前言
我们都知道在C、C++、Java等语言中,都是以方法为单位来执行代码的。比如,C需要以一个int main()函数作为执行的初始方法,Java也需要一个public static void main(String[] args)作为代码的执行方法。然后以该方法作为开端,将会在后续中调用越来越多的方法,来完成各种各样不同的事情。
本编内容就是以CPU调用层面来理解函数调用在CPU中是如何工作的,因为该篇内容会包含大量的汇编内容,所以最好需要一些汇编知识。当然,我也会解释用到的汇编指令。
本篇内容是建立在X86_64机器语言上的,也就是我们平时下载软件时,都会看到在linux版本中有一个X86_64版本,而该版本也是大多数人会选择下载的版本。也可以说X86_64是CPU所能使用的一种指令集。
而本篇内容也会根据一个较为简单的C代码进行讲解,因为复杂的代码反而会提高理解的难度。代码如下:
#include <stdio.h>
int static add(int i, int j){
int x = 3;
int y = 4;
int sum = x + y + i + j;
return sum;
}
int main() {
int x = 1;
int y = 2;
int z = add(x, y);
return z;
}
该代码有两个函数main()和add(),非常简单,基本拥有一门语言的使用经验,都能看得懂。
如何编译代码
我们写好了源代码,但是该代码是不能直接运行的,因为CPU并不认识我们所写的东西,我们需要进行编译,将代码编译成CPU认识的二进制数据,CPU才能根据这些数据来执行。
我在ubuntu上通过gcc来编译。
安装编译工具
编译工具毫无疑问就是gcc了
安装gcc,执行以下命令即可。
sudo apt-get install gcc
一般gcc都会默认安装的,如果不确定的话,可以执行以下命令来确定是否安装
gcc --version
如果打印出了版本号,那么就说明安装了。
如何进行编译
我们需要使用gcc进行编译的话,那么就要使用到gcc的命令
gcc main.c -g -o main
其中main.c是存放该源代码的路径,既可以是相对路径也可以绝对路径,我们通过该命令可以生成一个可执行文件main。
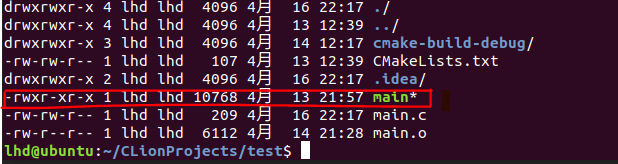
其中红色方框的就是可执行文件,也就是我们通过命令生成的那个文件,我们等下就需要执行它。
如何调试代码
我们虽然编译好了代码,但是我们目前还没有工具去执行/调试这个编译好的代码。所以我们还需要安装一个调试工具,类似于debug一样的工具,而这里我会使用比较原始的gdb进行调试,还有很多其他的工具也可以进行调试,比如具有可视化界面的nemiver、gdb的增强版cgdb等。
安装调试工具
安装调试工具也非常的简单,执行以下命令即可
sudo apt-get install gdb
该工具也是默认安装的了,可以使用以下命令来确定是否安装
gdb --version如果打印出了版本号,则说明安装了。
如何进行调试
调试代码比较麻烦,我会先在这里列出所需要用到的gdb命令,然后对每一个命令进行说明,如果阅读过程中遇到不认识的命令可以到此处进行查阅。
gdb main:该命令表示对该main可执行文件进行调试。start:我们执行完上面那条执行之后,依然不能进行调试,我们需要执行该命令,来开始执行代码的调试。该命令表示开始执行代码。next:该命令类似于我们的单步执行,输入一次该命令就是执行一条代码,可以简写为ndisassemble /rm:该命令用于展示反汇编代码,我们可以通过该命令查看到我们所写的C代码的汇编代码。/m表示源代码和汇编代码一起排列,/r表示可以看到16进制代码,可以简写为disasinfo register:改命令可以查看此刻寄存器中的值,info可以简写为i,register可以简写为rstep:也是单步执行,只不过该命令表示在我们遇到一个函数时,我们会进入到该函数中,如果直接next则会直接跳过我们遇到的函数。可以简写为slist:该命令查看源代码,可以简写为lx /nfu:该命令比较复制,它可以查看内存单元。n表示要显示的内存单元的个数,可以是直接十进制数f表示显示方式,可取如下值x:按十六进制显示变量d:按十进制显示变量u:按十进制显示无符号整型o: 按八进制格式显示变量t:按二进制格式显示变量- …….
