安装部署
核心概念
Elasticsearch是构建在Apache Lucene之上的开源分布式搜索引擎,Lucene是开源的搜索引擎包,允许你通过自己的Java应用程序实现搜索功能。Elasticsearch允许利用Lucene,并对其进行扩展,是存储、索引、搜索都变得更快、更容易,而最重要的是,正如名字中的elastic,一切都是灵活,有弹性的。
首先看数据在Elasticsearch中是如何存储的,从两个角度来观察
- 逻辑设计
用户索引和搜索的基本单位是文档,可以将其设计为关系数据库里的一行。文档以类型分组,类型包含若干文档,类似表格包含若干行。最终,一个或者多个类型存在于同一索引中。索引是更大的容器,类似于关系型数据库中的数据库。 其对应关系总结如下,可以形象的对比: 文档<-> 行, 类型<->表,索引<->数据库。
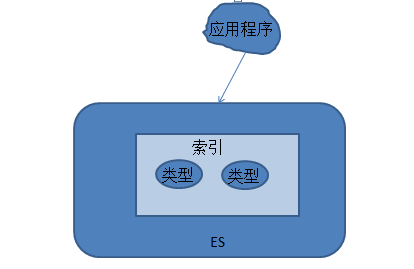
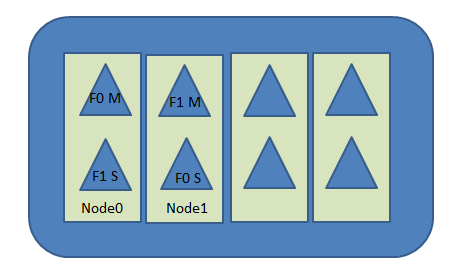
- 物理设计 Elasticsearch将每个索引划分为分片,每份分片可以在集群中的不同服务器间迁移。
理解几个概念
- 文档:索引和搜索的最小单位是文档。一批文档通常是数据的JSON表示。常与关系型数据库中的行进行类比。其有下面几个特征:1.自我包含的,同时包含指定和他们的取值。2.可以是层次型的,文档中可以包含新的文档,文档中的字段也是可以包含内嵌的其他字段和取值,例如:地址信息字段可以包含,详细信息和省市区等信息。3.拥有灵活的结构,不依赖于预先定义的模式,也就是说并非所有的文档都需要拥有相同的字段。
- 类型:文档的逻辑容器。常与关系型数据库中的表进行类比。在不同的类型中,最好放入不同的结构的文档。每个类型中字段的定义成为映射。对于线上的环境最安全的方式是在索引数据之前,最好就定义好所需的映射。映射类型只是将文档进行逻辑划分,从物理角度看,同一个索引中的文档都是写入磁盘,并不考虑他们属于的映射类型。
- 索引:映射类型的容器,常与关系型数据库中的数据库进行类比。每一个索引存储在磁盘上的同组文件中,索引存储了所有映射类型的字段。还有一些设置。就像可以跨多个类型进行搜索一样,也可以跨多个索引进行搜索。一个具体到索引的设置是分片的数量。
- 节点:一个节点是一个ES的实例,在服务器上启动ES之后,就拥有了一个节点,如果在另外一台服务器上新启动一个ES,就拥有了另一个节点。甚至可以在一同服务器上启动多个ES进程,拥有多个节点在同一台服务器上。多个节点可以加入到同一个集群。
- 分片:一份分片是一个目录中文件,Lucene用这些文件存储索引数据,分片也是ES将数据从一个节点迁移到另一个节点的最小单位。一份分片是Lucene的索引:一个包含倒排索引的文件目录。倒排索引的结构使得ES在不扫描所有文档的情况下,就能告诉你哪些文档包含特定的词条。
索引文档
集群启动并运行后,您就可以为某些数据建立索引了。Elasticsearch有多种摄取选项,但最终它们都做同样的事情:将JSON文档放入Elasticsearch索引中。您可以使用简单的PUT请求直接执行此操作,该请求指定要添加文档的索引,唯一的文档ID,以及请求正文中的一个或多个"field":value"对:
// |索引的名称|类型的名称|文档的ID
curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"name": "John Doe"
}
'
此请求将自动创建customer索引(如果它还不存在),添加ID为1的新文档,并存储和索引name字段。
由于这是一个新文档,因此响应显示该操作的结果是创建了该文档的版本1:
{
"_index" : "customer",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 26,
