我们在初学Java的时候,老师总不忘告诉我们Java所具备的一个优点:跨平台特性。那反过来,为什么C/CPP语言就不能跨平台呢?笔者查阅了以下,有感而发。文章包含两部分:
1、C语言程序无法跨平台的理由
2、简单看看Java的字节码文件结构
笔者对计算机系统和原理的认识水平有限,因此有理解错误之处,请多谅解。同时也感谢网上前辈无私的经验分享~
一个可执行文件的诞生
众所周知,无论你是用何种语言实现的Hello World程序,最后能够让计算机可以理解的,一定是纯二进制码编制成的机器语言。包括我们此时此刻的QQ聊天,或者是腾讯会议,这些程序在CPU的层面来看,不过是连串的0101代码。倘若再深入到硬件层面,那就是与非门电路了。
感谢有如此多优秀的IDE(比如Visual Studio,Code Blocks)让我们轻松愉快地编写.c文件,以至于我们只需要简单的点一下run按钮,这个源文件就被自动编译且被执行,比如说一个这样的hello.c:
#include <stdio.h>
int main(){printf("hello,c!");return 0;}
IDE实际上替我们完成了这样的流程:
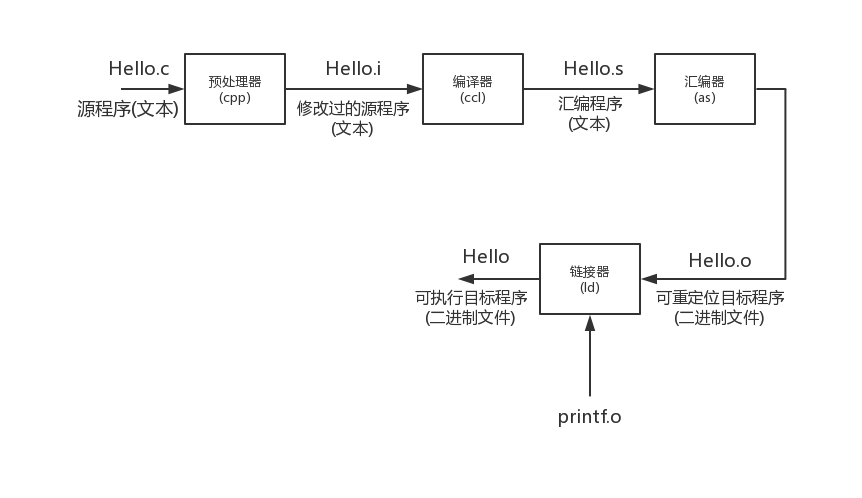 简而言之,这个
简而言之,这个 Hello.c经过了 预处理,编译,汇编,链接的过程,最后生成了一个可以执行的直接二进制文件。
汇编语言
汇编语言(英语:assembly language)是一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同的设备中,汇编语言对应着不同的机器语言指令集。一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。
在计算机诞生之初(到现在),计算机只认识0或1。那个时代的科学家只能通过纸带打孔的方式来告诉计算机:有孔代表1,反之则为0。这样一来,终于实现了人机交互,然而效率感人。
科学家们逐渐发现,无论程序多么复杂,计算机指令数量是有限的,唯一的区别就体现在了数据的不同。而这些指令需要被芯片固定识别,芯片内使用电子管组成的与非门电路组合来实现。
所以科学家们后来又发明了汇编语言,针对于这些固定的指令,使用符号来代替冗长的01代码,也代码的可读性发生了巨大的提升。
在汇编程序完成之后,需要再有一个专门的程序(汇编器)来把编写的汇编程序编译成0和1.这样计算机也可以识别了,而汇编语言本身也方便了程序的编写和阅读。
但是新的问题又出现了:不同公司所生产的CPU芯片,它们的指令集并不相同(比如Intel代表的复杂指令集阵营,ARM代表的精简指令集阵营,不同公司设计指令集的思路是截然不同的)。
高级语言
随着程序的越来越复杂,当时的程序员们越来越迫切地希望能有一个崭新的编程语言:它不依赖于计算机硬件,人们无论在任何型号的计算机都可以使用统一的写法实现编程工作。
在1954年,第一个完全意义上的高级编程语言FORTRAN诞生。从此之后,编程工作就脱离了特定机器的局限性。在第一个编程语言诞生至今,已经有共计几百种高级语言诞生,比如说C,BASIC,CPP,包括Java。
当我们使用C语言进行编程时,首先要使用编译器将源文件编译为汇编程序,再使用汇编器编译成0,1。一个可执行文件就如此诞生了。
跨硬件还不够
尽管高级语言帮助程序员实现了跨硬件的飞跃,但是随着操作系统的流行,又又又出现问题了:同一个.c文件在不同平台下,运行的结果可能又不相同。
