泛型是什么?
在我们写代码的时候,经常都会看到类似于ArrayList<T>的代码,而这里的T既是泛型,泛型就是泛指一种类型的意思,也就是没有固定的类型,只有到使用的时候根据用户的需求才会最终确定下类型。
实际Java的泛型并不是真泛型,而是一种伪泛型,因为Java在编译时会进行类型擦除,要理解Java泛型,那么泛型擦除就必须掌握。而在运行时,JVM是不认识泛型这种东西的,所以在运行时,并没有泛型一说,泛型只有在编译时才有意义。
也就是说ArrayList<Integer>和ArrayList<String>在JVM中都是ArrayList类型,而ArrayList也称为原始类型。

该代码返回的结果为true,由结果可知,他们返回的类型的相同的,都是ArrayList类型。
但是在C#中的泛型是真泛型,即ArrayList<Integer>和ArrayList<String>是两种类型。
类型擦除
那么什么是类型擦除呢?
类型擦除就是编译器在编译Java代码的时候,会将泛型给擦除掉,如果泛型是无界的,那么将泛型替换为Object类型,如果泛型是有界的,那么则将泛型替换为第一个有界的类型。
泛型类
最常见的就是定义的类中存在泛型,我们看看类型擦除在类中是如何表现的。
- 无界泛型:
class Node<T> {
T element;
public T getNode(){
return element;
}
public void set(T t){
this.element = t;
}
}
对于这种无界的泛型,在编译器编译之后会变成什么样呢,根据我们上面的解释,它会将泛型T替换为Object
class Node {
Object element;
public Object getNode(){
return element;
}
public void set(Object t){
this.element = t;
}
}
- 有界泛型1:
对于有界泛型来说,就不是将泛型T直接替换为Object类型了,看如下代码:
class Node<T extends Comparable> {
T element;
public T getNode(){
return element;
}
public void set(T t){
this.element = t;
}
}
这段代码是一个有界的泛型,即泛型T的类型必须是Comparable类型或者是Comparable的子类类型,那么编译后的泛型将会被替换为Comparable
class Node<T extends Comparable<T>> {
Comparable element;
public Comparable getNode(){
return element;
}
public void set(Comparable t){
this.element = t;
}
}
- 有界泛型2:
如果在有界泛型的类型参数中,既有类,又有接口,比如A是类,B、C是接口
class Node<T extends A & B & C> {
T element;
public T getNode(){
return element;
}
public void set(T t){
this.element = t;
}
}
那么A就必须写在最左边,否则将会编译错误,并且泛型T也会被替换为A类型。
- 有界泛型3:
如果在有界泛型中存在多个类型参数的话,在类型擦除中,只会使用最左边的类型去替换泛型。
class Node<T extends Comparable<T> & Serializable> {
T element;
public T getNode(){
return element;
}
public void set(T t){
this.element = t;
}
}
该写法,泛型T会被替换为Comparable类型。
class Node<T extends Serializable & Comparable<T>> {
T element;
public T getNode(){
return element;
}
public void set(T t){
this.element = t;
}
}
但是,如果我们将两个类型调换一下,即将Serializable类型放在最左边,那么泛型T就会被替换为Serializable类型。
根据有界泛型2和有界泛型3的例子我们可以知道,对于有界的泛型来说,泛型擦除会使用第一个参数类型来替换泛型,而对于既有类,又有接口的参数类型,类必须写在第一个参数类型中,也就是类必须在接口之前。也就是会优先使用类的类型来进行替换,其次才会使用接口类型来进行替换。
泛型方法
泛型并不只能引用于类中,还可以运用于方法中。
public T getNode(){
return element;
}
对于非静态方法而言,类型参数可以是类中定义的,也可以是自定义的。
