FAQ
1、相关性评分什么时候会变得没有意义?单纯使用 filter 并进行精准匹配的时候吗?
疑惑来源:Elasticsearch: 权威指南 » 基础入门 » 排序与相关性 » 排序。
理解:据 解析ElasticSearch/Lucene打分策略 这篇文章开头所述:”按照指定的 sort,此时分数是 0,即没有相关性的概念”,猜测当使用 sort 进行排序的时候,ES 将不会对文档进行打分。
2、空间向量模型中的值表示的是每一个词对该文档的权重,还是每一个词对该文档的分数?
疑惑来源:向量空间模型、解析ElasticSearch/Lucene打分策略。
理解:理解为每一个词对该文档的分数好像更合适一点,但在两篇文章的图表中,都表示的是每一个词对该文档的权重。
默认情况下,ES 搜索的返回结果是按照「相关性」进行排序的——最相关的文档排在最前面。因此提出一个问题:ES 为什么提供相关性打分机制?
应用场景
试想一个业务场景:我们可以给用户提供羽毛球、游泳等运动项目的场馆预定。用户在进行场馆搜索时,底层依靠 ES 搜索引擎。用户在输入搜索关键词之后,在 ES 索引中进行关键词匹配,然后将符合关键词的运动场馆展示给用户。业务流程看起来比较简单,但给用户展示最终数据时,需要综合考虑多种因素,如:价格、库存、评分、销量、经纬度等。
如果单纯按场馆距离、价格排序时,排序过于绝对。比如有时会想让库存数量多的场馆排名靠前,同时让评分过低的排名靠后,有时在有多家价格相同的场馆同时显示的情况下,想让距离用户近的场馆显示在前面,这时就可以通过 ES 强大的评分功能来实现。
相关性算法
在 ES 中相关性评分由一个浮点数表示,并在搜索结果中通过 _score 参数返回,默认是按照 _score 降序排列。
ES 5.X 版本将相关性算法由之前的 TF/IDF 算法改为了更先进的 BM25 算法。
TF/IDF 评分算法
ES 版本 < 5 的评分算法,即「词频/逆向文档频率」,TF/IDF 实际上是两个算法 TF 和 IDF 的乘积 ( )。
)。
**注:**以下公式中提到的文档实际上是指文档里的某个字段。
词频 (Term frequency)
词频的所在对象是一个具体的文档,是指一个文档中出现某个单词 (Term) 的频率 (Frequency)。这里用的是频率而不是次数,是为了防止文档内容过长从而导致某些单词出现过多。计算公式如下:

上面式子中  是该词在文档中的出现次数,而分母
是该词在文档中的出现次数,而分母  则是在文档中所有字词的出现次数之和。
则是在文档中所有字词的出现次数之和。
逆向文档频率 (Inverse document frequency)
搜索词在索引(单个分片)所有文档里出现的频率,频率越高,相关度越低。用人话描述就是”物以稀为贵”,计算公式如下:

- |D|:表示索引中的文档总数
- |
 |:包含词语 的文档数目(即 的文档数目),如果词语不在索引中,就导致分母为零,因此一般情况下使用分母加了一个 1
|:包含词语 的文档数目(即 的文档数目),如果词语不在索引中,就导致分母为零,因此一般情况下使用分母加了一个 1
 |:包含词语
|:包含词语  的文档数目(即
的文档数目(即  的文档数目),如果词语不在索引中,就导致分母为零,因此一般情况下使用分母加了一个 1
的文档数目),如果词语不在索引中,就导致分母为零,因此一般情况下使用分母加了一个 1某一文档内的高词语频率,以及该词语在整个索引中的低文档频率,可以产生出高权重的 TF/IDF。因此,TF/IDF 倾向于过滤掉常见的词语,保留重要的词语。
TF/IDF 算法举例
用上面的公式,计算一个例子。
假如一篇文档的总词语数是 100 个,而词语“学校”出现了 5 次,那么“学校”一词在该文档中的词频 (tf) 就是: 。
。
“学校”一词在 1000 份文档出现过,而文档总数是 1000000 份的话,其逆向文档频率就是: 。
。
最后的 TF/IDF 的分数为: 。
。
OKapi BM25 算法原理
ES 版本 >= 5 的评分算法;BM25 的 BM 是缩写自 Best Match,25 貌似是经过 25 次迭代调整之后得出的算法。
TF/IDF 虽然是一个可用的算法,但并不太完美。它给出了一个基于统计学的相关分数算法,而 BM25 算法则是在此之上做出改进之后的算法。(为什么要改进呢?TF/IDF 不完美的地方在哪里?)
