前言
曾经有位面试官这么跟笔者说,“Undo/Redo log很重要,需要理解”,老实说,我当时觉得工作还没用到。但是,确实一直在用事务实现业务,但是不知道事务实现的机制,说不过去。 作为一名渣渣,查了很多资料,试图理解Undo/Redo,从MySQL技术内幕到MySQL运维内参,老实说,都深入到了log file的Page结构层面,源码看的笔者很晕。最后,google到了英文资料,貌似是课程内容,具体网址参见参考文章一。
- 课程的切入点是从事务的
ACID特性出发,先分别分析undo logging、redo logging,从优缺点角度提出,是否有更灵活(flexible)的机制,最后介绍了undo-redo logging。 - 个人觉得看完对理解
InnoDB上的undo log和redo log帮助很大。 - 笔者也会分几篇文章,努力归纳这部分内容,欢迎各种纠错!
背景知识
首先,要对几个主要概念进行回顾,想起了数据库原理课程。
- 数据元素:数据的基本单位,由若干个数据项组成
- 事务:访问并可能操作各种数据项的一个数据库操作序列,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。
- 数据库一致性(
Database Consistency):指事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。 - 影响一致性的因素主要有
2种:
1、系统错误(
System failure) 2、事务同时执行(Concurrent execution)
基本操作理解
- 众所周知的
Unix操作系统架构:用户态、内核态、硬件: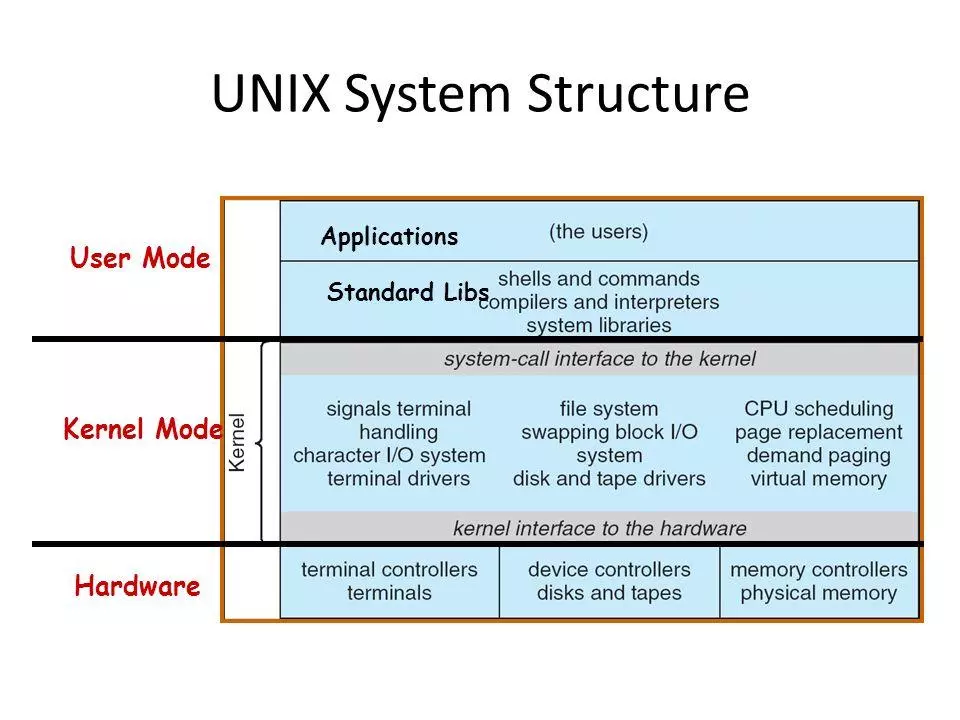
- 从上述架构,就可以更好地理解事务基本操作,以及执行过程了,基本操作如下图(图是笔者一笔一划画的)所示,基本操作采用伪代码的形式,仅供参考。
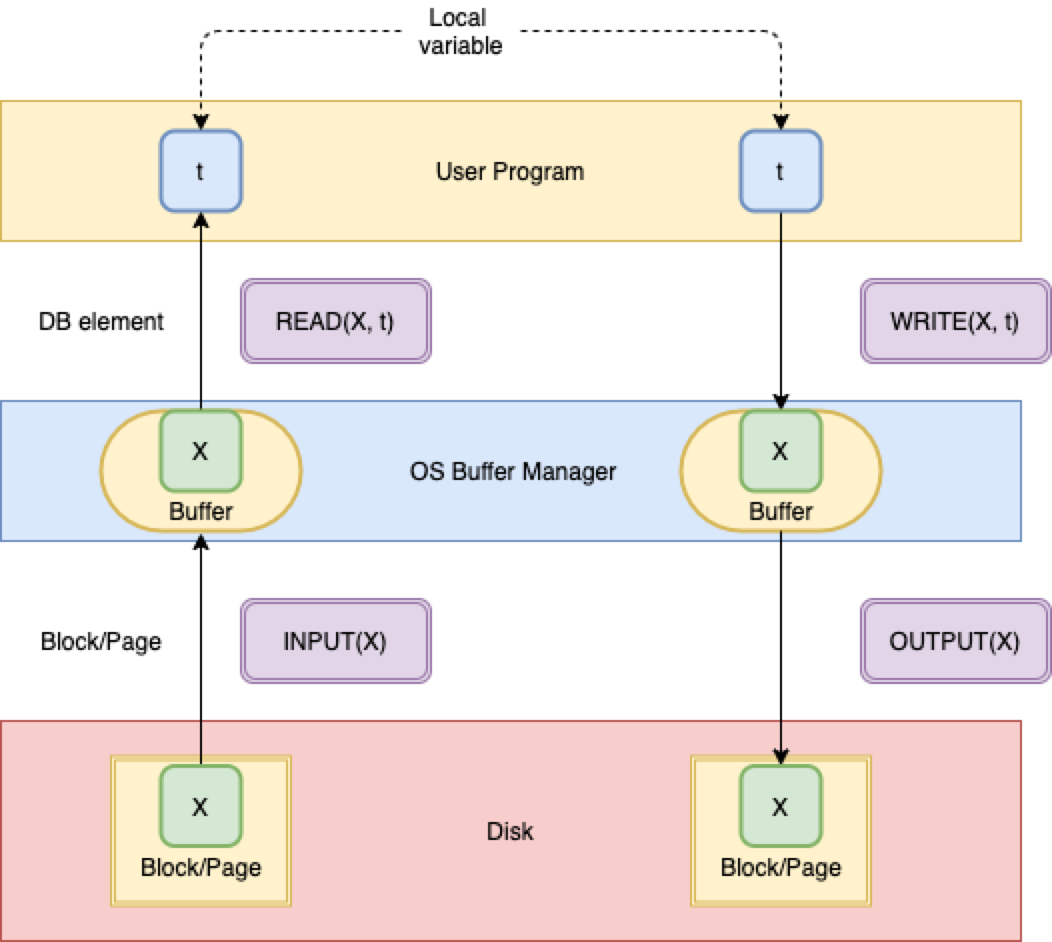
