在谈及 Scala 包之前,我们不妨回顾 Java 包的三大作用:
1、 区分相同名字的类
2、 控制类的访问范围
3、 有助于代码管理
Java 中的打包实际上就是创建了不同的文件夹来管理这些文件管理起来。当使用到命名冲突的类时,可以通过包名.类名的全限定名称来避免歧义。同时, Java 要求:类的源文件在哪里,它所声明的 package 就在哪里。比如说Obj.java文件在项目路径bin/test中,则该源文件内部声明的 package 必须为 bin/test 。
包
在 Scala 中,源码文件的实际位置可以与 package 中声明的目录不一样(但这并不是规范的做法,我们也很少这样做)。在编译之后,编译器仍然会按照 package 声明的目录生成对应的 .class 文件。
Scala 的命名规则规定包名只能包含数字,字母,下划线,圆点(代表子目录),尤其注意包名不可以为 Scala 关键字。通常的命名规范为:com.公司名.项目名.业务模块名。
Scala 也会自动引入一些我们常用的包,如 Java.lang.* 包等。
Scala 引入包的几种方式
我们依旧可以沿袭 Java 的方式来声明一个 Object 实际所处的包位置。比如:
package sclPackage.cn.hlju
class Student {}
它所在的包层次为:sclPackge , cn , hlju 。因此我们还可以根据层次结构来拆开声明:
package sclPackage
package cn
package hlju
class Student {}
Java 严格限制 package 关键字必须出现在源文件的首行。但是 Scala 却没有对此进行限制,甚至说,我们可以在文件的任何一处引入 package 关键字。这使得我们甚至可以仅仅在一个 Scala 源文件内构造出一个复杂的包结构!
package sclPackage.cn{
import sclPackage.cn.hit.Teacher
import sclPackage.cn.hlju.Student
// 这个类位于 sclPackage.cn.hit 下。
package hit{
class Teacher {}
}
// 这个类位于 sclPackage.cn.hlju 下。
package hlju{
class Student {}
}
// 这个类位于 sclPackage.cn 下。
class Obj {}
}
而在编译时,编译器会构建出一个这样的树状目录:
sclPackage.cn
┗ hlju
┗ Student.class
┗ hit
┗ Teacher.class
┗ Obj.class
包权限
Scala 包讲究作用域原则:子包可以直接向上访问父包的内容。在 Java 中,我们必须要借助 import 关键字引入它。
下面三条很重要:
1、 当子包和父包都存在一个重名的类时, Scala 则采取就近原则。
2、 如果要在子包内主动调用位于父包的同名类,则需要指定包名。
3、 父包想要访问子包的内容,需要 import 导入对应的类。
下面代码来演示:
//HjlU包外有一个重名的Student类
class Student{
println("2")
}
package hlju {
//hlju 内有一个 Student 类
class Student {
println("1")
}
// “main” 方法在这里!↓
// Scala 采取就近原则,优先调用 hlju 包下的 Student 。
object Enter{
def main(args: Array[String]): Unit = {
//控制台打印1.
val student : Student = new Student
}
}
}
包对象
在Java中,没有类似于C语言的全局变量的概念:一切函数和变量都归属于类下。(因而又称它们是某个类的方法和属性)
为了摆脱Java的这个局限,Scala中引入了包对象的概念。它对同一个包下的其它类提供类似于全局的方法和属性。
Scala 包对象的简要特点
- 关键字为
package object,后接包的名字。 - 每一个包都可以(但最多只能)声明一个包对象。
- 包对象只对当前包下的类可见,或者说不对其子包下的类可见。
举个例子,在sclPackage包下生成一个包对象,并定义一个packageVar和packageFun:
package object sclPackage {
val packageVar : Int = 100
def packageFun = "Hello,Scala!"