原因就是不同平台所采用的编译器并不完全一致。譬如说同一个int类型的数据,有些编译器会为其分配2字节空间,而另一些编译器会为其分配4字节的空间。因此在A平台内正常运行的程序,在B平台却可能出现内存溢出的错误。
在不同的平台下,同一个Hello.c最后所编译出来的文件格式并不同:
- Windows下的编译结果是
Hello.exe。 - Linux下的编译结果是
Hello。 - Mac下的编译结果是
Hello.out。
我们在Windows上使用的应用都是编译好的程序
大部分的netizens正在使用或使用过微软公司的Windows系统。俗话说有需求就会有市场:各路软件开发商们就基于Windows平台上进行软件开发,最后交付到用户手上的,是一个包含了可执行文件.exe的文件夹。
这个.exe文件实际上在Windows平台下由源文件编译生成的可执行二进制文件,而Windows用户运行它们自然没有什么问题。
出于用户体验的考虑,用户只需要关心一款软件能够正常使用,就足够了。出于盈利为目,部分厂商不会将自己的源代码公布出去,因为这就相当于向别人公布了所有的技术细节。
但这个.exe及其依赖被放置到Linux平台下是否还能正常运转呢?恐怕不行。
有时需要手动编译源码
而对于开源软件来说,官网往往会提供这个软件的源码文件下载包,或者留下GitHub链接。
开发人员有时从官网中下载源码文件,然后通过自己平台本地的c语言编译器(诸如gcc这样的工具)编译成本平台内可执行的二进制文件,然后再执行,尤其是对于使用Linux作为开发环境的人员。
就好比我们去市场买菜:市场上卖的都是一样的食材,而根据每个人的口味不同,这些相同的食材在不同人的手里,做出来的菜也不尽相同。
而在计算机中,这个区别就体现了平台,或者是处理器型号的不同,以至于导致同一份C语言编写的代码在不同的环境下可能出现不同的运行结果。由于这些区别,C/CPP语言不具备跨平台的特性。在这种情况下,我们不得不下载源码,然后手动用对应的编译工具来编译它,使其适配我们的运行环境。
比如说:如果我们需要在Linux环境中使用Redis工具,就需要先使用make命令编译才可以使用。
Hadoop也建议下载源码并使用编译器编译,然后再使用。
鉴于性能问题以及某些Java类库的缺失,对于某些组件,Hadoop提供了自己的本地实现。 这些组件保存在Hadoop的一个独立的动态链接的库里。这个库在*nix平台上叫libhadoop.so.
Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用Java来解决,所以就引入了本地库(Native Libraries) 的概念。说白了,就是Hadoop的某些功能,必须通过JNT来协调Java类文件和Native代码生成的库文件一起才能工作。Linux系统要运行Native代码,首先要将Native编译成目标CPU 架构的[.so]文件。而不同的处理器架构,需要编译出相应平台的动态库[.so] 文件,才能被正确的执行,所以最好重新编译一次Hadoop源码,让[.so]文件与自己处理器相对应。
Native Library,一般我们译为本地库或原生库,是由C/C++编写的动态库[.so],并通过JNI(Java Native Interface)机制为java层提供接口。应用一般会出于性能、安全等角度考虑将相关逻辑用C/C++实现并编译为库的形式提供接口,供上层或其他模块调用。
跨平台语言Java从此诞生
到前三节为止,我们了解到了C/C++语言仍然受到跨平台的限制。那有没有一种方法,能够让高级语言实现跨平台的运行呢?
