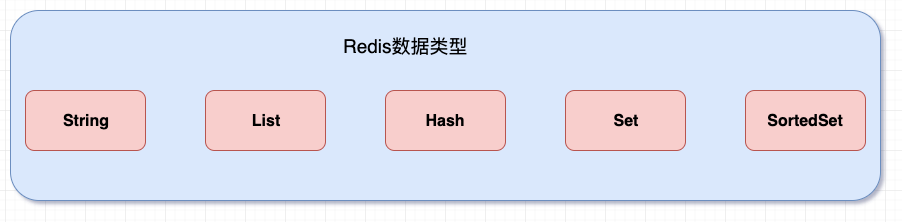
数据类型
Redis的数据类型包括以下五种:
1、 String:字符串类型
2、 List:列表类型
3、 Set:无序集合类型
4、 ZSet:有序集合类型
5、 Hash:哈希表类型
 Redis的5z种数据类型
Redis的5z种数据类型
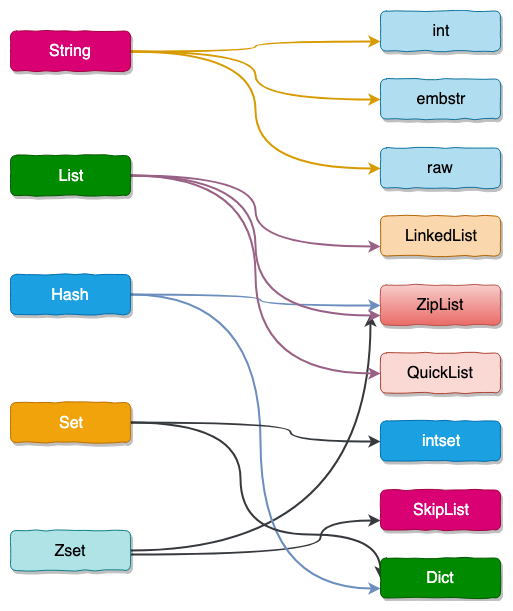
这几种数据类型只是redis提供给客户端使用的,每一种数据类型在不同情况下会使用不同的数据结构来存储数据。
127.0.0.1:6379> get key1
"hello"
127.0.0.1:6379> type key1
string
127.0.0.1:6379> type hash
hash
通过type命令得到的就是key值对应数据的数据类型。
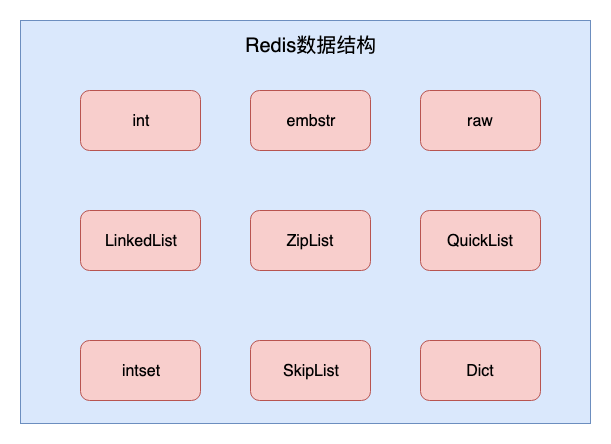
数据结构
Redis的数据结构(encoding)是用来存储上述五种数据类型的数据的。同一种数据类型的数据,在不同情况下会使用不同的结构来存储。
通过object encoding命令得到的就是key值对应数据实际使用的存储结构。
127.0.0.1:6379> object encoding key1
"embstr"
127.0.0.1:6379> object encoding hash
"ziplist"
 Redis数据结构
Redis数据结构
数据类型与数据结构关系
数据结构原理
SDS
Redis自己构建了一种名叫Simple dynamic string(SDS)的数据结构作为String字符串的底层实现。
127.0.0.1:6379> set key hello
OK
127.0.0.1:6379> get key
"hello"
此时redis中对应的存储形式为:
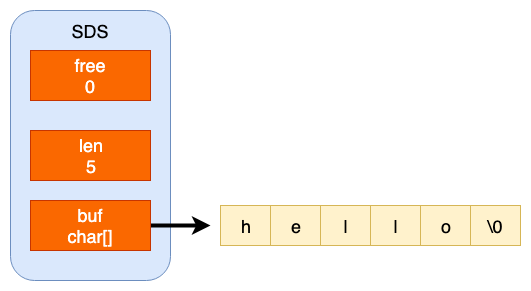
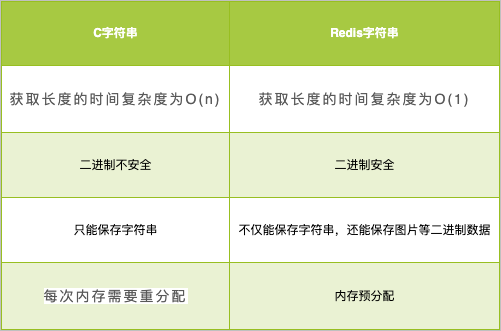
- c语言中的字符串并不会记录自己的长度,因此 每次获取字符串的长度都会遍历得到,时间的复杂度是O(n),而Redis中获取字符串只要读取len的值就可,时间复杂度变为O(1)。
- c语言中两个字符串拼接,若是没有分配足够长度的内存空间就 会出现缓冲区溢出的情况;而 SDS会先根据len属性判断空间是否满足要求,若是空间不够,就会进行相应的空间扩展,所以 不会出现缓冲区溢出的情况。
