
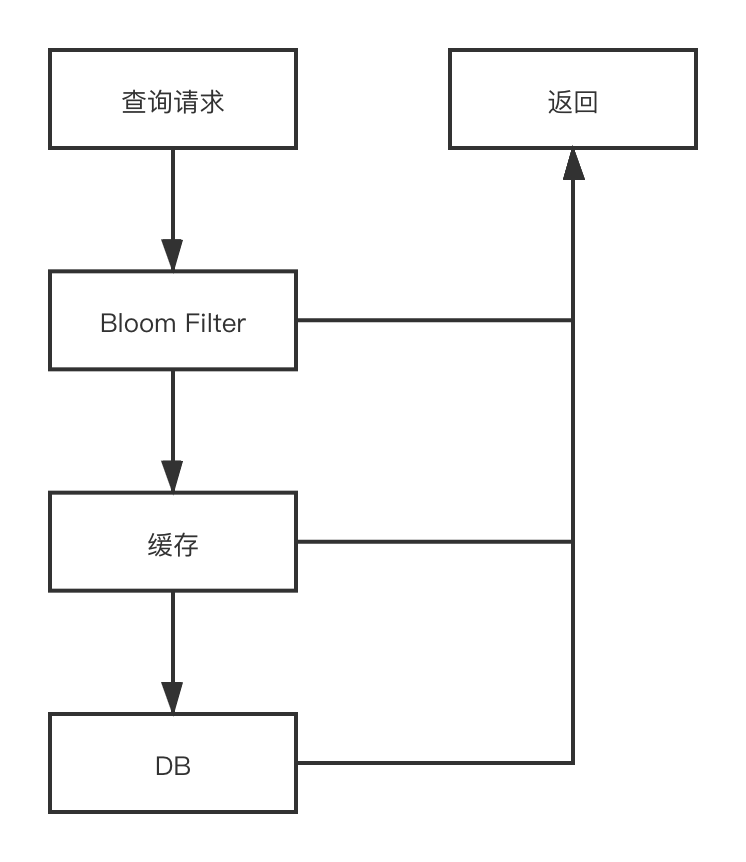
缓存作为DB前的一道防线,过滤了绝大部分DB请求,保障业务系统的高性能与高可用。
同样的,特别是高度依赖缓存的分布式系统,缓存设计如果不合理,轻则浪费机器资源,重则 1.缓存污染,即缓存与DB数据不一致,影响数据正常展示,若是在交易链路,则会造成资损;2.难以承载大流量,导致服务雪崩。
下面总结了分布式系统中,缓存设计的常见问题与相应解法。
1.缓存穿透
缓存穿透,即请求了缓存中不存在的数据,导致请求打到DB,造成DB负载变高。如果出现大量缓存穿透请求,一是说明缓存命中率低,浪费机器资源;二是会存在将DB连接打满、服务宕机的风险。
应对缓存击穿有两种常用方案:(1)对于无效数据,缓存中使用占位符存储;(2)使用布隆过滤器进行前置拦截。
1.1 缓存占位符
简单来说,当数据无效 or 不存在时,使用特殊占位符进行缓存。下一次请求来时,不需要走到DB,直接返回。
1.2 布隆过滤器(Bloom Filter)
如果无效数据量比较大,使用占位符的策略,会浪费大量内存资源。这种情况可以使用布隆过滤器。
布隆过滤器的原理:使用bitMap进行数据存储,使用多个hash函数计算数据位。hash计算出入参的下标,并标记为1。当计算出来的下标对应的bitMap都为1时,则认为该数据存在。反之,则不存在。
布隆过滤器的特性:
- 使用bitMap存储数据,内存占用极低;
- 能确定一个值一定不存在,但不能确定一个值一定存在(小概率事件,因为存在hash碰撞的因素)。满足缓存过滤的需求。
如下图所示,入参为商品productId,使用3个hash函数(H1,H2,H3)计算其hash值,作为bitMap的下标。
productId1,标志位为[0,4,7],product2标志位为[2,4,10]
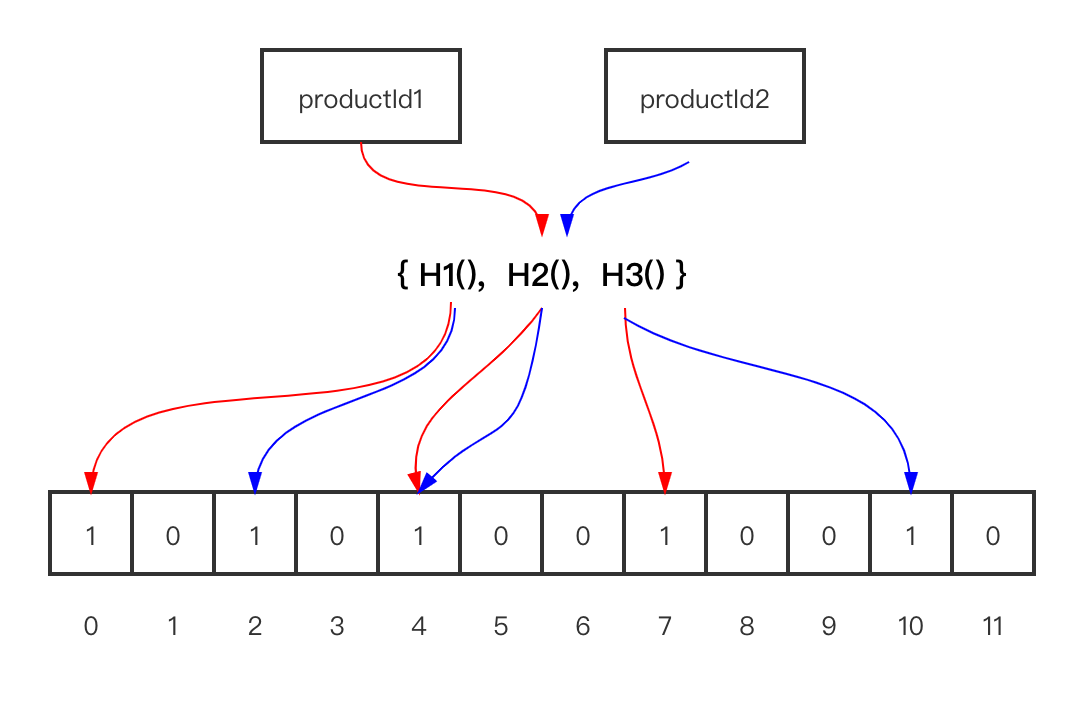
这时查询请求进来,查productId3,假设计算出bitMap下标为[2,4,9],对应占位为[1,1,0],则productId3不存在。
使用布隆过滤器作为缓存的前置过滤,可以有效过滤掉无效数据请求。
两种方案对比
占位符:代码实现简单,数据时效性高,内存占用较高,适用于无效数据量小的场景。
布隆过滤器:代码实现复杂,数据时效性低,内存占用低,适用于无效数据量大,且数据时效性要求不高的场景。
2.缓存击穿