INPUT(X):按照块(或者页)的方式从数据库文件读取到Buffer Manager(或者Buffer Pool)中的buffer,然后内存中用同样大小的内存空间来做映射,块或者页包含数据元素(X)。READ(X, t):这里分2种情况,分别如下:
1、数据元素
X已经在buffer中,可以将buffer中X的数据项赋值给本地变量t。 2、数据元素X不在buffer中,首先会执行INPUT(X),再将buffer中X的数据项赋值给本地变量t。
WRITE(X, t):也分2种情况,分别如下:
1、数据元素
X已经在buffer中,本地变量t赋值给buffer中X的数据项。 2、数据元素X不在buffer中,首先会执行INPUT(X),再将本地变量t赋值给buffer中X的数据项。
OUTPUT(X):将buffer中数据元素X持久化到数据库(磁盘)文件中。
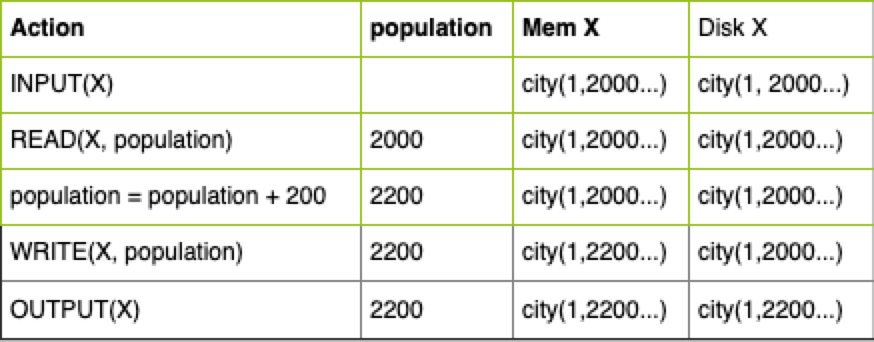
一个实例
- 例如,我有个
City属性表,然后改cityId为1的数据元素X的population数据项。
1、X.population旧值为2000 2、X.population = X.population + 200
- 那么,操作如下图所示,其中
Disk X为包含数据元素X的数据库文件,MEM X是内存中Disk X的映射,population为本地变量。
结语
上午因为有别的事儿,没来得及写结语,为什么要理解基本操作的执行过程呢?
- 1、因为
undo/redo logging机制的某些规则,就是基于这些操作制订的。 - 2、伪代码有利于过程理解,笔者有一次看书就晕了,一会儿“写到log buffer”,一会儿“写到log file”,很难对各个流程有个形象化理解。后续大家可以这么理解“写到log buffer”就是“write(X, t)”之类的。
- 3、后续,笔者会继续更新
undo/redo相关规则和流程。
希望对大家有所帮助