三. 分组 ()
在上一篇文章中 的量词部分说到, 量词的一般形式为{m,n},用于限定{}前面的 元素 出现的次数
为什么这里写的是元素而不是字符呢?
这就要引入 分组 的概念了, 使用()将一块表达式括起来, 可以把这个整体当做一个元素处理
例如(ab)? 可以将两个字符ab作为一个整体看待,这时量词?表示的就是ab作为整体,要么一起出现,要么一起不出现
/^(ab)+$/.test('abab') //true
/^(ab)+$/.test('aba') //false
多选结构
多选结构形式为(...|...),即在括号内用竖线分隔多个子表达式, 可以用于表达或的概念
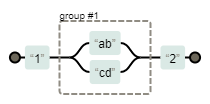
当|被用在最外层时,相当于将整个表达式视为一个多选结构 ,即ab|cd等价于(ab|cd)
通过这个正则表达式可视化的网站,可以方便的查看效果
表达式 1(ab|cd)2,可视化结果如下:
反向引用 (Back reference)
通过()括起来的分组中匹配到的内容会被保留下来,可以在后面的表达式中引用到被匹配到的文本,形式为\num(这是js中的表示法,其他语言可能有所区别)
注意: 有多处分组时数字编号是以表达式中左括号出现顺序依次排列的
例如:
/(\d{4})-(\d{2})-(\d{2}) \1-\2-\3/.test('2020-01-02 2020-01-02') //true
/(\d{4})-(\d{2})-(\d{2}) \1-\2-\3/.test('2020-01-02 2020-01-03') //false
(\d{4})-(\d{2})-(\d{2}) \1-\2-\3对应的可视化图片:
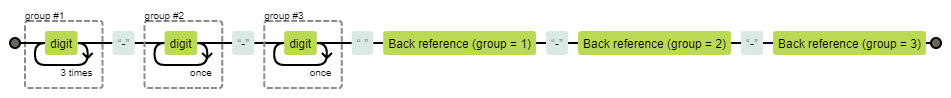
在字符串替换中,也可以在第二个参数中引用第一个参数里的分组,不过形式变为$num(js语法)
'2020-01-02'.replace(/(\d{4})-(\d{2})-(\d{2})/,'$1年 $2月 $3日')
//2020年 01月 02日"
非捕获分组
使用正常的()分组会把括号中子表达式匹配的内容暂时存储起来,如果用不着反向引用的功能,会影响正则表达式的性能;
为此,正则表达式提供了非捕获分组功能,非捕获分组只用于限定量词作用范围,不会捕获文本内容.
形式为将(...)改为(?:...), 碰到非捕获分组时编号不会递增
/(\d{4})-(\d{2})-(\d{2}) \1-\2-\3/.test('2020-01-02 2020-01-02'); //true
/(?:\d{4})-(\d{2})-(\d{2}) \1-\2/.test('2020-01-02 01-02'); //true 年份使用了(?:)被略过
一般来说,如果不使用反向引用功能的话,尽量使用非捕获分组
命名分组
仅依靠编号\1 \2 \3这样引用分组容易导致混乱,可以使用命名分组实现类似变量的功能,语法为\k<name>,在replace中则是$<name>
//反向引用
/(?<year>\d{4})-(\d{2})-(\d{2}) \k<year>-\2-\3/.test('2020-01-02 2020-01-02') //true
//match
'2020-01-02'.match(/(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/).groups;
//{year: "2020", month: "01", day: "02"}
//replace
'2020-01-02'.replace(/(?<year>\d{4})-(\d{2})-(\d{2})/,'$<year>年 $2月 $3日')
//"2020年 01月 02日"
四. 断言
断言只用来判断某个位置左侧/右侧的文本是否符合要求,本身并不匹配内容,常见的有单词边界、行起始/结束位置、环视这三类。
单词边界
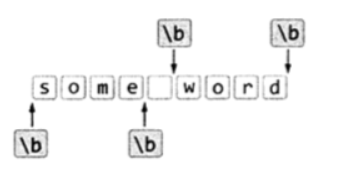
匹配一边是单词字符,另一边不是单词字符的位置 (单词字符指的是\w能够匹配的字符)符号为\b,示例如下
行起始/结束位置
^起始位置$终止位置
环视
环视用来表示: 在某个位置向左/右看,必须或不能出现指定的字符。与单词边界类似,环视本身不匹配字符。
| 名称 | 记法 | 方向 | 能否出现 匹配字符 |
|---|---|---|---|
| 肯定顺序环视 | (?=…) | -> |
true |
| 否定顺序环视 | (?!…) | -> |
false |
| 肯定逆序环视 | (?<=…) | <- |
true |
| 否定逆序环视 | (?<!…) | <- |
false |
<表示逆序,没有则表示顺序=/!:肯定/否定
示例: xshell中高亮当前路径,可以使用肯定逆序环视(?<=root@debian:).*?#标记出root@debian:/home#中的路径/home