1 Zookeeper特性
- 一致性:zookeeper中的数据按照顺序分批入库,且最终一致!
- 原子性:一次数据更新要么成功,要么失败。
- 单一视图:全局数据一致,每个server保存一份相同的数据副本,client无论连接到哪个server,数据都是一致的。
- 可靠性:每次对zk的操作状态都会保存到服务端,每个server保存一份相同的数据副本。
- 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行。
- 实时性,在一定时间范围内,client能读到最新数据。
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务(集群选择奇数的原因)。
2 Zookeeper数据结构
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode。每个Znode可以类似看作是一个目录,其下可以创建子目录。
很显然zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为”znode”,每一个znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识
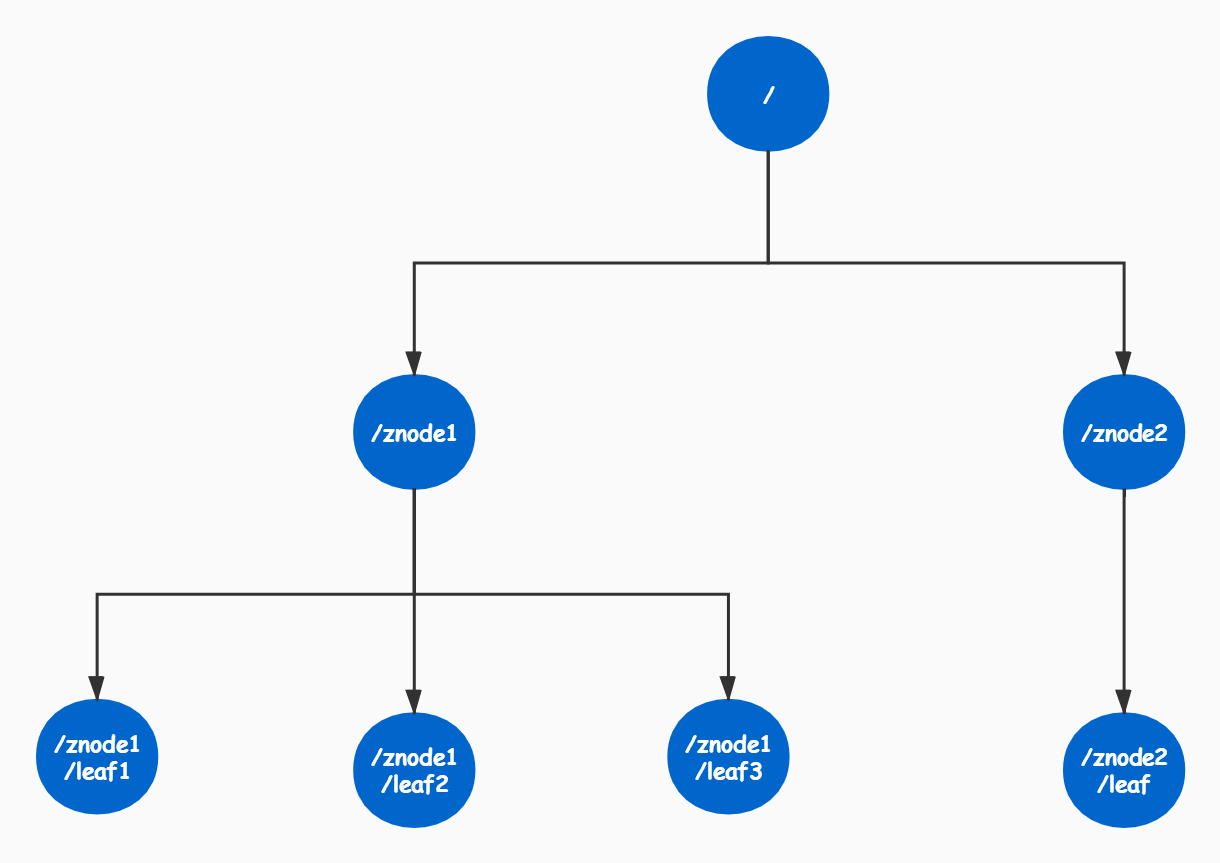
2.1 Znode有两种类型:
短暂(ephemeral)(create -e /app1/test1 “test1” 客户端断开连接zk删除ephemeral类型节点) 持久(persistent) (create -s /app1/test2 “test2” 客户端断开连接zk不删除persistent类型节点)
2.2 Znode有四种形式的目录节点(默认是persistent )