public <U> U get(U u){
return u;
}
与类的泛型使用类似,可以由一组类型参数组成,类型参数需要使用尖括号封闭,并且要放置于方法的返回值之前。该方法的作用是:接收一个U类型的参数,并且返回一个U类型的值。
而对于静态方法而言,类型参数只能使用自定义的,而不能使用类中定义的,类型参数必须放置于方法的返回值前面。
public static <T> int print(T t){
System.out.println(t);
}
至于为什么不能使用类中定义的,因为类中定义的泛型都是在创建对象的时候使用的,而静态方法是属于类的,而不属于任何一个类。比如:
class Node<T> {
T element;
public T getNode(){
return element;
}
public void set(T t){
this.element = t;
}
// 静态方法A,错误的写法
public static T get(){
return element;
}
//静态方法B,正确的写法
public static <T> T get(T t){
return t;
}
}
我们写代码时,可以Node<Integer>、Node<String>,那么静态方法中的T是Integer类型还是String类型呢?JVM是无法推断出来的,因为选择任何一种都是不正确的。
静态方法B中的T与类中的T并不是同一个泛型T,他们是互相独立的。
我们在使用泛型静态方法时,一般不需要直接写出泛型,编译器会根据传入的参数自动进行推断。
Node.<String>get("aaaa");
比如这段代码,我们可以省略尖括号中的类型参数,因为编译器会自行推断出来,等价于下面这句:
Node.get("aaaa");
多态与泛型
我们考虑这样一个情况:
class Node<T> {
T element;
public T getNode(){
return element;
}
public void set(T t){
this.element = t;
}
}
class MyNode extends Node<Integer>{
@Override
public void set(Integer t){
super.set(t);
}
}
考虑以下代码:
MyNode myNode = new MyNode();
myNode.setEle(5);
Node n = myNode;
n.setEle("abc");
Integer x = myNode.getEle();
该代码在编译期是可以通过的,但是在运行期将会抛出类型转换异常。导致整个异常发生是在第四行代码执行时将会发生一个类型转换,而整个类型转换将String转换为Integer,所以抛出异常。
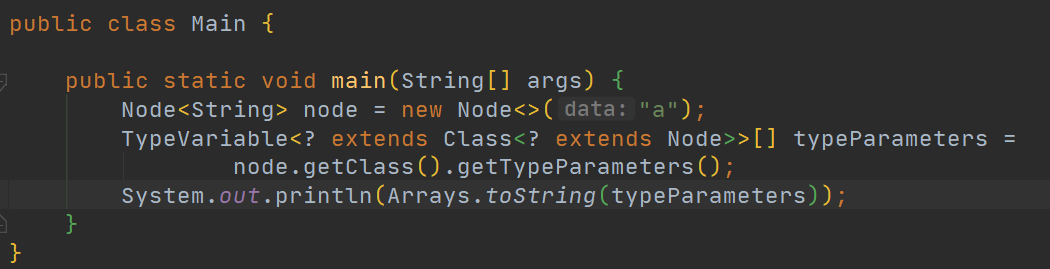

因为我们知道Node类型在编译时,会进行类型擦除,所以当我们使用一个静态类型为Node的变量去接受MyNode类型时,我们看到方法签名为set(Object t)的方法。
而在实际执行时,当我们传递一个字符串参数时,是执行的MyNode中的set(Object t)方法(与方法的分派有关,具体请查阅《深入理解Java虚拟机 第三版》8.3.2章节),但是 set(Integer t)不是已经重写了Node类中的set(T t)方法吗,但是实际上是没有重写的,因为Node类型中并没有签名为set(Integer t)的方法,即使编译之后,也只有一个set(Object t)方法,那么java开发团队是如何解决这个问题的呢?
实际上当出现此种情况的时候,编译器会在MyNode类中生成一个桥方法,该桥方法的签名就是set(Object t),而该桥方法才是真正重写了Node中的set(Object t)。
而桥方法内部是如何实现的呢,其实很简单:
public void set(Object t){
set((Integer) t);
}
所以MyNode类中的代码将是如下所示:
class MyNode extends Node<Integer>{
// 桥方法,由编译器生成
public void set(Object t){
set((Integer) t);
}
@Override
public void set(Integer t){
super.set(t);
}
}
所以当我们调用n.set("abc"),实际就是在调用set(Object t),并且对String类型的值进行了类型转换,转换为Integer,所以才会在运行时抛出类型转换异常。
无法使用泛型的场景
不能使用基本类型作为类型参数
class Pair<K, V> {
private K key;
private V value;
public Pair(K key, V value) {
this.key = key;
this.value = value;
}
// ...