u表示一个地址单元的长度,可取如下值b:表示单字节h:表示双字节w:表示四字节g:表示八字节
p var:表示要查看的变量的值,其中var是需要查看的变量名,如果要查看变量的地址,可以使用p &varq:该命令表示退出调试
方法调用过程分析
我会通过gdb调试来对代码进行一点点的解析,主要是对汇编代码的解析,同时,我也会解释汇编指令的作用,让大家不需要再自行查找资料。
首先我们通过gdb main进入到调试,然后通过start开始调试:
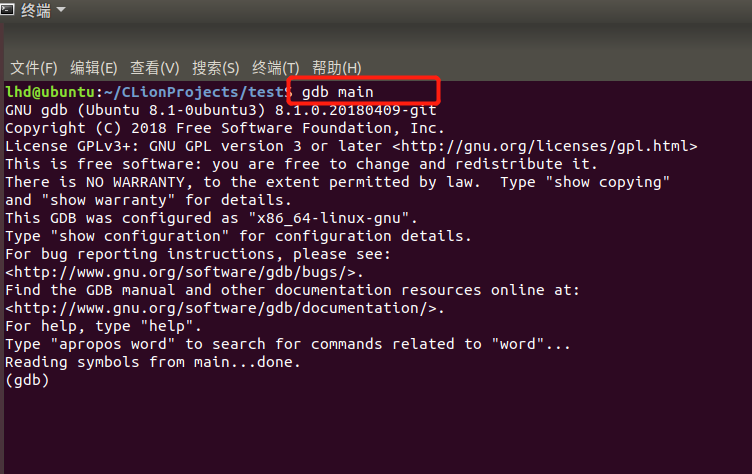
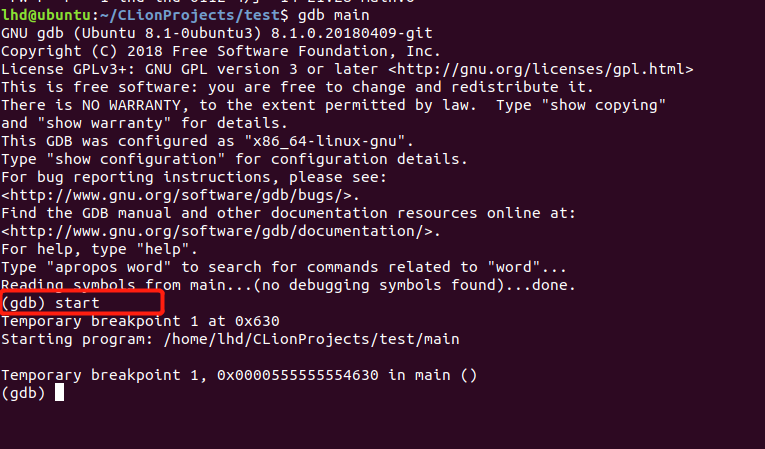
此时我们就可以通过之前提到过的命令开始进行调试了。
局部变量
首先我们先看一下main中的汇编代码,我会对汇编代码进行解释:
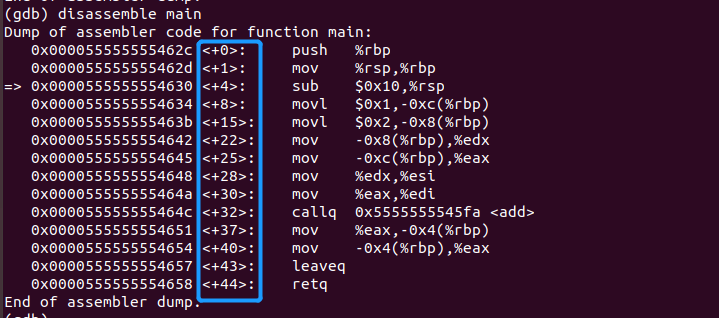
蓝色方框相当于代码的偏移量。
首先我们看到第1行代码,push %rbp,其中%rbp表示一个寄存器,在CPU中存在很多寄存器:
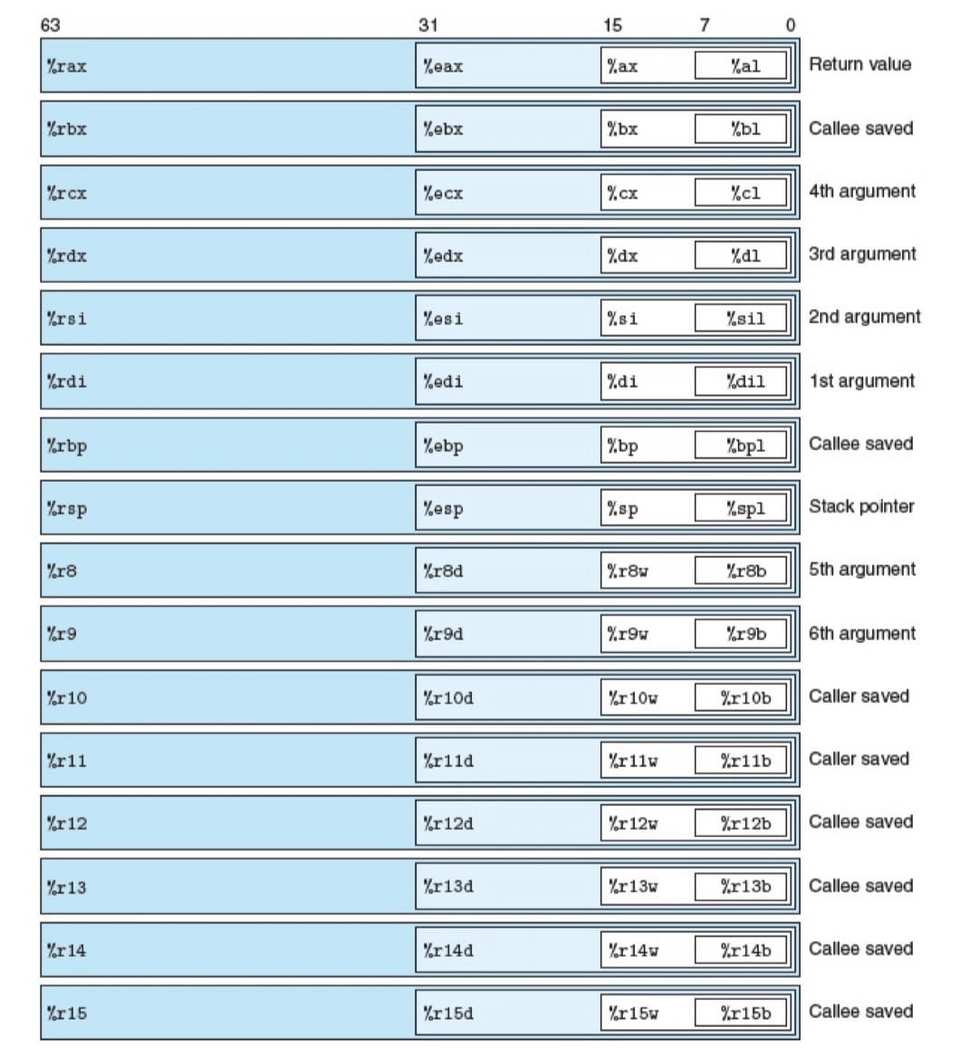
图片来自《深入理解计算机系统 第三版》3.4节。
从该图可以看出,CPU中一共存在16个寄存器,每个寄存器都可以存储最多64bit的数据,并且每个寄存器都有一个名称,其中我们通过对同一个寄存器使用不同的名称,从而对寄存器的的哪一部分字节进行操作,比如:%eax,那么我们就是操作第一个寄存器的低32位;%ax,那么就是操作第一个寄存器的低16位;%rbx,那么就是操作第一个寄存器的全部64位。操作可以是写入,也可以读取。
push指令有什么作用呢,该指令有一个操作数,其实它就是将操作数的值压入栈中,而栈其实就是内存中的一块连续的内存区域,但是栈的数据是从高地址开始,向低地址压入数据。
