExecutor、ReuseExecutor、BatchExecutor。这三者的作用分别是:
- 简单处理器,不会重用 Statement
- 重用处理器,将重用 Statement
- 批处理器,可以批量提交SQL到DB
SimpleExecutor
每次都重新生成 Statement 对象
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
// 创建 JDBC 的 Statement 对象
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
// 每次都通过 Connection 对象,重新生成 Statement 对象
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
ReuseExecutor
同一会话内会重用 Statement 对象,只要 SQL 相同。因此开发过程中,建议使用 ReuseExecutor 作为执行器。可以减少重复创建 Statement 的开销
@Override
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
Statement stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
}
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
BoundSql boundSql = handler.getBoundSql();
String sql = boundSql.getSql();
// 如果存在 Statement 缓存,则直接使用,而不用通过 Connection 重新创建
if (hasStatementFor(sql)) {
stmt = getStatement(sql);
applyTransactionTimeout(stmt);
} else {
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
putStatement(sql, stmt);
}
handler.parameterize(stmt);
return stmt;
}
// 只要 SQL 相同,都可以重用 Statement
private boolean hasStatementFor(String sql) {
try {
return statementMap.keySet().contains(sql) && !statementMap.get(sql).getConnection().isClosed();
} catch (SQLException e) {
return false;
}
}
private Statement getStatement(String s) {
return statementMap.get(s);
}
private void putStatement(String sql, Statement stmt) {
statementMap.put(sql, stmt);
}
BatchExecutor
BatchExecutor 的区别主要在可以批量处理更新操作。体现在 doUpdate 方法中,最后需要通过调用 doFlushStatements 来提交到DB
// 通过类成员变量来存储最后一次执行的SQL,用于判断是否将SQL语句和参数进行批量合并
private String currentSql;
private MappedStatement currentStatement;
@Override
public int doUpdate(MappedStatement ms, Object parameterObject) throws SQLException {
final Configuration configuration = ms.getConfiguration();
final StatementHandler handler = configuration.newStatementHandler(this, ms, parameterObject, RowBounds.DEFAULT, null, null);