"_primary_term" : 4
}
新文档可以立即从集群中的任何节点获得。您可以使用指定其文档ID的GET请求来检索它:
curl -X GET "localhost:9200/customer/_doc/1?pretty"
响应表明找到了具有指定ID的文档,并显示了被索引的原始源字段。
{
"_index" : "customer",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 26,
"_primary_term" : 4,
"found" : true,
"_source" : {
"name": "John Doe"
}
}
检索和定义映射
通常我们并不用担心映射,因为ES会帮我们自动设别字段,并相应的调整映射。对于上面的例子我们可以使用如下的语句进行验证:
➜ Downloads curl 'localhost:9200/customer/_mapping?pretty'
{
"customer" : {
"mappings" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
尤其注意的一点是,定义一个映射是发送一个PUT http请求,而不是Get请求。也可以在一个某类型中插入任何文档之前定义一个新的映射。如果现在在上面的基础上再设置一个映射。ES会将二者进行合并,
➜ Downloads curl -X PUT "localhost:9200/customer/_doc/1?pretty" -H 'Content-Type: application/json' -d'
{
"Addr": "Shanghai,China"
}
'
{
"_index" : "customer",
"_type" : "_doc",
"_id" : "1",
"_version" : 2,
"result" : "updated",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
再次查询_mapping
➜ Downloads curl 'localhost:9200/customer/_mapping?pretty'
{
"customer" : {
"mappings" : {
"properties" : {
"Addr" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
但是要注意,合并必须是合法的,要是更改了现有的字段的数据类型,导致之前的数据非法,就无法进行合并操作了。
核心字段和派生的复杂类型
- 字符串类型 字符串类型是最直接的。解析文本,转变文本,将其分解为基本元素使得搜索更为相关,这个过程叫做分析。
例如 “I love elastic”文档,当我们在搜索elastic的时候,ES会分析他们,默认的分析器会把他们都小写化,然后将文档进行分词,之后将查询条件和文档中的词条进行匹配,如果匹配了,返回匹配的文档。
映射会对这种分析过程起作用,可以在映射中指定许多分析的选项,例如可以配置生产原始词条的同义词,进行同义词查询。
- 数值类型:可以是浮点数,也可以是非浮点数。如果不需要小数,可以选择byte, short,int或者long。如果确实需要小数,可以选择float和double.
- date类型用于存储日期和时间。通常提供一个表示日期的字符串,例如2019-10-23T11:00:11.然后Es解析这个字符串,然后将其作为long的数值存入
Lucene的索引。该long数值是从unix纪元(1970)到所提供的时间之间已经过去的毫秒数。在搜索时,在后台es会把提供 的date字符串转化为数组后进行比较处理,这是因为数组在存储和处理的时候,代价更小。速度更快 - 布尔类型用于存储文档中的真假值。就像日期类型一样,es会将真假值转化为T/F.