- SDS还提供 空间预分和 惰性空间释放两种策略。在为字符串分配空间时,分配的空间比实际要多,这样就能 减少连续的执行字符串增长带来内存重新分配的次数。
- 当字符串被缩短的时候,SDS也不会立即回收不适用的空间,而是通过
free属性将不使用的空间记录下来,等后面使用的时候再释放。 - SDS是二进制安全的,除了可以储存字符串以外还可以储存二进制文件(如图片、音频,视频等文件的二进制数据);而c语言中的字符串是以空字符串作为结束符,一些图片中含有结束符,因此不是二进制安全的。
LinkedList
当链表entry数据超过512、或单个value 长度超过64,底层就会将zipList转化成linkedlist编码,linkedlist是标准的双向链表,Node节点包含prev和next指针,可以进行双向遍历;还保存了 head 和 tail 两个指针。因此,对链表的表头和表尾进行插入的时间复杂度都为O (1) , 这是也是高效实现 LPUSH 、 RPOP、 RPOPLPUSH 等命令的关键。
ZipList
压缩列表(ziplist)是一组连续内存块组成的顺序的数据结构,压缩列表能够节省空间,压缩列表中使用多个节点来存储数据。
- ziplist是一块连续的内存空间,避免了不连续的内存碎片,内存利用率高。
- ziplist中的节点是一个接一个,每个节点没有保存指向前驱节点或者后继节点的指针,节省内存。
基本结构:
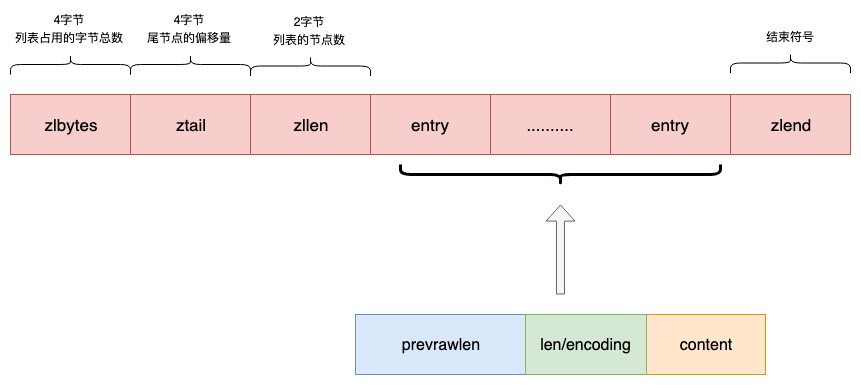
- zlbytes:4个字节,表示列表占用的字节总数。
- ztail:4个字节,表示尾节点的偏移量。得到尾结点的位置,就可以很容易计算出其他节点的位置。
- zllen:2个字节,表示列表中entry节点的数量。
- entry:列表节点。
- zlend:1个字节,是一个结束标记,值固定等于255。
Entry节点说明:
- prevrawlen:前一个节点占用的长度值。根据这个值得到前一个节点的起始位置。这样可以不用通过链表常用的next、prev指针来遍历节点,更加节省空间。
- len/encoding:记录了当前节点content占有的内存字节数及其存储类型,用来解析content。
- content:节点保存的实际的值。
ziplist能够节省内存空间,这也是它被设计出来的初衷。实际中我们知道,ziplist只适合用来存储少量数据,当数据量较大时Redis会使用其他数据结构,舍弃ziplist。那么ziplist劣势是什么呢?