我们思考实际的应用背景;如果前端传输的是XML格式的文件,而后台最终需要以json的格式存储到数据,该如何解决呢?我们直接创建一个适配器Adaptor,在数据传输之前实现XML和json文件的转化当然就可以了!这是典型的适配器设计模式。
Java伴随着它的虚拟机JVM从此登场。它和C/CPP语言最大的不同就是:首先,Java代码依托于JVM虚拟机运行。其次,这个Java代码经编译后生成的并不是纯二进制的机器指令,而是一个非纯二进制码的字节码文件.class。而这个文件,与计算机的硬件,平台都没有任何的关系,只与JVM有关系。
真正赋予Java跨平台特性的是JVM虚拟机
只有JVM能够理解.class字节码文件真正的含义,并正确的将它翻译成机器码并执行。换句话说,不论是在Linux平台还是在Windows平台,只要安装了适配的JVM虚拟机,Java代码就可以被顺利执行。
对于Java程序员而言,他不用再考虑被javac编译的字节码文件要在哪个平台运行,反正只需要安装对应平台的JDK环境就可以了:不论是哪个平台的JVM来执行代码,它要求的字节码文件的结构格式是一致的。
笔者认为,后续的虚拟机,虚拟容器技术的发展,其核心思想也与JVM无异,那就是:适配器设计模式。
JVM机怎么去理解class文件?
嗯……研究JVM也是一门玄学。由于笔者的水平和精力有限,因此有关该部分的详细内容,笔者决定在后续的JVM学习中进行补充。
笔者在第一篇博客中曾简单提及了一点.class文件的内容。(为什么用txt打开.class文件会乱码,而打开.java文件却不会乱码?)这一次,我们换一个视角再来看看.class文件内部:
首先需要安装NotePad++,然后安装HexEditor_0.9.6_x64插件,保证我们以16进制的格式阅览.class文件。具体安装很简单,笔者在这里也不展开叙述了。
我们使用NotePad++编写一个简单的JavaClass.java文件:
class JavaClass {
public static void main(String[] args){
System.out.println("Hello Java");
}
}
然后通过javac生成对应的Java.class文件,并打开它:
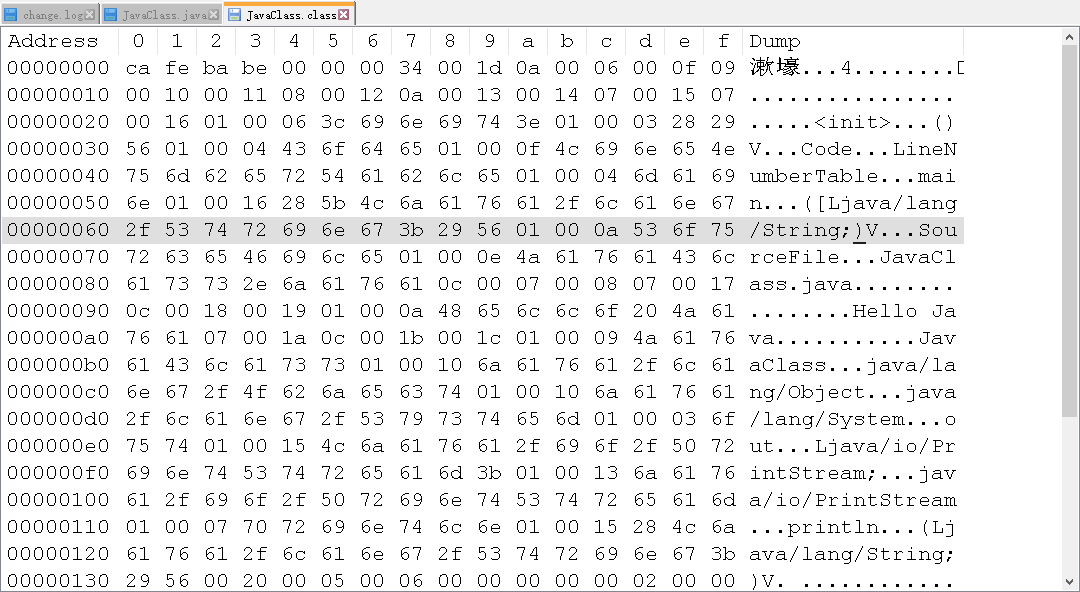 简单的一句代码最后浓缩成了一大串数字字母组成的16进制符号。其中,
简单的一句代码最后浓缩成了一大串数字字母组成的16进制符号。其中, xx代表着1个字节。既然JVM能够根据这些符号最后在控制台中输出 Hello Java,说明这些符号一定遵守着某些特定法则:即 Java虚拟机规范。
字节码结构
我们可以参照这个表结构来翻译我们的HelloJava.class文件。
| 类型 | 名称 | 说明 | 长度 |
|---|---|---|---|
| u4 | magic | 魔数,识别Class文件格式 | 4个字节 |
| u2 | minor_version | 副版本号 | 2个字节 |
| u2 | major_version | 主版本号 | 2个字节 |
| u2 | constant_pool_count | 常量池计算器 | 2个字节 |
| cp_info | constant_pool | 常量池 | n个字节 |
| u2 | access_flags | 访问标志 | 2个字节 |
| u2 | this_class | 类索引 | 2个字节 |
| u2 | super_class | 父类索引 | 2个字节 |
| u2 | interfaces_count | 接口计数器 | 2个字节 |
| u2 | interfaces | 接口索引集合 | 2个字节 |
| u2 | fields_count | 字段个数 | 2个字节 |
| field_info | fields | 字段集合 | n个字节 |
| u2 | methods_count | 方法计数器 | 2个字节 |
| method_info | methods | 方法集合 | n个字节 |
| u2 | attributes_count | 附加属性计数器 | 2个字节 |
| attribute_info | attributes | 附加属性集合 | n个字节 |
我们根据Java字节码结构表,就可以解析NotePad++显示的16进制文件所涵盖的信息了。另外,我们从这个表中可以发现,.class文件只有两种数据类型:无符号数,还有表。
| 数据类型 | 定义 | 说明 |
|---|---|---|
