前言
- 这一阵子,一直苦于没有素材,也是懒,因此沉寂了一段时间,一直希望博文,除了一些基础知识的积累,还能对这个知识点附加一些笔者自己的理解,继续努力把~
- 作为一个业务开发者,涉及到大数据处理与分析的场景也是和相关业务高度相关的,这里也想结合自己的实践,介绍下
Apache Kylin以及它的实现效果。
背景知识
数据仓库
从业务的需求、设计、实现到上线,无外乎涉及到数据分析,各个阶段的决策基本上是从数据中来,到数据中去。
构建相关业务的数据仓库(Data Warehouse) 往往成为关键所在。
数据仓库是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。 为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
OLAP(Online analytical processing)
OLAP是计算机技术中快速解决多维分析问题的一种方法,其核心是一个多维数据集,由**度量(Measures)的数字事实组成,而这些数字事实按维度(Dimensions)**进行分类,防止在超立方体的交点处。
Apache Kylin
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
需求背景
简单了解Apache Kylin的一些背景知识后,想给大家分享,笔者遇到的数据分析需求。
业务埋点UV、PV的交互式查询平台
- 用户在实际使用产品的过程中,相应的关键操作都会有相应的埋点,这样有助于产品团队根据分析数据来进行决策。
- 埋点数据比较庞大,往往都会存在
HDFS上,提供Hive源表进行离线查询,而这往往在实际业务迭代过程中也有相应地痛点。
1、
HQL/Spark SQL对产品、运营团队不友好,学习成本高,或者说依赖相应RD编写语句。 2、查询结果虽然通过定时任务,由“每日报表”等方式自动化同步,其结果还是要进行人工整合分析趋势。 3、上面提到的“每日报表”包含很多冗余数据,难以管理。
- 由此,一个统一的交互式多维分析的查询平台便提上了议程。
为什么选择Apache Kylin?
那么,为什么选择Apache Kylin,是从以下几个方面考虑的
- 响应时间:显然,交互式平台对响应时间的要求是很高的,上述基于
Hive/Spark的查询方案,显然不满足需求。 - 离线还是实时:综合埋点数据分析场景,基于T+1的离线查询方式占主流,也就是说我针对昨天(或者前7天)的全量埋点数据做多维分析,针对某个度量进行趋势分析、流量分析等。
- 精确性:查询精确性方面,特别是
distinct场景,需要保证精确性,至少将误差率控制在可控范围内。 - 可视化查询:提供
RESTFUL API接口,以便可视化实现。
Kylin Cube实现过程
整体设计
- 整体流程如下图,从原始数据当中,我们可以提取事实数据、维度数据。
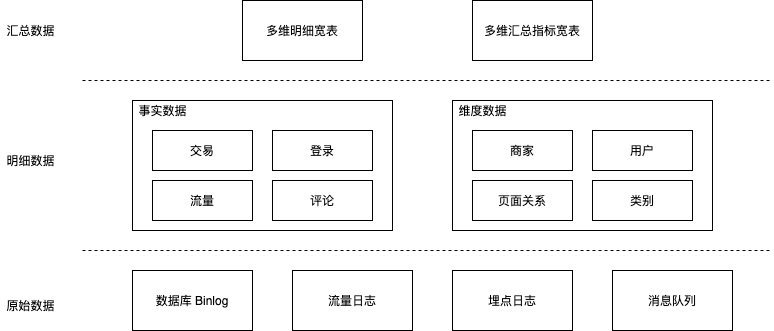
- 结合事实数据、维度数据,我们就可以构建相应的宽表,基于宽表构建
Kylin Cube。
宽表构建(从一个埋点宽表实例出发)
需求:日活用户点击App一级、二级tab的PV、UV
- 维度:是否是会员、是否是新用户、一级tab、二级tab
- 度量:
UV(count(distinct userID))、PV(count(userID))。
宽表设计
- 字段名仅表示相应字段含义,规范与否未考虑,可以理解为“伪代码”。
| userID | isVIP | isNewUser | 一级tab名 | 二级tab名 | 点击时间/展示时间 | date partition(按日期分区) |
|---|
- 要实现上述宽表,需要对一下表进行汇总处理。
1、会员表(维度表) 2、日活表 (事实表,汇总了登录行为等可以表示该用户成为日活的事实) 3、点击/展示埋点表(事实表) 4、新用户表(维度表)
Kylin Cube优化
- 基于宽表就可以构建相应的
Kylin Cube,而这里有几个优化小tips,供大家参考,当然详细,请参考官网。
1、可以把分区字段设成
Mandatory Dimensions,减少维度组合,降低维度膨胀率Expansion Rate。 2、Hierarchy Dimensions: 层级维度,例如 “国家” -> “省” -> “市” 是一个层级;不符合此层级关系的 cuboid 可以被跳过计算,例如 [“省”], [“市”]. 定义层级维度时,将父级别维度放在子维度的左边。 3、Joint Dimensions:设定类似1:1的维度关系,例如userID – email。
结语
- 本文结合交互式多维查询平台的例子,从选型
Apache Kylin到如何设计并实现事实宽表(Fact Table)进行了简要概述。 - 希望经验能帮助到大家。