PERSISTENT 持久化 PERSISTENT_SEQUENTIAL(持久序列/test0000000019 ) EPHEMERAL 临时 EPHEMERAL_SEQUENTIAL( 临时序列/test0000000019 )
| 类型 | 描述 |
|---|---|
| PERSISTENT | 持久化节点 |
| PERSISTENT_SEQUENTIAL | 顺序自动编号持久化节点,这种节点会根据当前已存在的节点数自动加1 |
| EPHEMERAL | 临时节点, 客户端session超时这类节点就会被自动删除 |
| EPHEMERAL_SEQUENTIAL | 临时自动编号节点 |
3 Java操作Zookeeper
3.1 Java操作zookeeper代码示例
- 引入maven依赖
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
- Zookeeper客户端连接
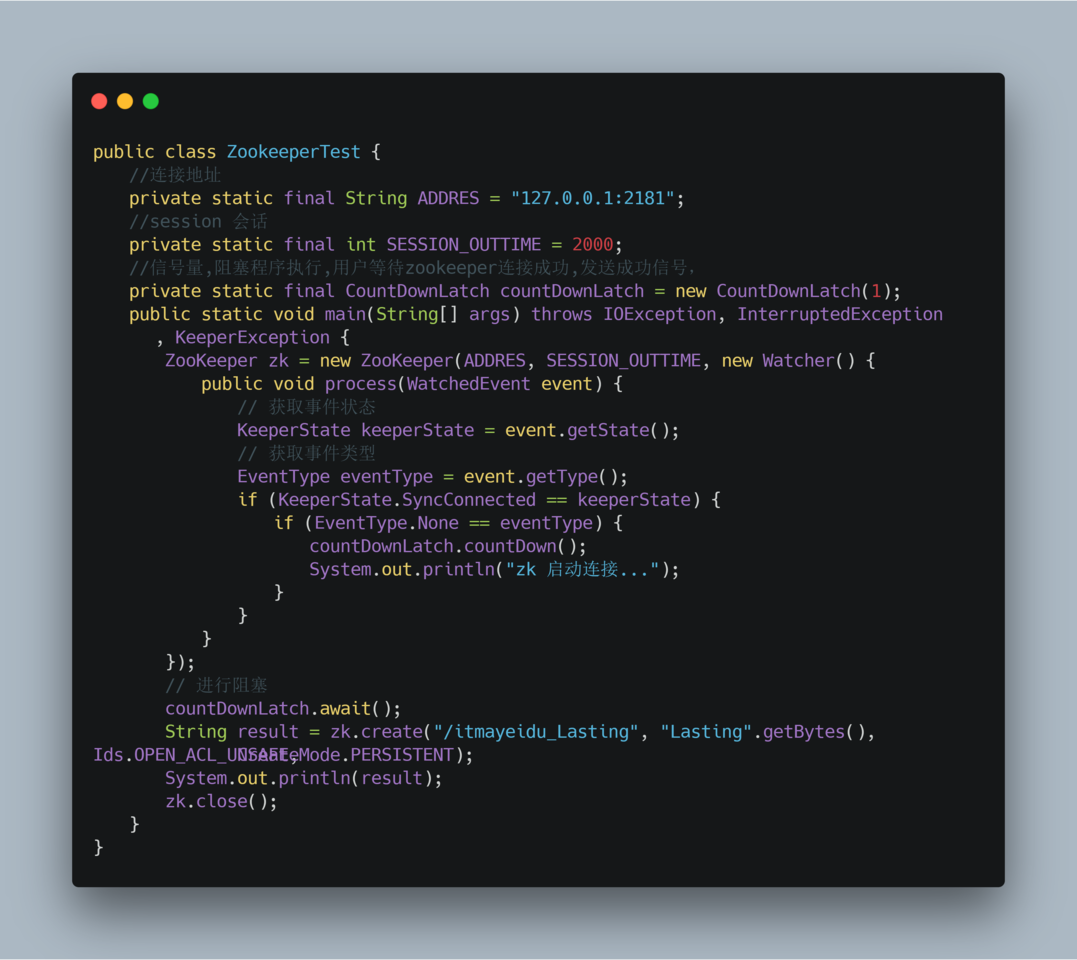