| 无符号数 | 无符号数可以用来描述数字、索引引用、数量值或按照UTF-8编码构成的字符串值。 | 其中无符号数属于基本的数据类型。以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节 |
| 表 | 表是由多个无符号数或其他表构成的复合数据结构。 | 所有的表都以“_info”结尾。由于表没有固定长度,所以通常会在其前面加上个数说明。 |
从这两个表中,我们就可以知道,即便是一个HelloWorld级别的.class,也包含着如此多的内容。表中的每一个结构都值得展开讨论,笔者在正式研究.class以及JVM原理时,会仔细地研究该部分。
当然,我们还可以借助javap命令来分析。javap是JDK自带的反编译工具,能够解析出当前类对应的code区(汇编指令)、本地变量表、异常表和代码行偏移量映射表、常量池等等信息。:
$ javap -verbose JavaClass.class
程序最终会返回:
Classfile /C:/Users/liJunhu/Desktop/x学习笔记/Scala分支/scalaTest/JavaClass.class
Last modified 2020-5-28; size 422 bytes
MD5 checksum 75803102330020b05d871810e7dbe63c
Compiled from "JavaClass.java"
class JavaClass
minor version: 0
major version: 52
flags: ACC_SUPER
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // Hello Java
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // JavaClass
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 main
#12 = Utf8 ([Ljava/lang/String;)V
#13 = Utf8 SourceFile
#14 = Utf8 JavaClass.java
#15 = NameAndType #7:#8 // "<init>":()V
#16 = Class #23 // java/lang/System
#17 = NameAndType #24:#25 // out:Ljava/io/PrintStream;
#18 = Utf8 Hello Java
#19 = Class #26 // java/io/PrintStream
#20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V
#21 = Utf8 JavaClass
#22 = Utf8 java/lang/Object
#23 = Utf8 java/lang/System
#24 = Utf8 out
#25 = Utf8 Ljava/io/PrintStream;
#26 = Utf8 java/io/PrintStream
#27 = Utf8 println
#28 = Utf8 (Ljava/lang/String;)V
{
JavaClass();
descriptor: ()V
flags:
Code:
stack=1, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
LineNumberTable:
line 1: 0
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #3 // String Hello Java
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
LineNumberTable:
line 5: 0
line 6: 8
}
SourceFile: "JavaClass.java"
一个小小小彩蛋
我们仔细观察这个16进制文件的前4个字节:
嗯,其值为0xCAFE BABE。它的值就和名称一样有意思。魔数就是用来区分文件类型的一种标志,一般都是用文件的前几个字节来表示。比如0xCAFE BABE表示的是class文件,那么为什么不是用文件名后缀来进行判断呢?因为文件名后缀容易被修改啊,所以为了保证文件的安全性,将文件类型写在文件内部可以保证不被篡改。 至于为什么class文件用的是0xCAFE BABE呢…….