}
之后,在sclPackage下的类可以引用包对象声明的变量或者方法,但是sclPackage下其它子包内的object或者class不能使用这些方法。
通过反编译来查看包对象的工作机制
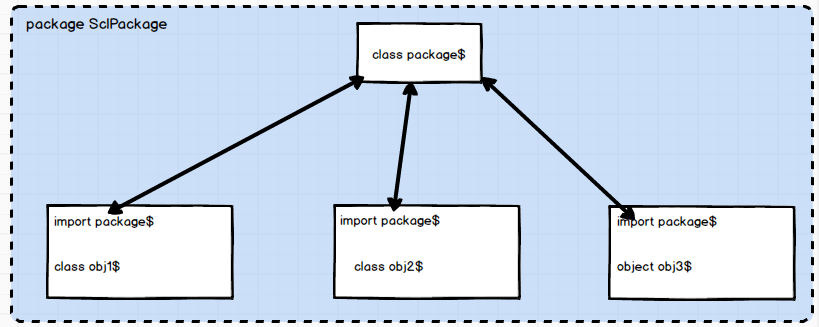
为了大致了解Scala包对象的底层实现,我们打开jd-gui来查看它是如何工作的。打开classes目录可以发现,包对象经编译生成了package.class和package$.class。
所有包对象在底层生成的文件名都叫package.class,它和包名没有关系。并且, package 是一个关键字,我们无法通过手动的方法来创建名字为 package 的类。
在源码文件声明包对象时,我们只需要用包名指定名称即可。

如图所示,在 sclPackage 包下的 Obj1,Obj2,Obj3 都可以直接访问并使用包对象当中的内容。这颇有几分声明“头文件”的意思:
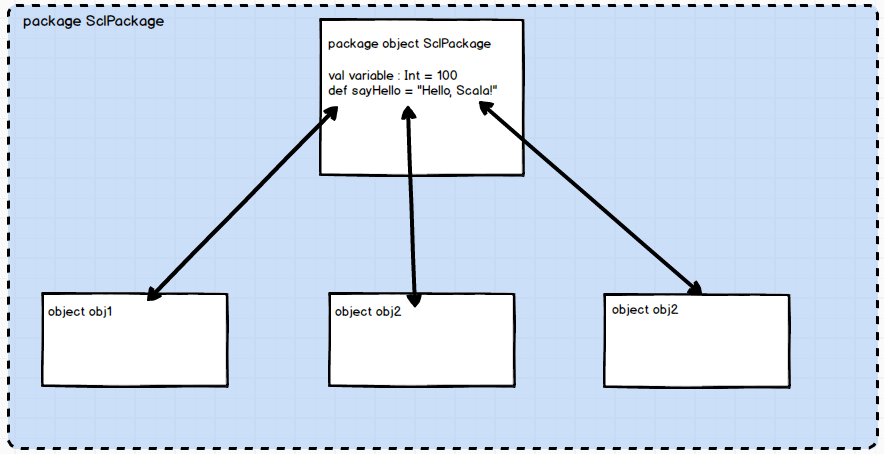
而在底层中,我们在声明的”全局变量”,“全局函数”都保存在本包内的package$类中,它提供公有的访问方法。该包下的其它.class在编译时会自动地引入package$,进而使得该包下的类得以调用其变量和属性。
Scala 引入包
Scala 引入包同样也是 import 关键字。而与 Java 相比,Scala 引入包有以下细节:
- Scala 中,
import关键字可以出现在任何地方。import引入的类只能在对应的作用域下使用。这样的优势就是:仅仅在需要某个组件的时候才引入包,提高了效率(类似于懒加载)。比如下面的示例:在Box 类中导入的 BeanProperty 注解不会影响到 Closet 。因此我们不能在 Closet 类中直接使用此注解。
class Box{
import scala.beans.BeanProperty
@BeanProperty val scrip : String = "Wow"
}
class Closet{
//Oops!