- 创建Zookeeper节点信息
//创建持久节点,并且允许任何服务器可以操作
String result = zk.create("/znode1", "znode1".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
System.out.println("result:" + result);
//创建临时节点
String result = zk.create("/znode2", "znode2".getBytes(), Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
System.out.println("result:" + result);
3.2 Watcher
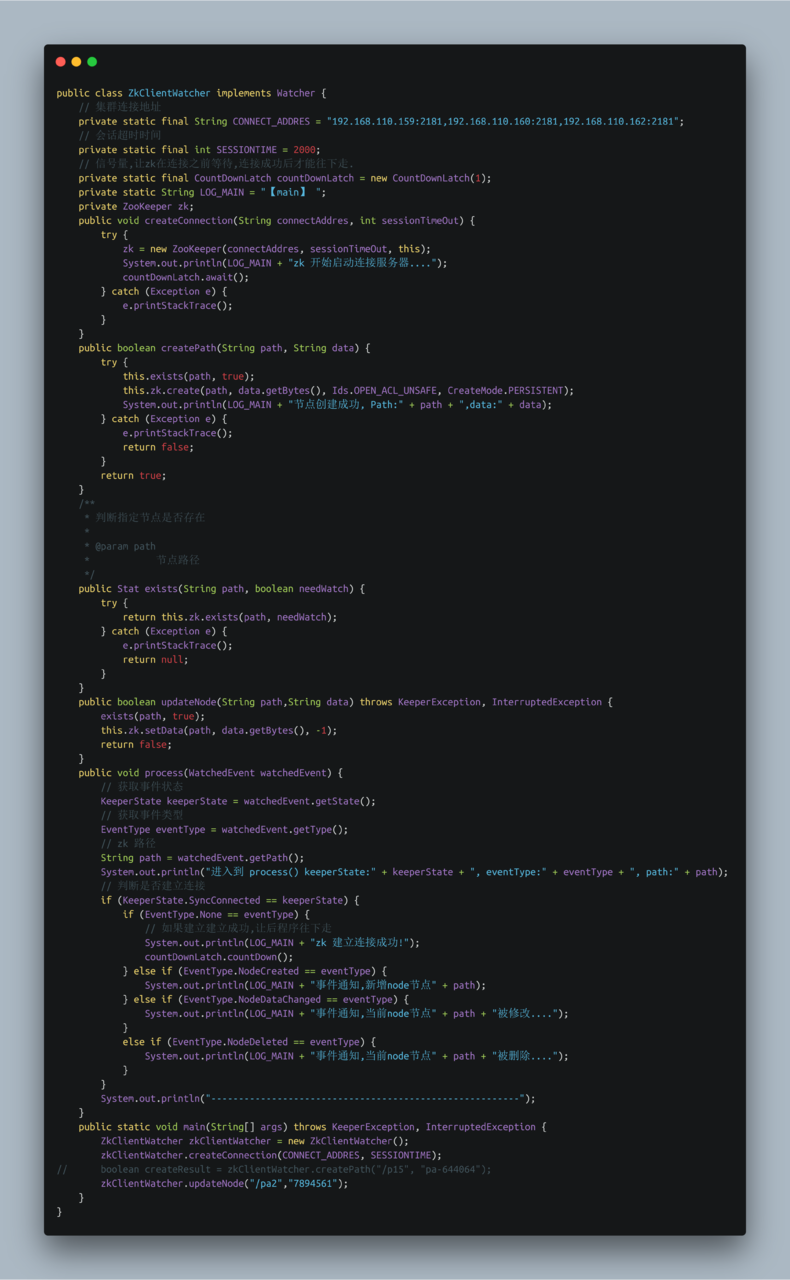
