我们知道在开发中,事务是十分重要的。
通过事务,我们可以维护数据库的完整性。保证批量的SQL语句要么全部执行要么都不执行,从而保证了数据的正确性。
在Spring中事务管理有两种方式:
- 编程式事务
- 声明式事务
首先先了解什么是编程式事务?
顾名思义,编程式事务就是由程序员通过代码来完成事务的管理,比如事务的提交和回滚
接下来看看什么是声明式事务:
声明式事务就是Spring已经为我们编写好了事务管理的代码,我们只需要声明哪些方法需要进行事务管理以及如何进行事务管理就行。Spring官方推荐我们使用声明式事务。
声明式事务管理(Declarative transaction management)
Spring的声明式事务管理是基于AOP实现的。
前面,我们说到声明式事务就是Spring已经写好了事务管理的代码,即事务的提交和回滚。
那么代码是在哪里执行的?
我们知道Spring AOP存在一个概念:通知(Advice),我们可以定义一个切点,从而让通知在切点前后执行。显然,Spring进行事务管理的代码就是在Advice里面执行的。
基本使用
我们看看基于XML配置的AOP(AspectJ的方式)是怎么编写的:
假设,我们有一个业务类UserServiceImpl.java,所在包为com.xgc.service
public class UserServiceImpl extends UserService {
@Override
public void hello() {
System.out.println("hello");
}
}
现在我们想要在执行hello前输入前置Advice
那么我们先来编写Advice,所在包为com.xgc.advice
public class BeforeAdvice {
public void before() {
System.out.println("前置Advice");
}
}
现在我们已经编写好了Advice,那么如何让BeforeAdvice的before方法在UserServiceImpl的hello前运行呢?
我们需要在Spring的配置文件下配置:
<bean id="beforeAdvice" class="com.xgc.advice.BeforeAdvice"/>
<aop:config>
<aop:aspect ref="beforeAdvice">
<aop:pointcut expression="execution(* com.xgc.service.UserServiceImpl.hello())" id="mypoint"/>
<aop:before method="before" pointcut-ref="mypoint" />
</aop:aspect>
</aop:config>
<bean id="userServiceImpl" class="com.xgc.service.UserServiceImpl"></bean>
这样我们就配置好了,从而实现了执行hello方法之前先执行before方法。
当我们在业务类中方法中存在对数据库操作的操作,那么我们就需要进行事务管理,从而保证数据的一致性。那么我们如何让Spring为我们编写好的事务管理代码在我们的方法前后执行呢?
看到这里,就明白了。就是通过AOP!
Spring编写好的事务管理代码就相当于上面的Advice。业务类(切点)也有了。那么还需要什么呢?
就是配置它们。
那么,我们就来配置一下:
<!-- 这个就是我们希望进行事务管理的业务类对象 -->
<bean id="userServiceImpl" class="com.xgc.service.UserServiceImpl" />
<!-- Spring为我们编写好的事务管理代码,事务管理对象 -->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!-- 配置数据源,但数据源对象就不写了 -->
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- the transactional advice,配置Advice对象 -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
<!-- 需要有事务控制的方法 -->
<tx:method name="hello" />
</tx:attributes>
</tx:advice>
<!-- 这里就进行切点和advice的配置 -->
<aop:config>
<aop:pointcut id="mypoint" expression="execution(* com.xgc.service.UserServiceImpl.hello())"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="mypoint"/>
</aop:config>
我们可以看到上面的配置和AOP配置唯一不同的地方就是,它将Advice对象交给DataSourceTransactionManager对象来进行管理。
到这里,声明式事务管理的基本使用就讲完了。
完整代码
摘自官方文档SpringFrameWork-AccessData
业务接口类:
// the service interface that we want to make transactional
package x.y.service;
public interface FooService {
Foo getFoo(String fooName);
Foo getFoo(String fooName, String barName);
void insertFoo(Foo foo);
void updateFoo(Foo foo);
}
下面的例子展示了前面接口的一个实现:
package x.y.service;
public class DefaultFooService implements FooService {
@Override
public Foo getFoo(String fooName) {
// ...