连锁更新:
前面讲到prevrawlen保存的是上一个节点的长度,它占用字节数是不固定的,具体讲就是:
- 如果前一节点的长度小于 254 字节,则使用1字节来存储prevrawlen。
- 如果前一节点的长度大于等于 254 字节,那么将第 1 个字节的值设为 254 ,然后用接下来的 4 个字节保存实际长度。也就是变成了5个字节。


如果某个节点的内容发生变化,总体长度由<254变成了>=254,那么它下一节点的prevrawlen将由1字节保存变成5字节保存,如果这个变化又导致下一节点的总长度发生临界变化,如此反复,就会出现连锁更新。
由于ziplist连锁更新的问题,也使得ziplist的优缺点极其明显;ziplist被设计出来的目的是节省内存,这种结构并不擅长做修改操作。一旦数据发生改动,就会引发内存重新分配,可能导致内存拷贝。也使得后续Redis采取折中,利用quicklist替换了ziplist。
QuickList
我们已经知道了ziplist的缺陷,所以在Redis3.2版本以后,列表的底层默认实现就使用了quicklist来代替ziplist和linkedlist。
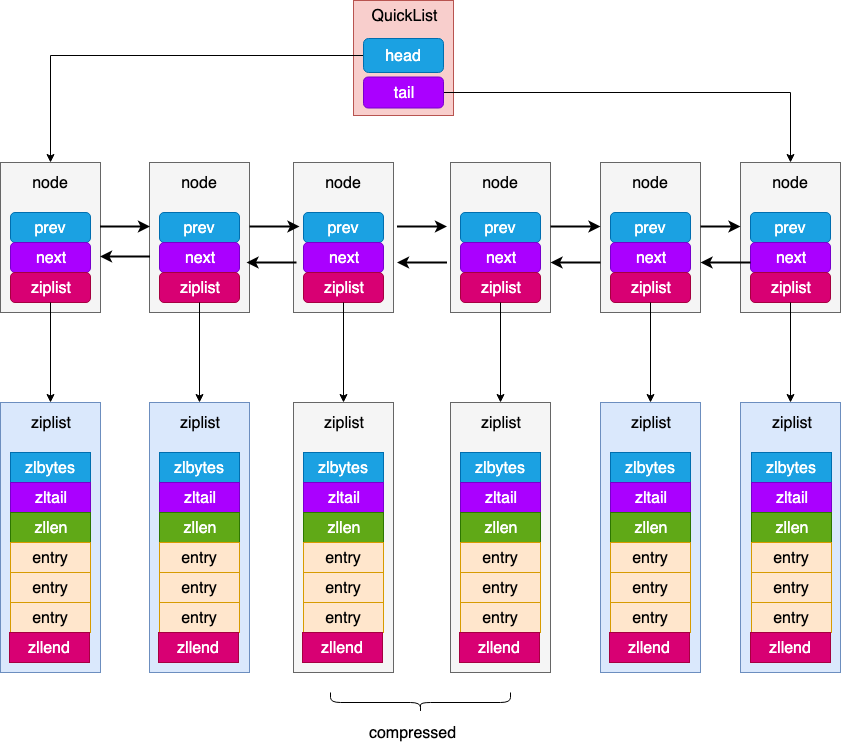
QuickList底层依然是ziplist,中间的节点是可以被压缩的,链表头尾数据的访问效率较高,时间复杂度为O(1),也就是常数级别的。
# Lists are also encoded in a special way to save a lot of space.
# The number of entries allowed per internal list node can be specified
# as a fixed maximum size or a maximum number of elements.
# For a fixed maximum size, use -5 through -1, meaning:
# -5: max size: 64 Kb <-- not recommended for normal workloads
# -4: max size: 32 Kb <-- not recommended # -3: max size: 16 Kb <-- probably not recommended # -2: max size: 8 Kb <-- good # -1: max size: 4 Kb <-- good # Positive numbers mean store up to _exactly_ that number of elements # per list node. # The highest performing option is usually -2 (8 Kb size) or -1 (4 Kb size), # but if your use case is unique, adjust the settings as necessary. list-max-ziplist-size -2 # Lists may also be compressed. # Compress depth is the number of quicklist ziplist nodes from *each* side of # the list to *exclude* from compression. The head and tail of the list # are always uncompressed for fast push/pop operations. Settings are: # 0: disable all list compression # 1: depth 1 means "don't start compressing until after 1 node into the list, # going from either the head or tail" # So: [head]->node->node->...