在ZooKeeper中,接口类Watcher用于表示一个标准的事件处理器,其定义了事件通知相关的逻辑,包含KeeperState和EventType两个枚举类,分别代表了通知状态和事件类型,同时定义了事件的回调方法:process(WatchedEvent event)。
| KeeperState | EventType | 触发条件 | 说明 |
|---|---|---|---|
| None(-1) | 客户端与服务端成功建立连接 | ||
| SyncConnected(0) | NodeCreated(1) | Watcher监听的对应数据节点被创建 | |
| SyncConnected(0) | NodeDeleted(2) | Watcher监听的对应数据节点被删除 | 此时客户端和服务器处于连接状态 |
| NodeDataChanged(3) | Watcher监听的对应数据节点的数据内容发生变更 | ||
| NodeChildChanged(4) | Wather监听的对应数据节点的子节点列表发生变更 | ||
| Disconnected(0) | None(-1) | 客户端与ZooKeeper服务器断开连接 | 此时客户端和服务器处于断开连接状态 |
| Expired(-112) | Node(-1) | 会话超时 | 此时客户端会话失效,通常同时也会受到SessionExpiredException异常 |
| AuthFailed(4) | None(-1) | 通常有两种情况,1:使用错误的schema进行权限检查 2:SASL权限检查失败 | 通常同时也会收到AuthFailedException异常 |
- Watcher代码
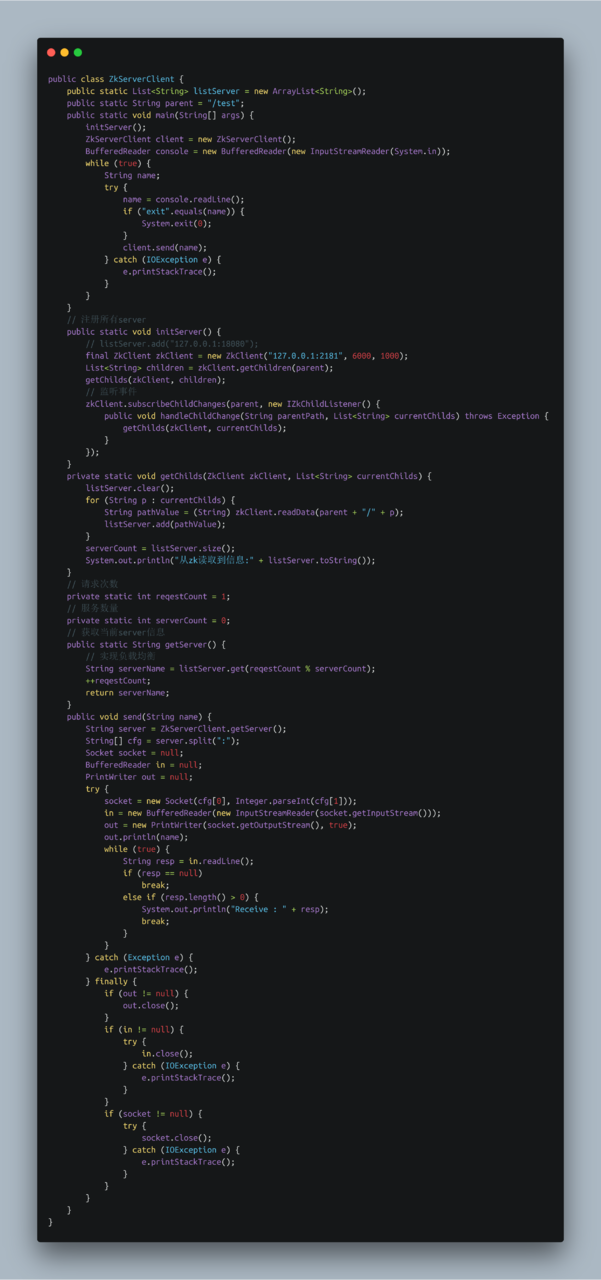
3.3 使用Zookeeper实现负载均衡原理
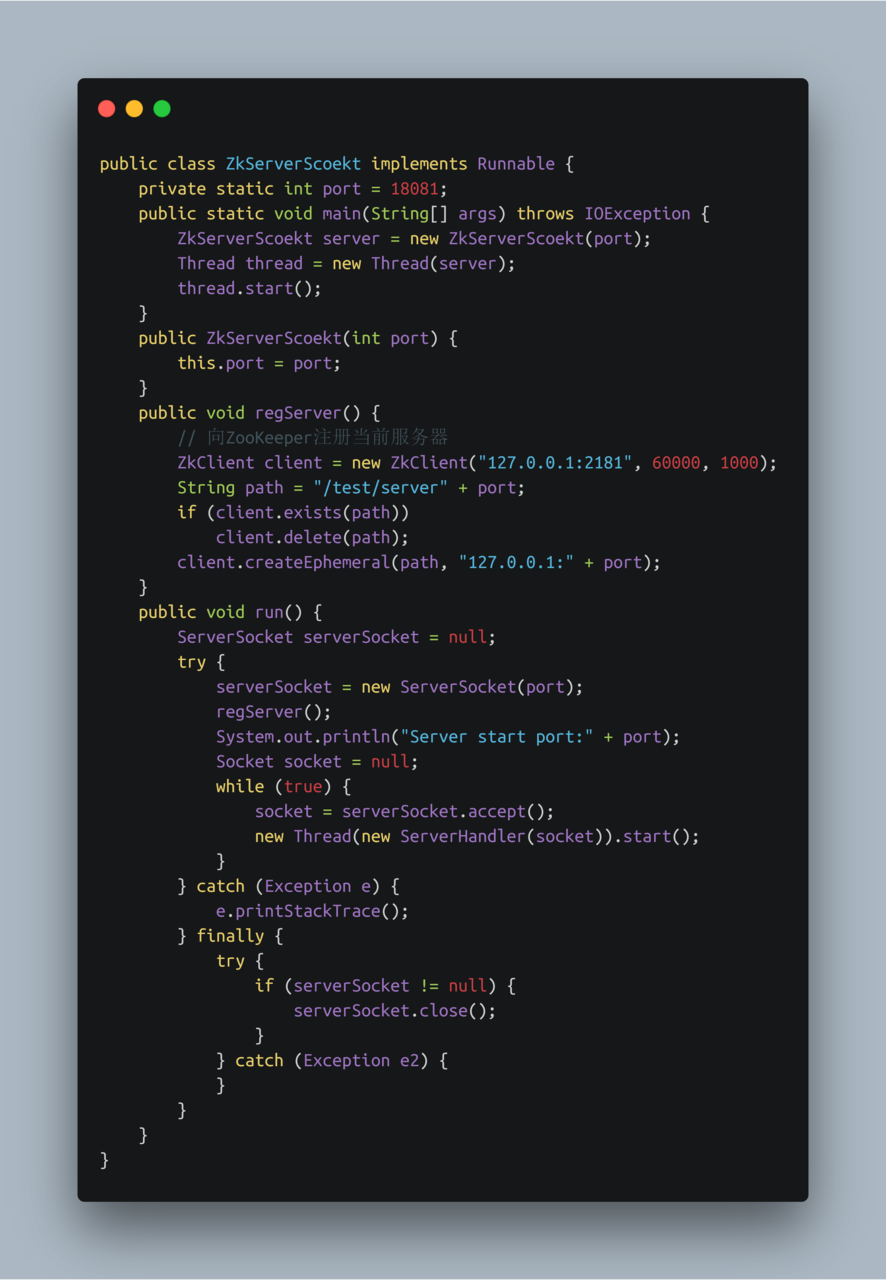