}
@Override
public Foo getFoo(String fooName, String barName) {
// ...
}
@Override
public void insertFoo(Foo foo) {
// ...
}
@Override
public void updateFoo(Foo foo) {
// ...
}
}
xml配置
<!-- from the file 'context.xml' -->
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- this is the service object that we want to make transactional -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- the transactional advice (what 'happens'; see the <aop:advisor/> bean below) -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<!-- the transactional semantics... -->
<tx:attributes>
<!-- all methods starting with 'get' are read-only -->
<tx:method name="get*" read-only="true"/>
<!-- other methods use the default transaction settings (see below) -->
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<!-- ensure that the above transactional advice runs for any execution
of an operation defined by the FooService interface -->
<aop:config>
<aop:pointcut id="fooServiceOperation" expression="execution(* x.y.service.FooService.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="fooServiceOperation"/>
</aop:config>
<!-- don't forget the DataSource -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@rj-t42:1521:elvis"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
</bean>
<!-- similarly, don't forget the TransactionManager -->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- other <bean/> definitions here -->
</beans>
细节解释
<tx:method name="get*" read-only="true"/>
上面的read-only="true",告诉数据库此事务是只读事务。数据库对进行相应的优化,从而性能会有一定的提升。因此只要是查询的方法建议都使用只读事务。这其实是数据库层面的事,跟Spring无关。
默认值是false。
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
<tx:method name="get*" read-only="true"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
在这里我们看到配置两个<tx:method>标签。
第一个标签表示以get开头的所有方法。
第二个标签表示所有方法。
那么这两个放在一起的话,实际该执行哪一个advice呢?
答案是优先执行第一个,越靠前的越先执行。
事务传播(Transaction Propagation)
我们可以在<tx:method>标签的propagation属性来设置事务传播的方式。
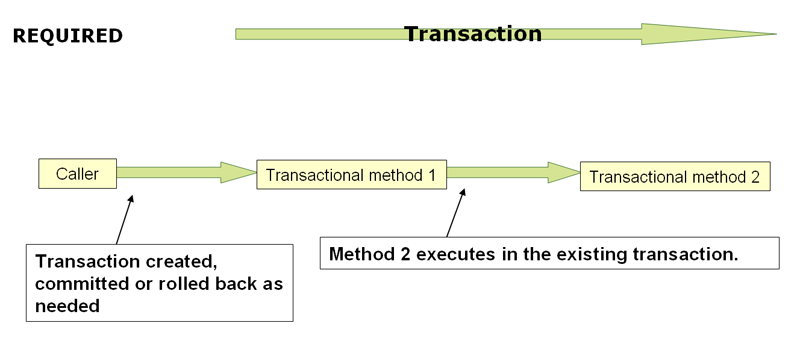
REQUIRED
REQUIRED是默认值。
当一个拥有事务管理的方法A调用另一个事务管理的方法B时:(当前两个方法的传播方式都是REQUIRED)
第一个方法A发现当前没有事务于是就创建事务,然后调用第二个方法B。
此时第二个方法B发现当前已经拥有事务了,就在当前事务中执行。
SUPPORTS
当一个方法的事务传播方式为SUPPORTS。
它被调用,如果当前没有事务,那么就在无事务的状态下执行。如果有事务就在当前事务下运行。
MANDATORY
必须在事务内部执行。
如果有事务,就在事务下执行。如果没有事务,就报错。
REQUIRES_NEW
必须在事务内部执行。
如果当前没有事务,就创建事务。如果当前存在事务,就把当前事务挂起,然后自己创建事务,在自己的事务中执行。
这里,我们可以知道事务传播的作用了。
- 假设一个方法(事务传播方式为默认)调用另一个方法(事务传播方式为
REQUIRES_NEW):这里我们就会存在两个事务对象。当第二个方法出现错误的时候,就会进行回滚。此时并不会影响到第一个事务。
- 再想想默认的
REQUIRED,它会让多个相互调用的方法都共享一个事务。那么当其中一个方法出现错误的时候,就会全部进行回滚。
事务传播的配置能让我们更好的管理事务。
NOT_SUPPORTED
必须在无事务情况下执行。
如果没有事务,就正常执行。如果当前有事务,就把当前事务挂起。
NEVER
必须在无事务情况下执行。
如果当前没有事务,就正常执行。如果当前有事务,就报错。
NESTED
必须在事务情况下执行。
如果当前没有事务,就创建事务。如果当前存在事务,就创建一个嵌套事务。
此时嵌套事务和当前事务是存在联系的。
当第二个方法出现异常的时候,嵌套事务就会回滚到第二个方法的初始状态。
这听起来好像和REQUIRES_NEW一样啊,那么它们有什么区别呢?