- 数组和多字段:
- 数组:如果要索引拥有多个值的字段,将这些值放入方括号中,例如
curl -XPUT 'localhost:9200/blog/posts/1' -d '{"tags":["first","initial"]}',Es在映射中将该字段作为字符串型,和单值同样处理,也就是其类型type字段同样是string. - 多字段:无需重建索引就能将单字段升级为多字段,但是反之,无法抹除多字段中的子字段。
- 数组:如果要索引拥有多个值的字段,将这些值放入方括号中,例如
➜ ~ curl 'localhost:9200/get-together/_mapping?pretty'
{
"get-together" : {
"mappings" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}
上面的fields中的字段就是子字段。其类型是keyword类型的字符串。
预定义字段
我们将重要的预定义字段分为几类:
- 控制如何存储和搜索文档:
_source在索引文档的时候,存储原始的JSON文档,_all将所有的字段一起索引。 - 唯一识别文档
_uid,_id,_type,_index - 为文档增加新的属性:可以使用
_size来索引原始JSON内容的大小。_timestamp来索引文档索引的时间,并且使用_ttl来告知Es在一定时间后删除文档。 - 控制文档路由到哪个分片:相关字段是
_routing和_parent
➜ ~ curl 'localhost:9200/get-together/new-events/1?pretty'
{
"_index" : "get-together",
"_type" : "new-events",
"_id" : "1",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "Late Night with Elasticsearch"
}
}
仅仅返回某些字段
➜ ~ curl 'localhost:9200/get-together/new-events/1?pretty&stored_fields=name'
{
"_index" : "get-together",
"_type" : "new-events",
"_id" : "1",
"_version" : 3,
"_seq_no" : 2,
"_primary_term" : 1,
"found" : true
}
为了识别同一个索引中的某一篇文档。使用_uid,该字段是有_id和_type字段组成。
批量索引文件
如果您要索引的文档很多,您可以使用bulk API分批提交它们。使用bulk来批量处理文档操作比单独提交请求要快得多,因为它最小化了网络往返。
最佳批处理大小取决于许多因素:文档大小和复杂性,索引编制和搜索负载以及群集可用的资源。一个好的起点是批处理1,000至5,000个文档,总有效负载在5MB至15MB之间。 从那里,您可以尝试找到最佳位置。
要将一些数据导入Elasticsearch,您可以开始搜索和分析:
- 下载accounts.json示例数据集。 此随机生成的数据集中的文档代表具有以下信息的用户帐户:
{
"account_number": 0,
"balance": 16623,
"firstname": "Bradshaw",
"lastname": "Mckenzie",
"age": 29,
"gender": "F",
"address": "244 Columbus Place",
"employer": "Euron",
"email": "bradshawmckenzie@euron.com",
"city": "Hobucken",
"state": "CO"
}
- 使用以下_bulk请求将帐户数据索引到银行索引中:
curl -H "Content-Type: application/json" -XPOST "localhost:9200/bank/_bulk?pretty&refresh" --data-binary "@accounts.json"
curl "localhost:9200/_cat/indices?v"
返回结果:
➜ src curl "localhost:9200/_cat/indices?v"
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open bank SK-k2aySS_q0gxvfBvJd-A 1 1 1000 0 428.2kb 428.2kb
yellow open customer sNSBkJq7TW29tVhK3d9VhA 1 1 1 0 3.4kb 3.4kb
获取映射
映射是随着新文档而自动创建的,为了查看当前的映射,发送一个GET请求到该索引的_mapping端点,这将展示索引内的所有类型的映射,但是可以通过在_mapping端点后制定类型的名称来获取某个具体的映射。
更新现有的文档
步骤如下:
- 检索现有的文档
- 进行指定的修改
- 删除旧的文档
curl -XPOST 'localhost:9200/get-together/group/2/_update' -d '{"doc":{"organizer":"ZJW"}}'
使用upsert来创建尚未存在的文档 curl -XPOST 'localhost:9200/get-together/group/2/_update' -d '{"doc":{"organizer":"ZJW"}, "upsert":{"name":"Elasticsearch Denver","organizer":"WJ"}}'
删除文档
- 删除单个文档或者一组文档:Es只是将他们标记为删除,稍后通过异步的方式彻底从索引中移除。
- 删除整个索引:性能比较好
- 关闭索引:不允许读取或者写入操作,但是可以恢复。
curl -XDELETE 'localhost:9200/online-shop/shirts/1'
curl -XDELETE 'localhost:9200/online-shop/shirts'
curl -XDELETE 'localhost:9200/online-shop/_query?q=vans'