那么CPU怎么知道这个栈的地址在哪里呢?是通过%rsp寄存器,该寄存器存储了栈顶的地址,我们知道使用%rsp是可以存储64bit数据的,而我们的系统是64位的,所以刚刚好可以存储一个64位内存地址。当我们要往栈中存放数据的时候,首先会先改变%rsp寄存器的地址,因为是向低地址扩展,所以我们需要减去一个数值,然后再将数据存放到扩展的内存中去。
比如:我们要往栈中存放一个0x0123H,首先%rsp = %rsp - 2,因为该数据只有两个字节,所以只需要移动两个内存单元,然后再将0x0123H放入扩展的两个内存单元中。一个内存单元为一个字节。
第一条汇编push %rbp:
通过上面的知识,我们知道该指令就是将%rbp寄存器中的值入栈,%rbp的值存放的是每一个栈帧中栈底的地址。一个方法在栈中就对应一个栈帧。所以这条指令在这里就是将上一个栈帧(调用者)的栈底地址入栈,这么一看,main()方法岂不是也有调用者,是的,main()方法其实也是由一个__start()方法进行调用的,而这个方法是在编译的时候自动添加进去的。
第二条汇编mov %rsp,%rbp:
mov指令包含两个操作数,分别是源操作数、目的操作数mov src, desc,也就是将寄存器%rsp中的值传递进%rbp,类比成高级语言就是一个赋值操作%rbp = %rsp。不同的指令集的源操作数和目的操作数不同,比如8086的指令集中的操作数是mov desc, src,具体应该看指令集的手册。
刚刚我们知道%rsp的寄存器保存着栈顶的地址,在这里就是将栈顶的地址存入%rbp中,这也是为什么一开始要让%rbp寄存器中的值入栈,因为如果不入栈,那么原来的值就会被覆盖,存入栈中就可以保存原来%rbp寄存器中的值,到时候该mian()方法执行完之后就可以从栈中恢复%rbp的值。
我们使用i r查看执行完这条指令,寄存器的情况:
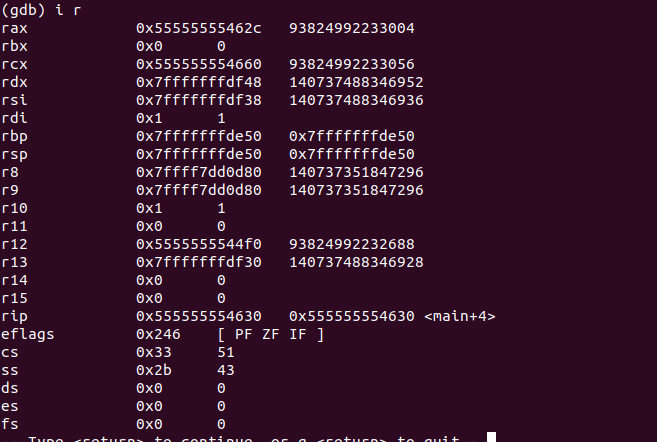
左边是寄存器的名称,中间就是每个寄存器中存放的值,该值是16进制显示,右边还有一个值,不是说寄存器可以存放两个128bit的数值,右边的值只是显示10进制的值。可以自行换算一下。我们一般只看中间的值即可。
