前言
咱们书接上回,上回书说道,可以将事务基本操作用一种伪代码的形式表示,这可以有助于我们更好地理解操作过程。今天呢,主要想介绍undo/redo logging机制,可以理解为如何结合undo/redo来保证事务的ACD特性。
- 英文资料的切入点是从事务的
ACID特性出发,先分别分析undo logging、redo logging,从优缺点角度提出,是否有更灵活(flexible)的机制,最后提出了undo-redo logging。
- 个人觉得看完对理解
InnoDB上的undo log和redo log帮助很大。
日志记录的伪代码表述
- 上回书说道,事务操作可以用伪代码表述,其实日志记录方式也可以用伪代码表述,实际记录内容请结合具体平台进行进一步归纳。
- 日志记录在
log buffer(内存)和log file(磁盘)其实是不一样的,这点需要注意。
<START T>:表示事务T开始(日志记录在log buffer和log file其实是不一样的,这里需要注意)<COMMIT T>:表示事务T完成<ABORT T>:表示事务T被中断,即完成失败。<T, X, v, w>:T是事务ID,X表示数据元素,v代表旧值,w代表新值。
undo/redo机制的规则
- 每种机制都会有相应的规则,而这些规则对事务的实现尤为重要。
- 规则定义用的是上述介绍的伪代码形式。
undo负责回滚未commit的事务。redo负责重做已经commit的事务。
规则定义
<T, X, v, W>日志记录写入到日志文件,必须先于相应地数据元素X写入到数据库文件即OUTPUT(X)操作。- 事务管理器的具体做法是,在
OUTPUT(X)执行之前,将日志记录写入到磁盘(日志缓冲写入日志文件,当然也包含<T, X, v, W>),以此来保证遵守规则。
一个实例
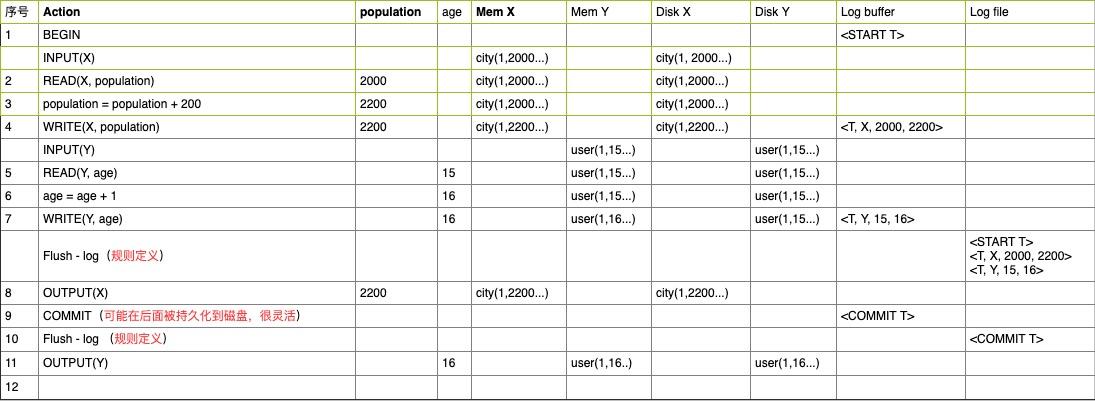
- 下面从一个事务实例,来介绍下
undo/redo机制过程。
- 例如,我们有个事务
T,需要改city表中数据元素X的population属性,也要改user表中数据元素Y的age属性,具体执行以及日志记录方式如下。(假设,X和Y的主键ID都是1,当然还有其他数据项)。

undo/redo恢复过程
- 我们结合上述图表,分别讨论在,
12,11,10,9及9之前(上述表格的序号,表示操作序号)出现系统异常时,是怎么根据undo/redo恢复的。
12
| T的状态 |
REDO/UNDO |
执行结果 |
备注 |
| 已提交 |
REDO |
population = 2200 age = 16 |
|
- 其实,这一步
REDO是多余的,数据库已经处于一致性状态了,但是规则就是规则,从System failure恢复且要保证一致性,还是需要一次REDO。
11
11出错,OUTPUT(Y)执行错误,说明数据元素Y的更改还没有写入到数据库文件中,数据库处于inconsistent state。COMMIT T写入文件,说明T已经提交。
| T的状态 |
REDO/UNDO |
执行结果 |
备注 |
| 已提交 |
REDO |
population = 2200 age = 16 |
|
10
1、<COMMIT T>已经写入到日志文件(log file) 2、<COMMIT T>还没来得及写入到日志文件,就出现错误。
<COMMIT T>已经写入到日志文件
| T的状态 |
REDO/UNDO |
执行结果 |
备注 |
| 已提交 |
REDO |
population = 2200 age = 16 |
|
<COMMIT T>没写入
| T的状态 |
REDO/UNDO |
执行结果 |
备注 |
| 已提交 |
UNDO |
population = 2000 age = 15 |
|
9及9之前操作出了问题
| T的状态 |
REDO/UNDO |
执行结果 |
备注 |
| 已提交 |
UNDO |
population = 2000 age = 15 |
|
undo/redo恢复过程小结
- 存在一个问题,只要
<COMMIT T>日志记录没有写入到日志文件(log file),在恢复时,就要被UNDO。
- 只能采取某种机制,将
<COMMIT T>尽快写入到日志文件。
小结
- 上述,根据伪代码表示,对
undo/redo规则及恢复过程做了梳理。
- 很显然,随着日志量增大,需要扫描的日志记录就会增大,就需要检查点(
checkpoint)机制来实现,日志文件存储优化、以及日志记录扫描优化。
- 可以参考,
undo/redo机制结合着学习InnoDB存储引擎中的redo log和undo log。
参考
文章永久链接:https://tech.souyunku.com/40457