删除索引
通过提供逗号分割的多个索引,可以删除多个索引,如果将索引名改为_all,甚至可以删除全部的索引。
curl -XDELETE 'localhost:9200/get-together'
curl -XDELETE 'localhost:9200/_all'
关闭索引
curl -XPOST 'localhost:9200/get-together/_close'
curl -XPOST 'localhost:9200/get-together/_open'
开始搜索
将一些数据放到Elasticsearch索引后,您可以通过将请求发送到_search端点来进行搜索。
一个搜索的三个重要组成部分
- 在哪里搜索
- 回复的内容
- 搜索什么以及如何搜索
在哪里搜索
可以告诉ES在特定的类型和特定索引中进行查询,但是也可以在同一个索引的多个字段中搜索,在多个索引中搜索或是在所有索引中搜索。为了在多个类型中搜索,使用逗号分隔的列表,例如 curl "localhost:9200/bank/zhongguobank,zhaoshangbank/_search?q=elastic&pretty"
也可以只提供类型,即在某一个索引中的多个类型中搜索: curl "localhost:9200/bank/_search?q=sample&pretty"
在多个索引中搜索,也是使用逗号分隔
curl localhost:9200/bank,zhengquan/_search?q=elastic&pretty
回复的内容
- 你的请求耗时多久,以及是否超时
- 查询了多个分片
- 所有匹配的文档的统计数据
- 结果数组
要访问全套搜索功能,请使用Elasticsearch Query DSL在请求正文中指定搜索条件。 您可以在请求URI中指定要搜索的索引的名称。
例如,以下请求将检索银行索引中按帐号排序的所有文档:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
]
}
'
默认情况下,响应的hits部分包含匹配搜索条件的前10个文档:
{
"took" : 23, // 单位是毫秒
"timed_out" : false, // 请求是否超时
"_shards" : { // 搜索相关的分片信息
"total" : 1, // 总共几个分片
"successful" : 1, // 成功返回的分片数量
"skipped" : 0, // 跳过的分片数量
"failed" : 0 // 失败的分片数量,数据不可用
},
"hits" : { // 匹配文档的数组
"total" : { // 匹配文档的总数
"value" : 1000,
"relation" : "eq"
},
"max_score" : null, // 匹配文档的最高得分
"hits" : [
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "0",
"_score" : null,
"_source" : { // 默认在其中存储原始的JSON文档
"account_number" : 0,
"balance" : 16623,
"firstname" : "Bradshaw",
"lastname" : "Mckenzie",
"age" : 29,
"gender" : "F",
"address" : "244 Columbus Place",
"employer" : "Euron",
"email" : "bradshawmckenzie@euron.com",
"city" : "Hobucken",
"state" : "CO"
},
"sort" : [
0
]
},
{
"_index" : "bank",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "amberduke@pyrami.com",
"city" : "Brogan",
"state" : "IL"
},
"sort" : [
1
]
}....
]
}
}
该响应还提供有关搜索请求的以下信息:
took: Elasticsearch运行查询所需的时间(以毫秒为单位)timed_out:搜索请求是否超时_shards:搜索了多少个分片,以及成功,失败或跳过了多少个分片。max_score:找到最相关的文档的得分hits.total.value:找到多少个匹配的文档hits.sort:文档的排序位置(不按相关性得分排序时)hits._score:文档的相关性得分(使用match_all时不适用)
搜索什么以及如何搜索
每个搜索请求都是独立的:Elasticsearch在请求中不维护任何状态信息。要翻阅搜索结果,请在请求中指定from和size参数。例如,以下请求的获取hits从_id等于10到等于19的数据:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} },
"sort": [
{ "account_number": "asc" }
],
"from": 10,
"size": 10
}
'
现在您已经了解了如何提交基本的搜索请求,您可以开始构建比match_all更有趣的查询。
要在字段中搜索特定术语,可以使用match查询。例如,下面的请求搜索address字段,以查找其地址包含mill或lane的客户:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match": { "address": "mill lane" } }
}
'
要执行短语搜索而不是匹配单个词,请使用match_phrase而不是match.例如,下面的请求只匹配包含短语mill lane的地址:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": { "match_phrase": { "address": "mill lane" } }
}
'
要构造更复杂的查询,可以使用bool查询来组合多个查询条件。 您可以根据需要(必须匹配),期望(应该匹配)或不期望(必须不匹配)指定条件。
例如,下面的请求在银行索引中搜索属于40岁客户的帐户,但不包括居住在爱达荷州的任何人(ID):