当执行完这条指令的时候,我们可以看到%rbp、%rsp的值都是0x7fffffffde50,也说明了栈顶的地址是0x7fffffffde50。
第三条汇编sub $0x10, %rsp:
sub指令是减法指令,对应的是add指令,也是具有两个操作数,这条指令翻译成高级语言就是%rsp = %rsp - 0x10。这里就是将%rsp寄存器的值减去16,因为刚刚说过,栈的空间使用情况是从高地址开始使用,向低地址扩展,而%rsp寄存器存放的是栈顶的地址,所以如果要使用栈,就必须使%rsp寄存器指向的地址比原来小。所以这条指令扩展了16个字节的内存,供后续使用。
根据上一条指令中的值,我们通过计算可以得出此时%rsp的值应该是0x7fffffffde40。我们通过i r指令验证一下:
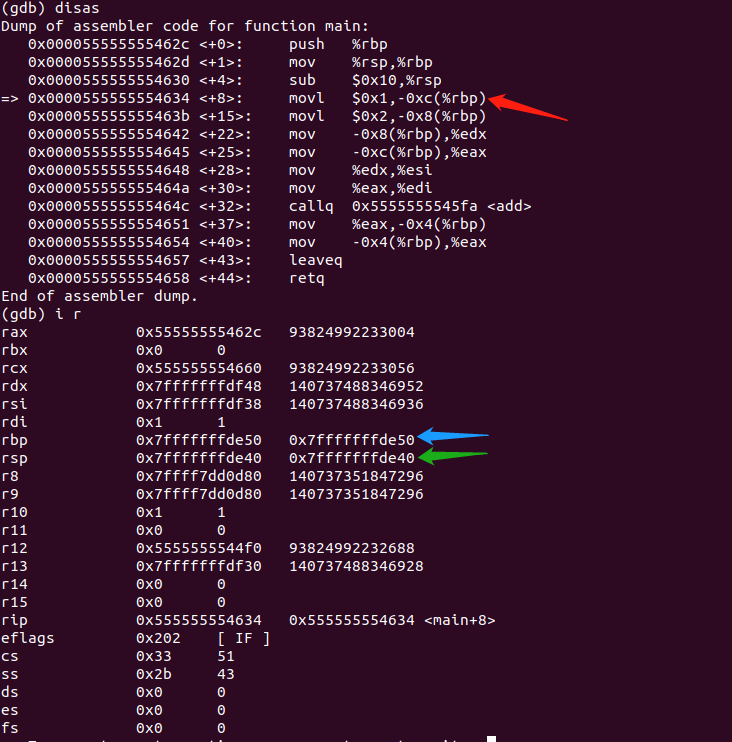
我们先打印出汇编代码,可以发现此时代码停在了<+8>这一行,通过左边的小箭头就可以知道。蓝色箭头和绿色箭头分别指向寄存器%rbp、%rsp,果然跟我们计算出来的一样。
第四条汇编:movl $0x1,-0xc(%rbp)
这条指令是不是跟mov指令很像呢,它实际上是对mov指令的一种扩展,movl指令是传送双字的意思,通俗的说就是它会操作给定内存块的低32位,同时将高32位设置为0。扩展指令还有几个:
| 指令 | 描述 |
|---|---|
| movb | 传送字节 |
| movw | 传送字 |
| movl | 传送双字,只有该指令会将高位置0 |
| movq | 传送四字 |
| movabsq | 传送绝对的四字(不知道绝对是什么意思) |
上面我们说到%rbp寄存器里面存储了地址,但是在这里用了一个()将寄存器包裹了起来,这个括号是有特殊作用的,它的作用就是取寄存器中地址的值,这里比较绕,通俗一点解释就是,这里不再是直接取寄存器的值,而是取寄存器中的值作为地址,然后再在内容中取该地址中的内存单元。学过C语言的都知道,这不就是指针嘛,对的,确实可以用指针来理解,这里%rbp就可以看出是&addr,而(%rbp)看成是*addr。