}
当创建该类型的对象时,不能使用基本类型作为类型参数K,V的值。
Pair<int, char> p = new pair<>(1, 'a'); 编译时就会抛出错误
而只能使用非基本类型作为类型参数K,V的值。
Pair<Integer, Character> p = new Pair(1, 'a'); 正确的用法
不能创建类型参数的实例
public static <E> void append(List<E> list) {
E elem = new E(); // 编译时抛出错误
list.add(elem);
}
我们不能为类型参数创建实例,否则将会抛出错误。
我们可以使用反射来实现这种需求:
public static <E> void append(List<E> list, Class<E> c) {
E elem = cls.newInstance();
list.add(elem);
}
不能将静态类型字段的类型设置为类型参数
public class MobileDevice<T> {
private static T os; // 编译时抛出错误
// ...
}
因为静态字段是属于类的,而不是属于对象的,所以无法确定参数类型T的具体类型是什么。
比如有如下代码:
MobileDevice<Integer> md1 = new MobileDevice<>();
MobileDevice<String> md2 = new MobileDevice<>();
MobileDevice<Double> md3 = new MobileDevice<>();
因为静态字段os是被对象md1、md2、md3共享的,那么os字段的类型究竟是哪个呢?这是无法推断或者确定的,所以不能将静态类型字段的类型设置为类型参数。
不能将类型转换或者instanceof与参数化类型一起使用
public static <E> void rtti(List<E> list) {
if (list instanceof ArrayList<Integer>) { // 编译时抛出错误
// ...
}
}
其实理解这个也很简单,因为泛型在编译时将会被擦除,所以在运行时,并不知道类型参数是什么,所以也就无法判断ArrayList<Integer>、 ArrayList<String>之间的区别,因此运行时只能识别原始类型ArrayList。
而能做的只有使用一个通配符(通配符?表示任意类型)去验证类型是否为ArrayList:
public static <E> void rtti(List<E> list) {
if (list instanceof ArrayList<?>) { // 正确
// ...
}
}
通常,我们也不能将类型转换为参数化类型,除非是使用参数化类型是通配符进行修饰
List<Integer> li = new ArrayList<>();
List<Number> ln = (List<Number>) li; // 编译时错误
List<?> n = (List<?>)li; // 正确,可以省略(List<?>)
但是,在某种情况下,编译器知道类型参数始终有效,并允许强制类型转换
List<String> l1 = ...;
ArrayList<String> l2 = (ArrayList<String>)l1; // 正确
不能创建参数化类型的数组
List<String>[] arrays = new List<String>[2]; 编译时抛出错误
其实要理解这个约束也很简单,我们先举个简单的例子:
Object[] arr = new String[10];
arr[0] = "abc"; // 正确
arr[1] = 10; // 抛出ArrayStoreException,因为该数组只能接受String类型
有了上面那个例子,我们现在来看下面这个例子:
Object[] arr = new List<String>[10]; // 假设我们可以这么做,实际会抛出编译时错误
arr[1] = new ArrayList<String>(); // 正常执行
arr[0] = new ArrayList<Integer>(); // 根据上面那个列子,这里应该抛出ArrayStoreException
假设我们可以使用参数化类型的数组,那么根据第二个例子,在执行第三行代码时,就应该抛出异常,因为ArrayList<Integer> 类型并不符合List<String>类型,但是不允许这样做的原因是JVM无法识别,因为编译时会进行类型擦除。类型擦除之后,JVM只认识ArrayList这个类型。
不能创建、捕获参数化类型的对象
一个泛型类不能间接或者直接的继承Throwable类。
class MathException<T> extends Exception { /* ... */ } // 间接继承,编译时抛出错误
class QueueFullException<T> extends Throwable { /* ... */ // 直接继承,编译时抛出错误
在方法中不能捕获类型参数的实例。
public static <T extends Exception, J> void execute(List<J> jobs) {
try {
for (J job : jobs)
// ...
} catch (T e) { // 编译时抛出错误
// ...
}
}
但是可以在方法中抛出类型参数
class Parser<T extends Exception> {
public void parse(File file) throws T { // 正确
// ...