final BoundSql boundSql = handler.getBoundSql();
final String sql = boundSql.getSql();
final Statement stmt;
// 如果是连续的一组同类型操作,那么将参数进行合并,之后一次性提交
if (sql.equals(currentSql) && ms.equals(currentStatement)) {
int last = statementList.size() - 1;
stmt = statementList.get(last);
applyTransactionTimeout(stmt);
handler.parameterize(stmt);//fix Issues 322
BatchResult batchResult = batchResultList.get(last);
batchResult.addParameterObject(parameterObject);
} else {
Connection connection = getConnection(ms.getStatementLog());
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt); //fix Issues 322
currentSql = sql;
currentStatement = ms;
statementList.add(stmt);
batchResultList.add(new BatchResult(ms, sql, parameterObject));
}
handler.batch(stmt);
return BATCH_UPDATE_RETURN_VALUE;
}
Executor是怎么被创建的?
通过 SqlSessionFactory 来获取 SqlSession,在创建SqlSession的过程中,将 Executor 绑定到 SqlSession上。之后的数据库操作 SqlSession 会委托给 Executor 来执行。流程如下:
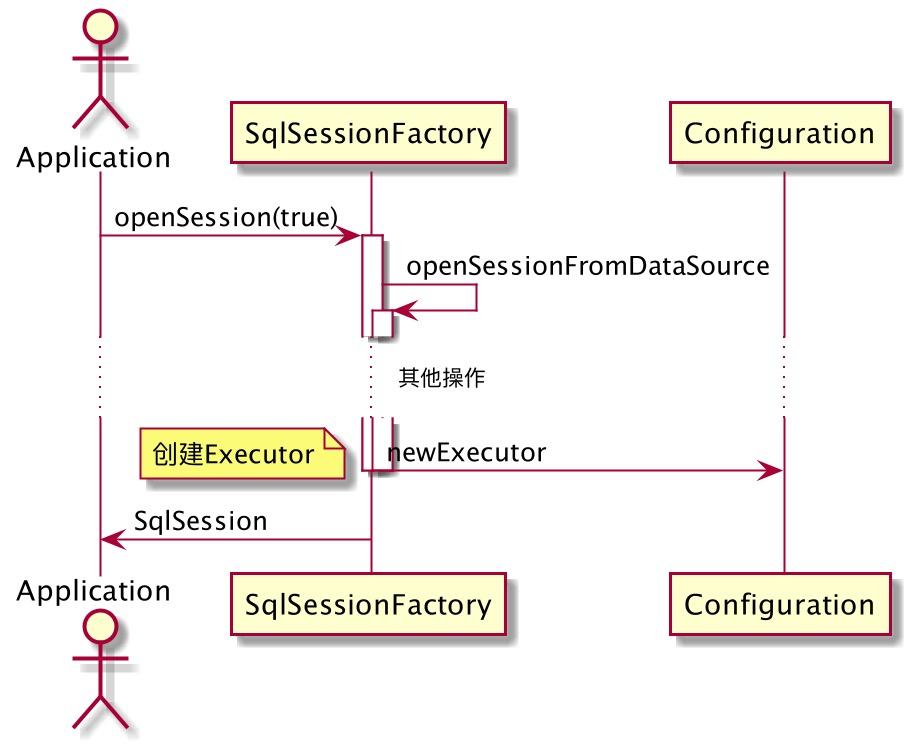
下面我们来看下,是如何创建 Executor 的
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
try {
final Environment environment = configuration.getEnvironment();
final TransactionFactory transactionFactory = getTransactionFactoryFromEnvironment(environment);
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
// 创建 Executor
final Executor executor = configuration.newExecutor(tx, execType);
return new DefaultSqlSession(configuration, executor, autoCommit);
} catch (Exception e) {
closeTransaction(tx); // may have fetched a connection so lets call close()
throw ExceptionFactory.wrapException("Error opening session. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
// 根据 ExecutorType 值,分别会创建三种不同的 Executor
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) {
executor = new CachingExecutor(executor);
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
可以通过配置文件来指定默认的执行器。