那么括号前面的数字又有什么作用呢,我改写一下就知道是做什么的了:
-0xc(%rbp) => (%rbp + -0xc)
也就是先对寄存器中的地址做一次减法得到一个新的地址,然后再取该地址中的内存单元。根据第三条指令中的图我们可以知道%rbp存放的地址是0x7fffffffde50,那么得到的新地址就是0x7fffffffde44。所以整个指令就是往得到的新地址开始的4个内存单元存放了一个0x00000001。
我们可以查看0x7fffffffde44内存单元中的数据来验证一下是否如此:

我把该地址上下相邻的地址内容都一起打印出来了,方便对比。
注意红色方框部分,这就是我们存放的内存单元,这里要特别特别特别注意的一点是,%rbp寄存器存储的地址是栈的地址,而栈的使用地址的方式是从高向低使用的,所以我们先向高位填充数据,然后再向低位填充数据。所以将0x00000001依次将高位的数据存入高地址,低位存入低地址。
所以该指令也是对应C代码中的`int x = 1;这条赋值语句。
第五条汇编:movl $0x2,-0x8(%rbp)
该指令与第四条指令作用一样,我们计算出新的地址是0x7fffffffde48

我们可以看到该地址中的值就是0x00000002。
我们通过第四条指令和第五条指令可以得出一个结论:方法中的局部变量是存放在栈中的。因为这两条指令对应的语句是int x = 1;、int y = 2;,而变量x,变量y都是属于局部变量。
紧接着的第六条指令到第九条指令都是简单的赋值操作,这里将不会详细的解析,可以自行根据上面讲解的只是自行推断。
参数传递
这里要讲解的是,这四条指令的作用是用于参数传递的。
因为第十条指令是一个callq 0x5555555545fa <add>,该指令的主要作用是调用一个函数。将会在稍后详细讲解该指令的作用。
我们通过C代码可以知道,我们在main()函数中调用了add(int i, int j)函数,该函数接受两个参数。那么调用add()函数的时候,参数是如何传递给add()函数的呢?