}
}
不能重载类型擦除之后拥有相同签名的方法
public class Example {
public void print(Set<String> strSet) { }
public void print(Set<Integer> intSet) { }
}
这两个方法在类型擦除之后的代码:
public class Example {
public void print(Set strSet) { }
public void print(Set intSet) { }
}
这两个方法的签名就一模一样了,这在Java语言规范中是不合法的。
不可验证的类型
如果一个类型的类型信息在运行时是完全可用的,那么这个类型就是可验证的类型,其中包括基本类型、非泛型类型、原始类型、绑定无界通配符的泛型。
不可验证类型的类型信息在编译时已经被类型擦除机制移除了。不可验证类型在运行时没有全部可用的信息,比如ArrayList<Integer>和ArrayList<String>,JVM在运行时无法识别这两种类型的不同之处,JVM只认识ArrayList这种类型。所以Java的泛型是伪泛型,在编译时才有用。
堆污染
堆污染发生的情况是将一个具有类型参数的变量指向一个不具有类型参数的对象。
public class Main {
public static <T> void addToList (List<T> listArg, T... elements) {
for (T x : elements) {
listArg.add(x);
}
}
public static void faultyMethod(List<String>... l) {
Object[] objectArray = l; // 有效
objectArray[0] = Arrays.asList(42);
String s = l[0].get(0); // 抛出ClassCastException
}
}
当编译器遇到可变参数的方法时,编译器将会把可变形式参数转换为一个数组。但是,在Java语言中,无法创建带有参数化类型的数组(在无法使用泛型场景中的第五个场景有描述)。我们拿addToList方法来描述,编译器会将T...elements转换为T[] elements,但是,由于存在类型擦除,最终,编译器会将T...elements转换为Object[] elements,因此,这里就可能产生堆污染。