<!--指定executor类型。默认为 SIMPLE ,建议使用 REUSE -->
<setting name="defaultExecutorType" value="REUSE" />
执行器的一级缓存
回到 SQL 执行的流程中来,看看mybatis查询的一级缓存是如何实现的(此处所说的情况,是不使用二级缓存的情况下而言的,二级缓存的相关知识在后续文章中介绍)
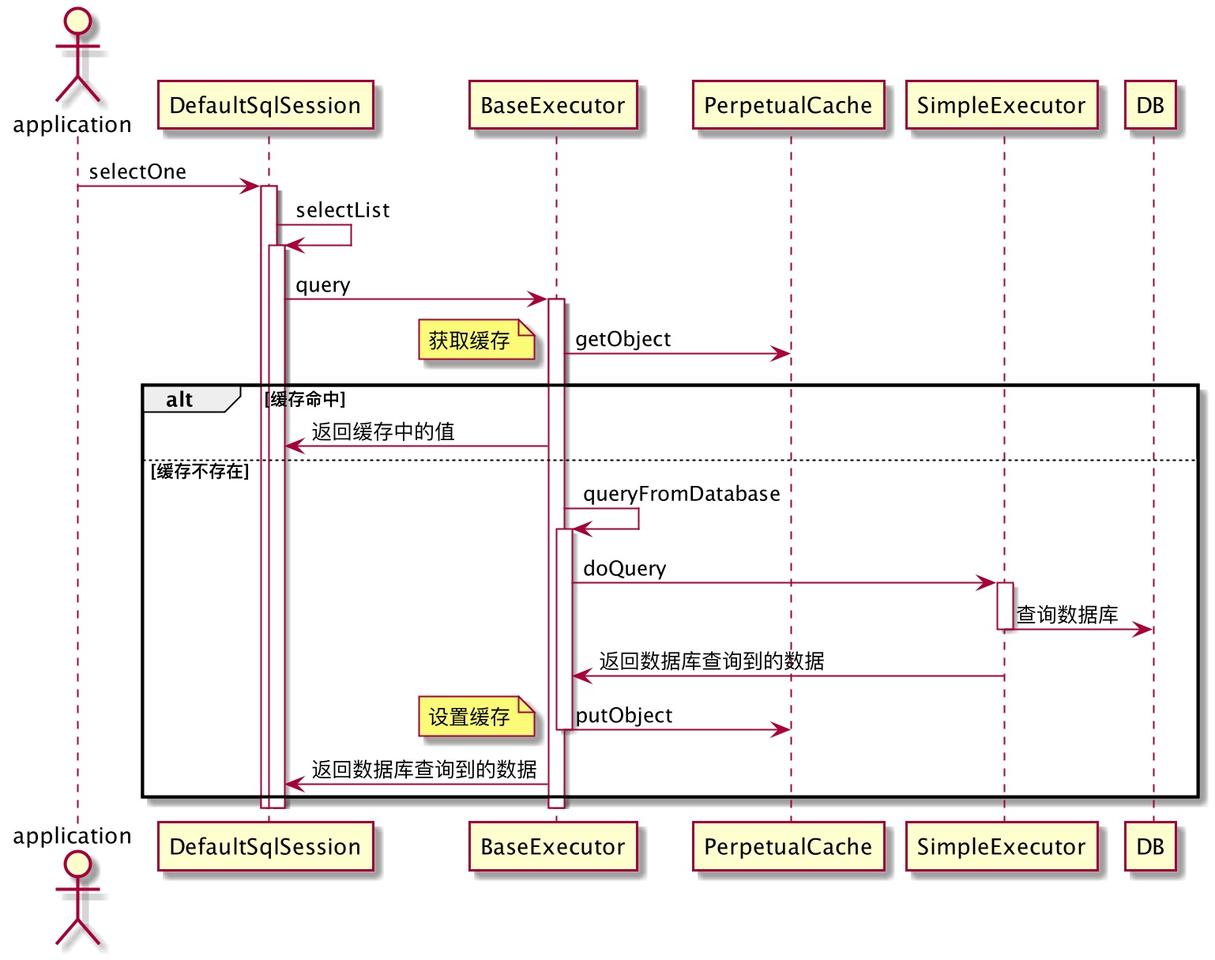
可以看出,一级缓存的功能是实现在 BaseExecutor 中。借助一个 PerpetualCache 来实现的。PerpetualCache 实现了 Cache 接口,底层使用 HashMap 来存储数据
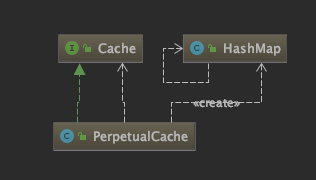
一级缓存的源码
// BaseExecutor#query 方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
// 先从缓存中加载数据
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
// 缓存命中
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 缓存不存在,则需要到数据库中获取
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
// BaseExecutor#queryFromDatabase
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
// doQuery方法,由 BaseExecutor 的子类实现
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
// 设置缓存
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
什么时候清空一级缓存
一级缓存清空的策略粒度比较大,属于整体缓存清空。调用以下方法实现:
void clearLocalCache();
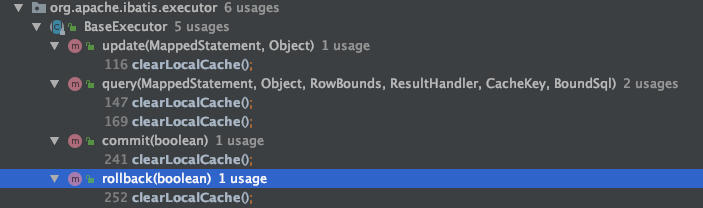
调用场景:
- 更新数据
- 提交、回滚
- 查询
除了提交、回滚这两个场景比较好理解。我们着重来看下查询时什么情况要调用 clearLocalCache 方法
@SuppressWarnings("unchecked")
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 调用 清空缓存 方法
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
// 调用 清空缓存 方法
clearLocalCache();
}
}
return list;
}
public boolean isFlushCacheRequired() {
return flushCacheRequired;
}
查询方法需要清空缓存的情况:
- 设置了 localCacheScope = STATEMENT 时,默认情况下,会话期间执行的所有查询都被缓存。如果设置为 STATEMENT 本地会话仅用于语句执行。在同一个Session的两个不同调用之间不会共享数据。在mybatis-config.xml 文件中统一设置
- 配置了 flushCache = true,那么每次执行该SQL的时候都会清空缓存。在每个mapper 中独立设置
总结
mybatis中执行 SQL 的流程,通过 Executor 这个接口来实现。其实现类有 :
- BaseExecutor,作为抽象类,提供操作流程的骨架。统一处理一级缓存、事务提交、回滚的操作。
- SimpleExecutor,作为BaseExecutor的子类,通过 doXXX 方法真正执行SQL操作
- ReuseExecutor,类似于 SimpleExecutor,但提供了额外功能:可以重用 Statement,减少创建 Statement 对象所导致的开销
- BatchExecutor,类似于 SimpleExecutor,但提供额外功能:可以批处理提交SQL到DB层处理,减少与DB之间的网络操作