它们的区别体现在第二个方法正常执行的时候:
- REQUIRES_NEW:当第二个方法正常执行的时候,它的事务就会比第一个方法的事务先提交。
- NESTED:当第二个方法正常执行的时候,它进行的操作不会立即提交。而是在第一个事务提交的时候同时提交。当第一个方法出现错误的时候,二个事务都会同时回滚。
事务隔离级别
设置数据库的事务隔离级别。
可以通过<tx:method>标签的isolation属性来设置。
其实,事务隔离级别是数据库的概念。
在了解事务隔离级别之前,我们先了解一下事务的概念、事务的四大特性、并发时事务会出现的问题。
什么是事务:批量SQL语句要么同时执行,要么全部都不执行,要来保证数据的完整性。
事务的四大特性:
- 原子性(Atomicity)
一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
-
一致性
在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
-
隔离性
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
-
持久性
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
事务并发会带来的问题:
- 脏读
脏读发生在一个事务A读取了被另一个事务B修改,但是还未提交的数据。假如B回退,则事务A读取的是无效的数据。
-
不可重复读
一个事务在整个事务的过程中对同一条数据进行多次读取,而每次读取的结果都不一样。这发生在一个事务A先读取了数据,另一个事务B修改了这条数据,导致事务A读取的数据和第一次读取不一样。
-
幻读
一个事务在整个事务的过程中进行多次查询操作,但是查询结果的条数不一致。这发生在一个事务A进行了查询操作之后,另一个事务B增加或删除了数据,导致事务A第二次查询的时候出现了数据条数不一致的情况。
为了解决上面事务并发出现的问题,于是就引进了事务隔离级别。
DEFAULT
在Spring中,是默认值。由底层数据库自动判断使用什么隔离级别
READ_UNCOMMITED
可以读取到未提交的数据,那么可能会出现脏读、不可重复读、幻读。效率最高。
READ_COMMITED
只能读取到其他事务提交的数据。可以防止脏读,可能出现不可重复读和幻读。
假设一个数据被事务A读取了,而另一个事务B修改并提交了,事务A再读取。还是会出现不可重复读和幻读的问题。
REPEATABLE_READ
读取的数据会被添加锁,防止其他事务修改读取了的数据。可以防止脏读和不可重复读,但还是会出现幻读。
SERIALIZABLE
排队操作,对整个表添加锁。一个事务在操作数据时,另一个事务等待事务操作完成时,才能操作这个表。
这个事务隔离级别是最安全的,但也是效率最低的。
事务回滚
我们可以在<tx:method>标签的rollback-for属性来设置出现什么异常的时候进行回滚。
Spring默认使用的是java.lang.Exception
但在实际使用中,很多时候,在手动抛出异常的时候,不会回滚。
所以建议加上
<tx:method rollback-for="java.lang.Exception"></tx:method>
还有一个属性no-rollback-for指定当出现什么异常时不回滚