->node->[tail] # [head], [tail] will always be uncompressed; inner nodes will compress. # 2: [head]->[next]->node->node->...->node->[prev]->[tail] # 2 here means: don't compress head or head->next or tail->prev or tail, # but compress all nodes between them. # 3: [head]->[next]->[next]->node->node->...->node->[prev]->[prev]->[tail] # etc. list-compress-depth 0
list-max-ziplist-size表示每个ziplist节点大小的限制。
list-compress-depth表示链表两边不被压缩的节点的数量。0表示都不压缩。
SkipList
Skip List(跳跃表)是一种支持快速查找的数据结构,插入、查找和删除操作都仅仅只需要O(log n)对数级别的时间复杂度,它的效率甚至可以与红黑树等二叉平衡树相提并论,而且实现的难度要比红黑树简单多了。
Skip List主要思想是将链表与二分查找相结合,它维护了一个多层级的链表结构(用空间换取时间),可以把Skip List看作一个含有多个行的链表集合,每一行就是一条链表,这样的一行链表被称为一层,每一层都是下一层的”快速通道”,即如果x层和y层都含有元素a,那么x层的a会与y层的a相互连接(垂直)。最底层的链表是含有所有节点的普通序列,而越接近顶层的链表,含有的节点则越少。
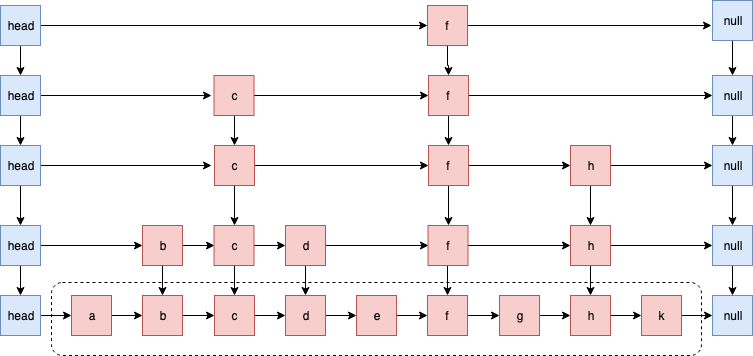
对一个目标元素的搜索会从顶层链表的头部元素开始,然后遍历该链表,直到找到元素大于或等于目标元素的节点,如果当前元素正好等于目标,那么就直接返回它。如果当前元素小于目标元素,那么就垂直下降到下一层继续搜索,如果当前元素大于目标或到达链表尾部,则移动到前一个节点的位置,然后垂直下降到下一层。正因为Skip List的搜索过程会不断地从一层跳跃到下一层的,所以被称为跳跃表。
Skip List还有一个明显的特征,即它是一个不准确的概率性结构,这是因为Skip List在决定是否将节点冗余复制到上一层的时候(而在到达或超过顶层时,需要构建新的顶层)依赖于一个概率函数。
Dict
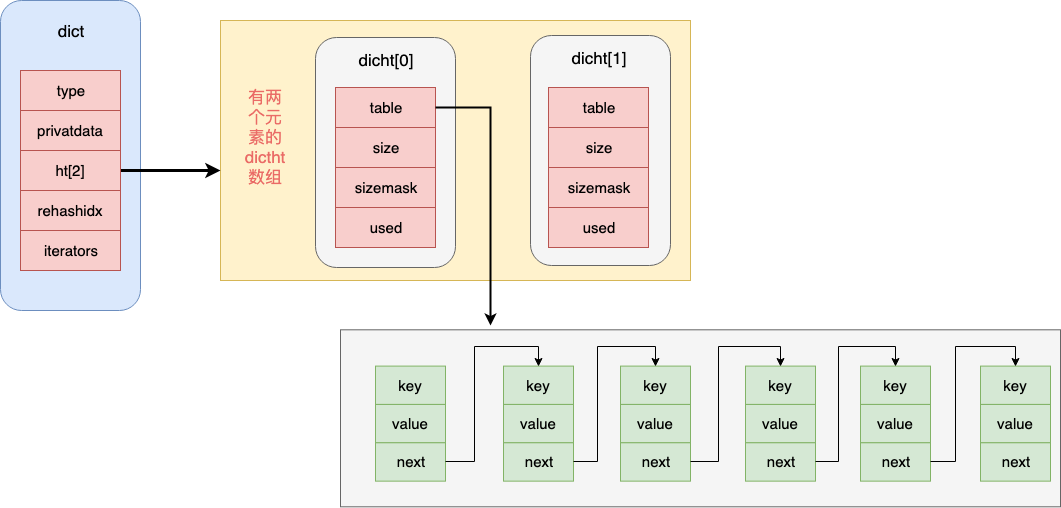
dict中有个dictht数组,包含两个ht元素。平常只有ht[0]有值,当需要进行rehash时,dictht[1]中才会出现数据。
渐进式rehash:
假如在rehash的过程中数据量非常大,Redis不是一次性把全部数据rehash成功,这样会导致Redis对外服务停止,Redis内部为了处理这种情况采用渐进式的rehash。
Redis将所有的rehash的操作分成多步进行,直到都rehash完成,具体的实现与对象中的rehashindex属性相关,若是rehashindex 表示为-1表示没有rehash操作。
当rehash操作开始时会将该值改成0,在渐进式rehash的过程更新、删除、查询会在ht[0]和ht[1]中都进行,比如更新一个值先更新ht[0],然后再更新ht[1]。
而新增操作直接就新增到ht[1]表中,ht[0]不会新增任何的数据,这样保证ht[0]只减不增,直到最后的某一个时刻变成空表,这样rehash操作完成。
本文使用 tech.souyunku.com 排版