我们首先观察前两条指令,观察他们的源操作数,发现这里就是之前讲解的存放局部变量的地方,而我们的代码也确实是将局部变量传递给了add()函数,所以这里将局部变量x、y的值传送给%edx寄存器、%eax寄存器。
然后再观察后两条指令,他们只是将%edx、%eax中的值传送给了%esi、%edi。为什么要使用另外的寄存器存放整个值呢?其实是因为在指令集中规定,如果参数小于7个,那么参数按照传递顺序依次放入寄存器rdi、rsi、rdx、rcx、r8、r9。因为这里只有两个参数,所以两个参数就只能通过寄存器rdi、rsi进行传递。
那么如果参数的数量超过了6个怎么办?如果参数超过了6个,那么超过的部分将会通过栈进行传递。注意:只有超过的部分才会压入栈中。也就是超过的那部分的参数将会压入栈中。
函数调用
当参数都已经存入寄存器或者栈中之后,就可以进行函数调用了。
我们看到紧接着的汇编指令是:callq 0x5555555545fa <add>
我们遇到的一个新的指令callq,该指令接受一个操作数,操作数是一个内存地址。
首先我们要知道CPU是如何执行一条一条指令的?除了上面的表格列出的16种寄存器之外,CPU还有一些用于特殊目的的寄存器,其中一个就是rip寄存器(俗称PC寄存器),该寄存器的作用是存储下一条指令的地址。
那该寄存器是如何存储下一条指令的地址的呢,我们首先来看一下一个比较详细的汇编代码:disas /r,该指令会打印出每一条指令所占用的字节数。
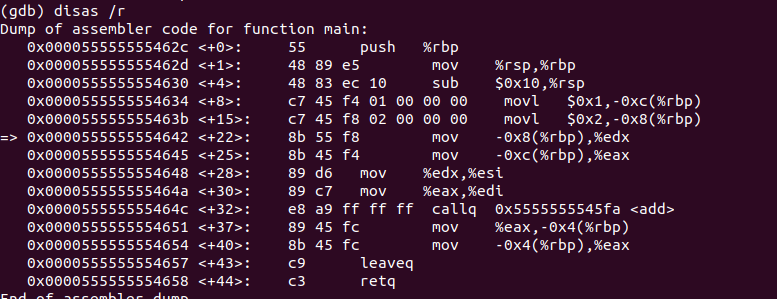
当CPU获取到一条指令的时候,它并不会立马执行,而是先把当前PC寄存器中的地址增加当前获取到的指令的字节数,下一条指令的地址 = 当前pc寄存器的地址 + 当前获取到的指令的字节数,当改变完PC寄存器中的地址之后,才会开始执行取到的指令。
举个例子:
假设PC寄存器当前存放的地址是0x0000555555554642,CPU先去该地址中取出要执行的指令mov -0x8(%rbp),%edx,通过图片可知该指令的长度为3个字节。CPU获取到指令之后,就会先改变PC寄存器存放的地址0x0000555555554642 + 3 = 0x0000555555554645,所以PC寄存器此时存储的就是下一条需要执行的指令的地址0x0000555555554645。然后CPU开始执行取出的指令。