我们看到faultyMethod方法,这里的可变参数l赋值给类型为Object[]的变量是有效的,因为变量l经过编译器编译后就是转换为List[]类型,因此我们可以往里面放置任何该类型或者该类型的子类类型的对象,因为类型已经被擦除了,所以我们可以放置任何List类型的值进去,这里就出现一个数组对象中,既可以放入List<String>的对象,也可以放入List<Integer>,或者其他类型。这里就出现了堆污染。
禁止不可验证形参的可变参数发出警告
如果你能保证你的可变参数不会出现转换错误,那么就可以添加@SafeVarags注解来取消警告的出现。
也可以添加@SuppressWarnings({"unchecked", "varargs"})注解来取消警告。但是这必须建立在你能确保自己的代码安全的情况下才能添加。
思考
类型擦除实验
我们现在来下面这段代码:
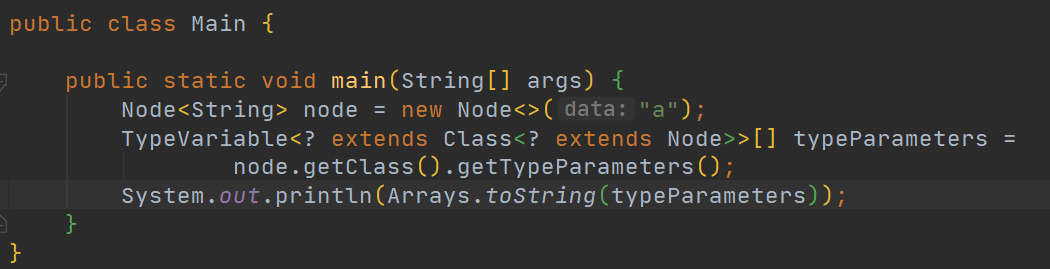
这段代码是通过反射来获取Node类型的参数类型,之前不是说在编译时不是会进行类型擦除吗,那么JVM是怎么在运行时还能获取到它的参数类型的。
我们可以通过反编译来看看,反编译之后的class文件是怎么样的。我们先反编译Node文件:
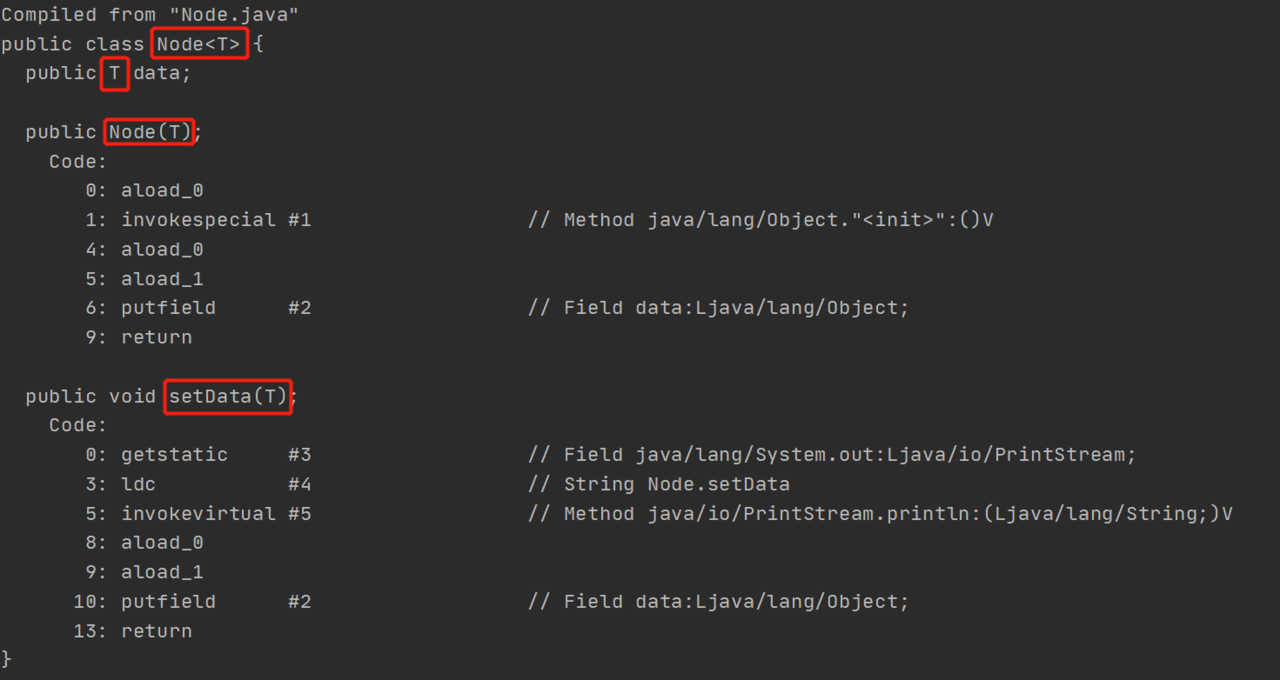 我们可以看到,这里并没有将T擦除,并替换为
我们可以看到,这里并没有将T擦除,并替换为 Object类型。所以JVM才能通过该类型信息获取到参数类型。
那么类型擦除是发生在哪里呢?
我们再来看另外一段代码就能明白了:
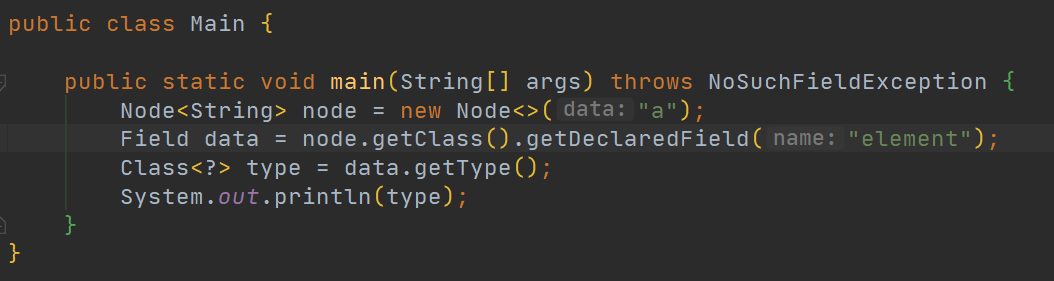 我们这里获取了Node中的element字段的类型:
我们这里获取了Node中的element字段的类型:

这里打印出来的结果就是Object类型。我们可以给Node类型的参数类型添加一个下界,让它继承Comparable接口,然后再打印一下类型:
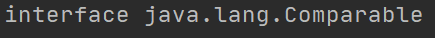 通过这两个例子可以说明,类型的擦除并不会发生在泛型声明上,而是发生在泛型的使用上。
通过这两个例子可以说明,类型的擦除并不会发生在泛型声明上,而是发生在泛型的使用上。
参考文献:
1、 Oracle文档