1、 当两篇描述”人工智能”的文档 A 和 B,其中 A 出现”人工智能” 100 次,B 出现”人工智能” 200 次。两篇文章的单词数量都是 10000,那么按照 TF/IDF 算法,A 的 tf 得分是:0.01,B 的 tf 得分是 0.02。得分上 B 比 A 多了一倍,但是两篇文章都是在说人工智能,tf 分数不应该相差这么多。可见单纯统计的 tf 算法在文本内容多的时候是不可靠的。
2、 多篇文档内容的长度长短不同,对 tf 算法的结果影响也很大,所以需要将文本的长度也考虑到算法当中去。
基于上面两点,BM25 算法做出了改进,对于给定查询语句 Q,其中包含关键词  ,那么文档 D 的 BM25 评分计算公式如下:
,那么文档 D 的 BM25 评分计算公式如下:

这个公式看起来很唬人,尤其是那个求和符号,不过分解开来还是比较好理解的。
总体而言,主要分三部分,TF-IDF-Document Length。
IDF 的计算公式调整为如下所示,其中 N 为文档总数, 为包含搜索词
为包含搜索词  的文档数。
的文档数。

 为搜索词
为搜索词  在文档 D 中的 TF。
在文档 D 中的 TF。
- |D|:文档的长度
- avgdl:平均文档长度
- :词语频率饱和度(term frequency saturation),它用于调节饱和度变化的速率。它的值一般介于 1.2 到 2.0 之间,数值越低则饱和的过程越快速,在 ES 应用中为 1.2
- :字段长度归约,将文档的长度归约化到全部文档的平均长度,它的值在 0 和 1 之间,1 意味着全部归约化,0 则不进行归约化。在 ES 的应用中为 0.75
 :词语频率饱和度(term frequency saturation),它用于调节饱和度变化的速率。它的值一般介于 1.2 到 2.0 之间,数值越低则饱和的过程越快速,在 ES 应用中为 1.2
:词语频率饱和度(term frequency saturation),它用于调节饱和度变化的速率。它的值一般介于 1.2 到 2.0 之间,数值越低则饱和的过程越快速,在 ES 应用中为 1.2 :字段长度归约,将文档的长度归约化到全部文档的平均长度,它的值在 0 和 1 之间,1 意味着全部归约化,0 则不进行归约化。在 ES 的应用中为 0.75
:字段长度归约,将文档的长度归约化到全部文档的平均长度,它的值在 0 和 1 之间,1 意味着全部归约化,0 则不进行归约化。在 ES 的应用中为 0.75不看 IDF 和 Document Length 部分的话,则公式变为 TF * (k1 + 1) / (TF + k1),相比传统的 TF/IDF 而言,BM25 抑制了 TF 对整体评分的影响程度,虽然同样都是增函数,但是 BM25 中,TF 越大,带来的影响无限趋近于 (k1 + 1),这里 k1 值通常取 [1.2, 2.0],而传统的 TF/IDF 则是没有临界点的无限增长。
至于文档长度 |D| 的影响,可以看到在命中搜索词的情况下,文档越短,相关性越高,具体影响程度又可以由公式中的 b 来调整,当设值为 0 的时候,忽略文档长度的影响。
最后再对所有搜索词的计算结果求和,就是 ES5 中一般查询的得分了。
文档打分的过程
先来看一下 ES 进行文档打分的总体过程:
1、 先根据 query 的语法判断是否对 keyword 进行分词;
2、 得出 keyword 中包含的 term;
3、 根据 term 去索引中找到多个 doc;
4、 根据 query 的语法,通过 boolean 模型得到最终的文档集;
5、 根据 TF/IDF (BM25) 算法模型计算每个 term 对文档、query 的分值,得出文档、query 在某一维的坐标;
6、 根据维度上的坐标画出文档、query 的空间向量;