缓存击穿,即某个热点缓存失效后(缓存过期),该热点key的请求直接打到DB,造成DB压力瞬间增大。
解决方案:(1)热点缓存永不过期;(2)加互斥锁
2.1热点缓存永不过期
一般是通过计算出逻辑上的过期时间,比如活动、商品过期时间endTime,再设置缓存过期时间为endTime,保证在逻辑过期时间内,缓存一直有效。
当然如果内存满了,缓存会启动淘汰机制,视情况会可能会淘汰永久缓存。相应解法如下:
方案一:做热点缓存隔离,热点缓存与普通缓存放在不同集群,内存容量不受普通缓存数据影响;
方案二:缓存不做永不过期设置,而是设置过期时间,同时业务代码加入缓存更新逻辑,在缓存过期前,更新缓存。实现方式可以是mq、延时mq、异步线程等。
2.2 互斥锁
查DB操作前加锁,同一时刻只能有一个请求打到DB,其他请求等待重试。该方案引入分布式锁,将DB压力转移到分布式锁上,实现简单,但存在请求过大时,等待时间过长,线程被打满的风险。
示例代码:
private finial static String QUERY_LOCK = "lock_"
public Object getDate(String key){
Object value = redis.get(key);
if (value == null) {
//设置分布式锁
if (redis.setnx(QUERY_LOCK + key, 1, time)) {
value = db.get(key);
redis.set(key, value, time);
redis.delete(QUERY_LOCK + key);
} else {
sleep(500);
return getDate(key);
}
}
return value;
}
3.缓存雪崩
缓存雪崩,即大量key在同一时间内同时过期,造成大量请求打到DB。
解法比较简单,在设置缓存时,在基础过期时间上,随机浮动加减时间,避免缓存在同一时间失效。同时可以在DAO层 or DB中间件 加入限流,避免瞬时大流量打垮DB。
4.缓存一致性
缓存一致性,即缓存数据与DB数据的一致性。引入缓存后,同一份数据分布在两处,由于网络IO、数据库事物、并发操作等因素,会造成缓存与DB数据不一致的问题。
而造成缓存数据不一致问题的主要原因,基本都是由数据更新+并发操作导致。 简单举例:
算了,感觉缓存一致性问题都能单开一章分析了。那么下面的小结咱还是留到后面再开新章节吧,感谢看到这里的各位。