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": [
{ "match": { "age": "40" } }
],
"must_not": [
{ "match": { "state": "ID" } }
]
}
}
}
'
布尔查询中的每个must,should和must_not元素都称为查询子句。文档满足每个must或should条款中的条件的程度会提高文档的相关性得分。得分越高,文档越符合您的搜索条件。默认情况下,Elasticsearch返回根据这些相关性得分排序的文档。
must not子句中的条件被视为筛选器。它影响文档是否包含在结果中,但不影响文档的评分方式。您还可以显式地指定任意筛选器来包含或排除基于结构化数据的文档。
例如,以下请求使用范围过滤器将结果限制为余额在20,000美元到30,000美元(含)之间的帐户。
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query": {
"bool": {
"must": { "match_all": {} },
"filter": {
"range": {
"balance": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
'
设置查询的字符串选项
如果只提供”query”:”elastic Hangzhou China”,默认查询_all字段。如果想在分组中查找,需要指定"default_field":"name" ,同样,ES默认会返回匹配了任一指定关键字的文档(OR),如果需要匹配所有的关键字,需要制定"default_operator":"AND" 修改后的查询看起来如下:
curl 'localhost:9200/bank/zhongguobank/_search?pretty' -d '{
"query":{
"query_string":{
"query":"elastic Hangzhou China",
"default_field":"name",
"default_operator":"AND"
}
}
}'
选择合适的查询类型
如果在name字段中只查询elastic一个词,term查询可能更快捷,更直接
curl 'localhost:9200/bank/zhonguobank/_search?pretty' -d '{
"query":{
"term":{
"name":"elastic"
}
}
}'
使用过滤器
如果对得分不感兴趣,可以使用过滤查询代替。
curl 'localhost:9200/bank/zhongguobank/_search?pretty' -d '{
"query":{
"filtered":{
"filter":{
"term":{
"name":"elastic"
}
}
}
}
}'
使用聚合分析结果
Elasticsearch聚合使您能够获取有关搜索结果的元信息,并回答诸如“德克萨斯州有多少账户持有人?”或者“田纳西州的平均账户余额是多少?”您可以在一个请求中搜索文档、过滤搜索结果并使用聚合来分析结果。
例如,下面的请求使用术语聚合按状态对银行索引中的所有帐户进行分组,并按降序返回帐户最多的十个州
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
}
}
}
}
'
响应中的buckets是state字段的值,doc_count显示每个state的帐户数量。例如,您可以看到ID(爱达荷州)中有27个帐户。因为请求设置size=0,所以响应仅包含聚合结果。
{
"took" : 96,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"group_by_state" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 743,
"buckets" : [
{
"key" : "TX",
"doc_count" : 30
},
{
"key" : "MD",
"doc_count" : 28
},
{
"key" : "ID",
"doc_count" : 27
},
{
"key" : "AL",
"doc_count" : 25
},
{
"key" : "ME",
"doc_count" : 25
},
{
"key" : "TN",
"doc_count" : 25
},
{
"key" : "WY",
"doc_count" : 25
},
{
"key" : "DC",
"doc_count" : 24
},
{
"key" : "MA",
"doc_count" : 24
},
{
"key" : "ND",
"doc_count" : 24
}
]
}
}
}
您可以组合聚合以构建更复杂的数据汇总。例如,以下请求在前一个group_by_state聚合内嵌套avg聚合,以计算每个州的平均帐户余额。
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword"
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
'
您可以通过在terms聚合中指定顺序来使用嵌套聚合的结果进行排序,而不必按计数对结果进行排序:
curl -X GET "localhost:9200/bank/_search?pretty" -H 'Content-Type: application/json' -d'
{
"size": 0,
"aggs": {
"group_by_state": {
"terms": {
"field": "state.keyword",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "balance"
}
}
}
}
}
}
'
除了这些基本的存储区和指标聚合,Elasticsearch提供了专门的聚合,可用于多个字段上的操作并分析特定类型的数据,例如日期,IP地址和地理数据。 您还可以将单个聚合的结果馈送到管道聚合中,以进行进一步分析。
聚合提供的核心分析功能可启用高级功能,例如使用机器学习来检测异常。