7、 计算文档以及 query 空间向量的夹角余弦值,在计算的过程中加入 boost,得到最终的得分 score。
接下来对上述过程中涉及到的一些术语进行解释。
分词
一个 query 语句会根据 query 的类型进行分词、语法解析拆分,并且按照类似 and 这种逻辑操作符,得出 bool 语句,这样可以先过滤出包含指定 term 的 doc。例如:
"match": {
"title": "hello world"
}
“hello world” 会被拆分成 “hello” | “world” | “hello & world” 等 term,并根据 term 和逻辑运算符来进行 doc 的过滤。这一过程是不含任何打分动作的,只是过滤出对应的文档。主要可以减少后续计算所涉及的文档数并为后续打分提供依据。
boolean 模型
布尔模型只是在查询中使用 AND、OR 和 NOT(与、或和非) 这样的条件来查找匹配的文档,比如以下查询:
full AND text AND search AND (elasticsearch OR lucene)
会将所有包括词 full、text 和 search,以及 elasticsearch 或 lucene 的文档作为结果集。这个过程简单且快速,它将所有可能不匹配的文档排除在外。
具体解释请参考:布尔模型。
向量空间模型
一个 keyword 被分词后,可能会产生多个 term。综合 TF/IDF,length norm (字段长度归一值「field 长度越长,给的相关度评分越低;field 长度越短,给的相关度评分越高」) 以及设置的权重能够计算出每个 term 对某个文档的分数,然后 Lucene 再将这多个 term 对一个文档的多个分数进行综合计算,最终将总分数作为这个文档对这个关键词的得分。
对于多个 term 是如何决定一个文档分数的,以及一个 query 是如何等到某个文档得分的,Lucene 采用的是空间向量模型:
- 空间的维:一个维代表一个 term,某个 term 通过 TF/IDF 以及字段的长度会计算出一个 doc 的分数,那么这个分数就是这个文档在这个维的坐标。所以计算出多个 term 的分值 (term1_score; term2_score; term3_score) 就相当于确定了一个文档在多个维的坐标,也就可以画出他的向量
- 文档向量 (doc vector):假设这个文档包含 3 个 term。也就是说这个文档在空间中有三个维度含有此文档的坐标刻度。可以得出文档在空间中的一个向量
- 索引向量 (query vector):这个 query 语句同样被当成一个文档来看待,同样可以在空间中找到某个 term 维上的坐标,根据坐标可以构成一个空间向量
query 对 doc 的得分计算:通过计算 doc vector 和 query vector 的夹角余弦值作为最终的分数。夹角越大,分数越小; 夹角越小,分数越大。
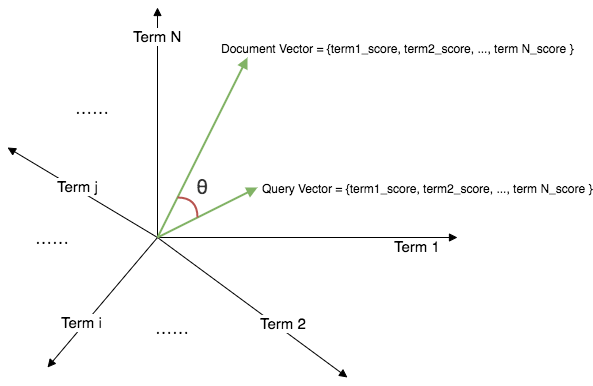
注意:博主对文档向量以及索引向量中的值所代表的含义尚有疑惑,这里暂时以词对文档的分数进行定义,正确性还有待研究。
总结
1、 sort 无法满足复杂场景下对结果集的排序;
2、 TF/IDF 算法的结果为 TF 与 IDF 的乘积;
3、 理解文档打分的过程,理解向量空间模型。
参考阅读
1、 Elasticsearch系列五:搜索相关性排序算法详解
2、 从零搭建 ES 搜索服务(六)相关性排序优化
3、 机器学习:生动理解TF-IDF算法
4、 解析ElasticSearch/Lucene打分策略
5、 Elasticsearch: 权威指南 » 深入搜索 » 控制相关度 » 相关度评分背后的理论