回到我们的callq指令上,根据上面的知识,我们知道CPU在取出callq 0x5555555545fa <add>指令后,会先修改PC寄存器的值为0x000055555555464c,然后CPU会执行该指令。
CPU执行该指令时在做什么呢,我们可以将该指令拆开来看:
1、 sub 0x8, %rsp
2、 push %rip
3、 mov 0x00005555555545fa,%rip
当CPU执行call指令的时候,首先会将栈顶的指针向低地址移动8个字节,相当于扩展了8个字节的内容,然后将当前rip寄存器中的值压入栈中,也就是存入刚刚扩展的8个字节的内存单元,最后改变%rip寄存器的值为操作数的值。
而0x00005555555545fa就是add()函数第一条指令的地址,我们可以打印该函数的汇编,验证一下:
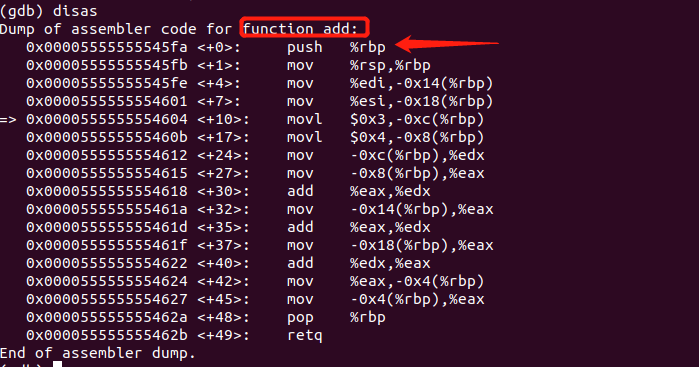
根据红色方框我们可以知道是add()的汇编代码,我们看到第一条指令的地址恰好是call指令的操作数。
我们现在来思考另外一个问题,为什么要先把rip中的地址入栈?我们都知道被调用函数执行完成之后,需要返回到调用函数中继续执行。所以我们可以把调用函数的下一条要执行的指令地址入栈,等被调用函数执行完成后,将该入栈的指令地址放入到rip中即可继续执行调用函数的后续指令了。
这里补充一下push指令的解析,假如执行的是push %rbp,可以将该指令拆分成以下指令来理解:
1、 sub 0x8,%rsp
2、 mov %rbp,0x8(%rsp)
首先会扩展栈的内容,扩展的大小是根据操作数的位数来决定的,因为这里是操作rbp,所以这里操作的数据是64位,所以需要扩展8个字节,如果是操作ebp,那么只需要扩展4个字节即可。然后会将%rbp寄存器的内容入栈。
后续的指令都是跟之前的指令类似。大家可以自行去分析。
函数返回
这里要着重解释的就是被调用函数是如何返回到调用函数中的,并且可以将返回值也传递回去。
pop %rbp指令,该指令与一开始的push %rbp指令是一对的,它将栈中的数据弹出至该寄存器中。我们可以看到在该代码中并没有扩展%rsp的地址,只是通过栈中的内存地址来存放局部变量,因为栈也只是一块可以使用的内存地址而已。所以这段代码,整个过程中%rsp和%rbp中存储的地址都是相同的。
pop %rbp可以拆分为以下代码来理解:
1、 add 0x8,%rsp
2、 mov -0x8(%rsp), %rbp
所以这里取出来的就是调用函数的栈顶的地址。
函数的返回值是通过%rax寄存器来进行传送的,所以return后面的返回值都是放入到%rax中,如果寄存器放不下,那么就会存入栈中,然后将存放返回值的地址存入寄存器中,也可以存入其他内存中。
最后来说一下retq指令,我们可以拆分该指令为以下指令:
1、 add 0x8,%rsp
2、 mov -0x8(%rsp),%rip
该指令就是将之前存入到栈中的返回地址存入PC寄存器中,让寄存器可以回到原来的函数中执行。
栈结构
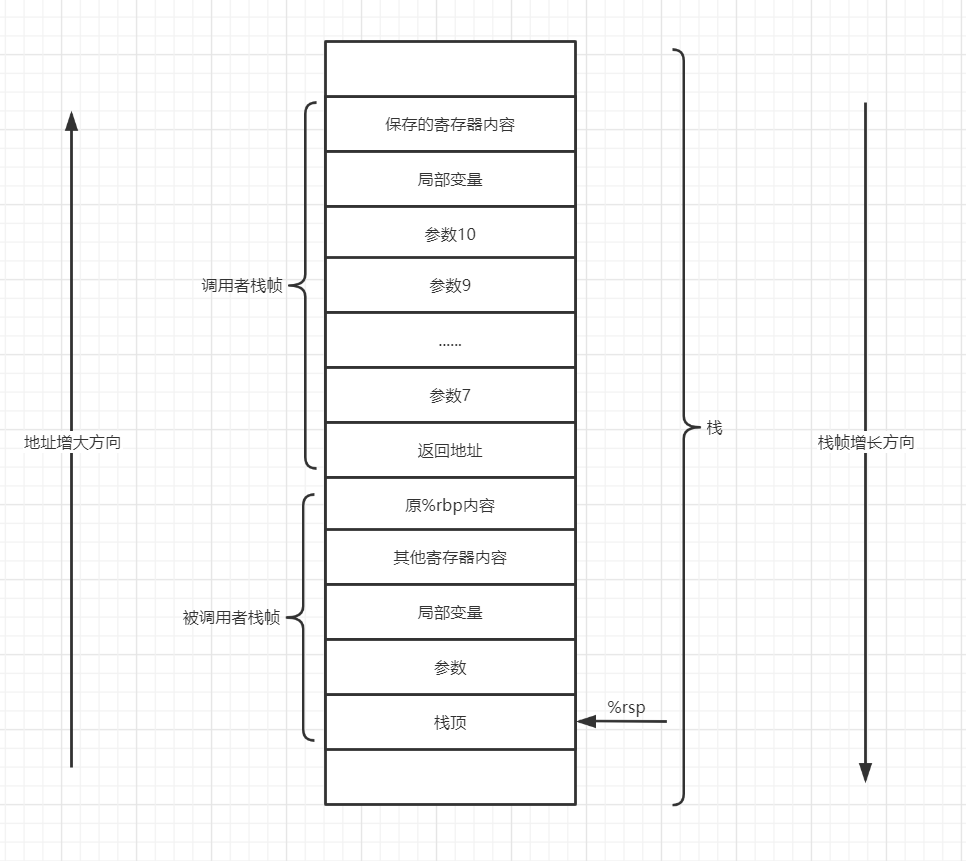
我们上面说了那么多,但是都没有一个完整的栈结构,所以我们先画一个栈结构:
扩展
因为我目前主要的语言是Java,所以我会拿Java虚拟机(JVM)来对比。因为Java虚拟机也可以看成是一个虚拟的计算机。
在JVM结构中,也存在一个PC寄存器,该PC寄存器也是存储下一条指令的地址,跟%rip寄存器是完全一样的道理,所以如果理解了CPU是如何执行一条指令的,那么JVM中PC寄存器的原理和作用也就能理解了。
那么真实的计算机跟JVM有什么区别呢?
我们根据上面的知识可以知道计算机执行一个方法,做一些计算、逻辑操作的指令时,源数据都是通过寄存器进行获取,并且计算结果存储在寄存器中的,这就是基于寄存器的一种执行模型。
而JVM中并不是基于寄存器的执行模型,而是基于栈的执行模型。看过《深入理解Java虚拟机》的都知道,JVM的每个线程都会有一块区域,叫做虚拟机栈,该虚拟机栈跟上面说到的栈具有同样的作用,都是在执行方法的时候会生成一个被调函数的栈帧,栈帧中存放着相关的信息。但是JVM执行计算、逻辑操作的源数据并不是通过寄存器来获取并存储的,而是通过栈帧中的一个叫做操作数栈来操作的,所有的数据都需要经过操作数栈才能进行操作。
其实万变不离其宗,不管上层怎么变,底层的原理终究是不变的。都是换汤不换药,所以掌握了底层的原理对学习一些新技术的帮助是很大的,短期可能并没有什么效果,但是长期下来,帮助一定是很大的,所以该学还是得学。
参考资料
[1] 王爽.《汇编语言》 清华大学出版社
[2] Randal E.Bryant / David O’Hallaron.《深入理解计算机系统 第三版》机械工业出版社