@BeanProperty val clothes : String = "dress"
}
- Java中使用通配符”*”来表示引入某个包所有的类,Scala中使用下划线”_”来表示引入某个包内所有的类。比如:引入scala.collection.mutable包下的所有类:
import scala.collection.mutable._
- Scala中可以使用选择器来选择引入包的内容,比如:只引入scala.collection.mutable下的HashMap和HashSet类。
import scala.collection.mutable.{HashMap,HashSet}
- 当引入多个包导致有重名类时,可以在引入时使用
{A => B}的格式对其进行重命名作区分。比如:同时使用到了可变的HashMap和不可变的HashMap,这时对其中一个类进行重命名,避免混乱。重命名的类只对该文件内有效。
import scala.collection.mutable.HashMap
// 将其中一个重名的类“重命名”为 ImmutableHashMap。
import scala.collection.immutable.{HashMap=>ImmnutableHashMap}
- 承接上述的情况,也可以选择将不用的类屏蔽掉。格式为:
{A=>_}。”=>”后面的_代表屏蔽,隐去。但是要注意,单独的_代表通配符。比如:引入
scala.collection.immutable包下除了HashMap类以外的所有类。这是一个比较令人迷惑的写法:它首先将
immutable下的HashMap类使用=>_去掉,然后又使用_将其它的所有类引入。
import scala.collection.immutable.{HashMap=>_,_}
在隐去掉该类之后,IDEA编译器将不再显示地提供有关该类的代码提示。
如此一看, Scala 的引入规则要比 Java 的引入规则更加灵活。然而,更加灵活则意味着更加复杂。
另外提示一点:_ 符号在 Scala 中有非常多的使用:它通常代表了“所有”或者“忽略”的含义。我们在模式匹配章节中也会多次使用这个 _ 符号。
Scala控制修饰符
回顾 Java 的四种访问控制修饰符
| 修饰符 | 同类 | 同包 | 子类 | 不同包 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | |
| default(缺省) | √ | √ | ||
| private | √ |
其中,public和default可用于修饰类。一个.java文件下至多只能声明一个public 的class。
介绍 Scala 的控制修饰符
首先给出示例代码来直观感受一下在Scala的属性中加或者不加private关键字的区别:
class Box{
val accessibleVal : Int = 100
private val inaccessibleVal : Int = 200
}
在 Scala 中,如果不对 class 的属性声明任何额外的修饰符,那么就可以通过.运算符直接获取它们(相当于Java 中的 public )。
如果额外使用了private修饰符修饰,则不可以直接通过.运算符获取。(相当于 Java 中的 private )
无论在 .scala 文件中这些属性是否被 private 修饰符修饰,在底层编译成 .class 文件时都会被 private 关键字修饰。而在 .scala 文件中没有直接使用 private 修饰符修饰的属性(比如代码块中的accessibleVal属性),底层又额外提供了类似于 set/get (实际是 xxx_eq$ 和 xxx )的公开方法,从而在Scala层面上看起来那些没有被private关键字修饰的属性,是可以直接读写的。
和Java的控制修饰符相比起来, Scala 与其还有如下的差别:
private修饰符保护的属性仅对同一个类内和伴生对象可见。protected修饰符要比 Java 中更加严格:只允许子类访问。- Scala中没有
public关键字。不能显式地(也没有这个必要)用该关键字去修饰属性和方法。 - 类内通过
def定义的方法,在底层编译 class 文件时默认为public。
Scala额外提供包访问权限
若一个类内属性被private (或者是protected,这里以private举例子) 修饰符修饰:
private val inaccessibleVal : Int = 200
则除了该类及其伴生对象以外,无法直接去使用.运算符来访问该属性。而Scala提供了包访问权限的概念:
private[ScalaPackage] val inaccessibleVal : Int = 200
上述代码块的含义是:虽然该变量被声明了private,但是对ScalaPackage及其子包下的类可见。
简要知识回顾:在Scala中编写一个OOP程序
- 回顾Scala的输入类StdIn。
- 回顾Scala的主构造器,辅助构造器,先后调用的顺序。
- 牢记:Scala中的if分支具备返回值,默认返回最后一条有返回值的语句。
编写一个简单的Account类,具有卡号,卡密,余额属性。其中余额是可变属性。编写一个查询余额的方法:前提是输入的密码正确。
object BankDemo {
def main(args: Array[String]): Unit = {
//Tip:Scala中的输入需要借助StdIn; Scala中的import可以声明在任何地方。
import scala.io.StdIn
val account: Account = new Account("2020", "1234", 23)
val str: String = StdIn.readLine()
print(s"exit code ${account.query(str)}")
}
}
//Tip:Scala主构造器。可以在参数列表里直接声明该类的属性,方便赋值。
class Account(val accountNo: String, var pwd: String) {
//Tip:Scala中使用"_"表示对属性赋默认值。注意,必须要显示指定该属性的数据结构。
//Tip:允许改变的值使用var来修饰。
var balance: Double = _
//Tip:当主构造器被执行,会像执行函数一样执行主构造器内除了声明以外的语句。
print(s"开户账号:$accountNo\t")
//Tip:声明了辅助构造器,格式为:def this(){}...
def this(account: String, pwd: String, balance: Double) {
this(account, pwd)
this.balance = balance
printf(s"余额:$balance")
}
def query(inputPwd: String): Int = {
//Tip:Scala的if语句是具备返回值的。
if (!this.pwd.equals(inputPwd)) {
println("密码错误。")
-1
} else {
println(s"显示余额:$balance")
1
}
}
}