使用Zookeeper实现负载均衡原理,服务器端将启动的服务注册到,zk注册中心上,采用临时节点。客户端从zk节点上获取最新服务节点信息,本地使用负载均衡算法,随机分配服务器
- 引入maven依赖
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.8</version>
</dependency>
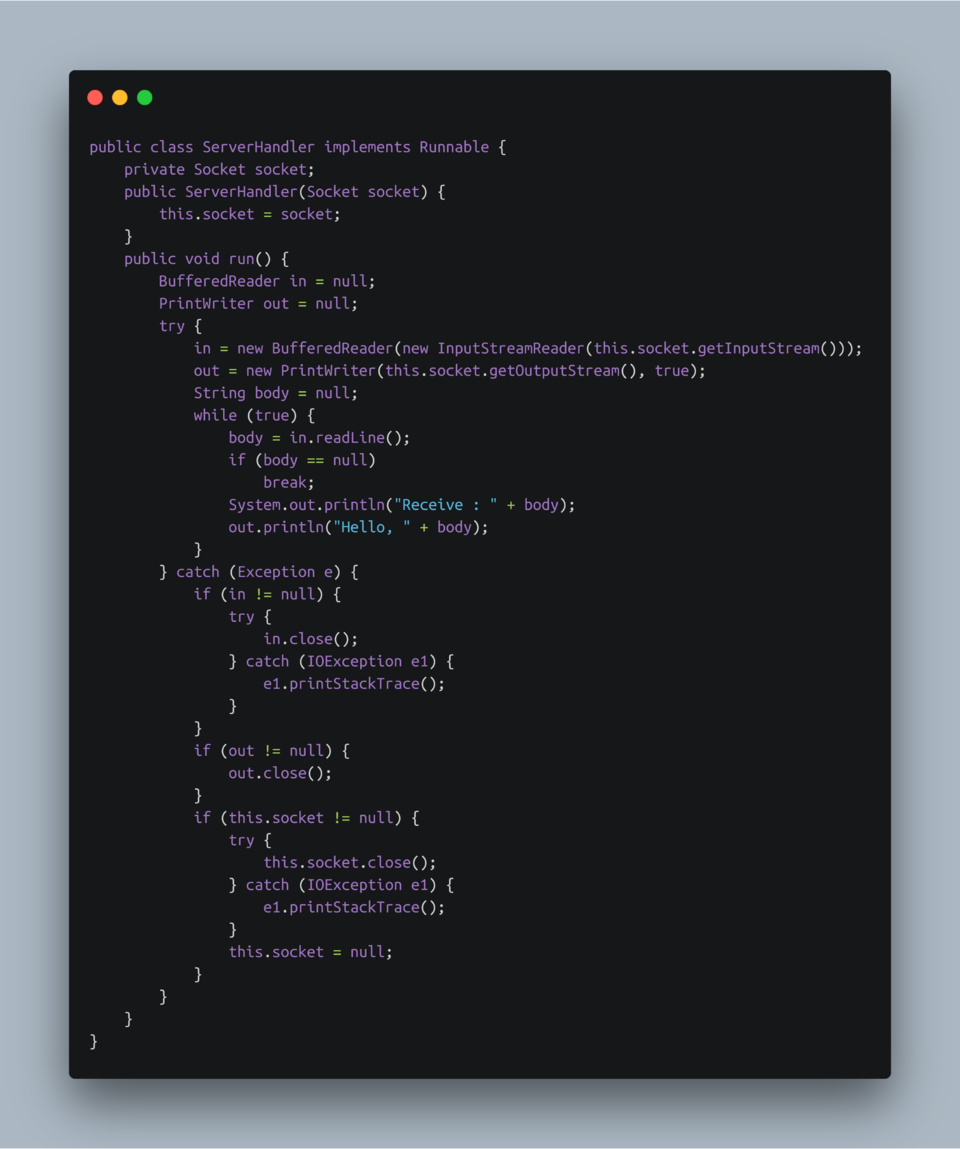
- 创建Server服务端
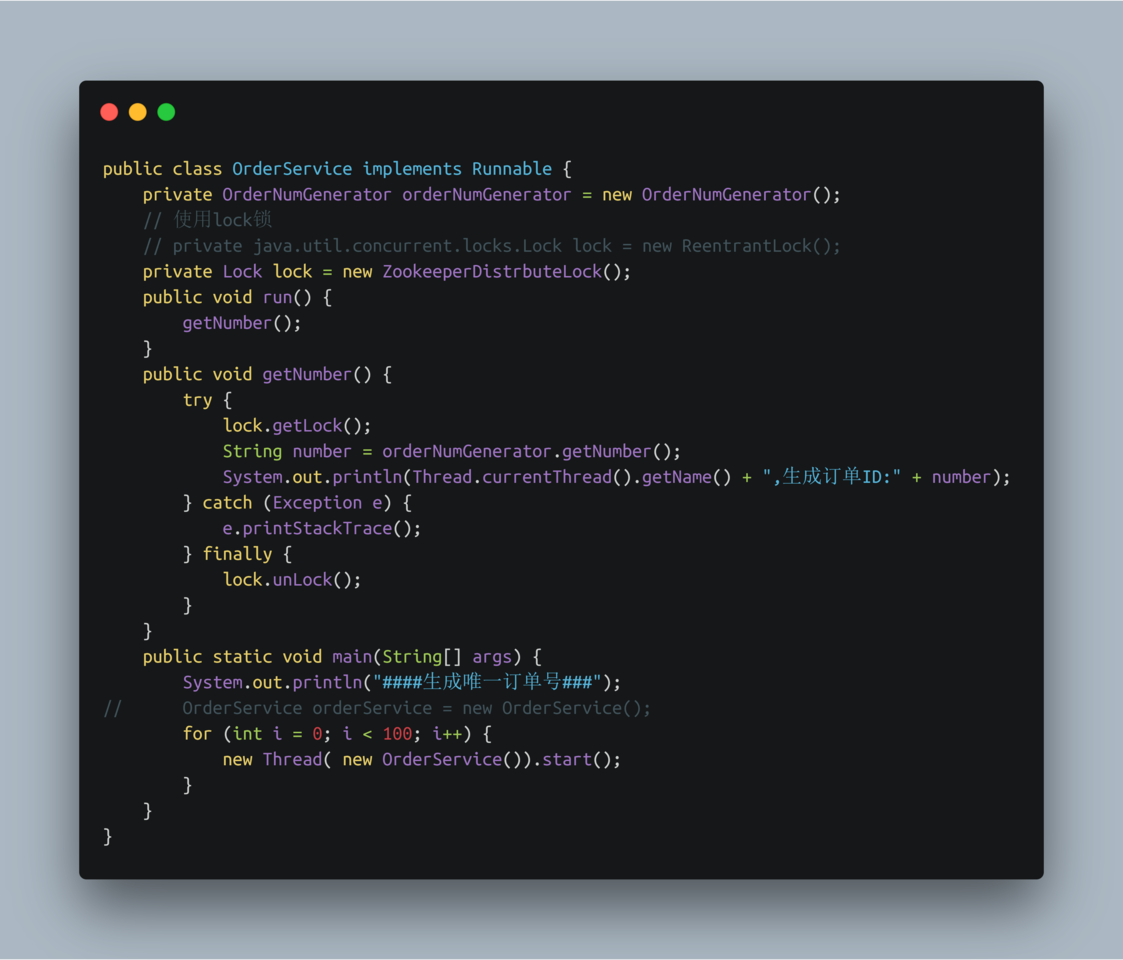
3.4 Zookeepers实现分布式锁
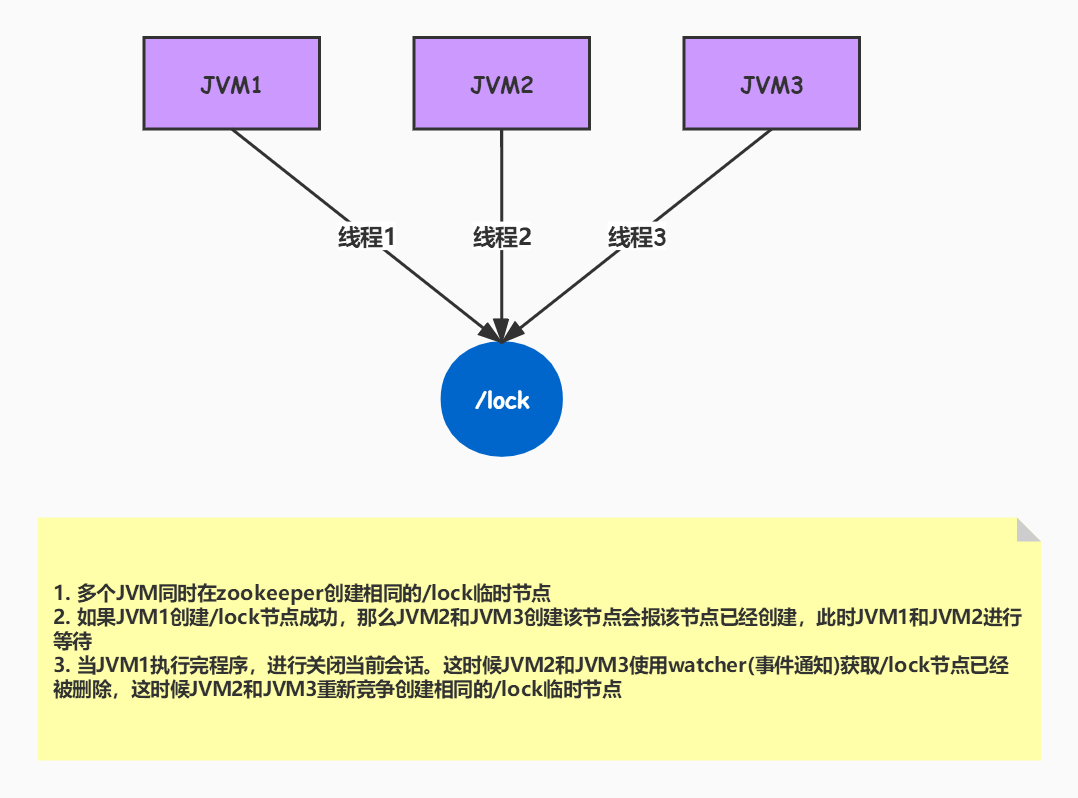
使用zookeeper创建临时序列节点来实现分布式锁,适用于顺序执行的程序,大体思路就是创建临时序列节点,找出最小的序列节点,获取分布式锁,程序执行完成之后此序列节点消失,通过watch来监控节点的变化,从剩下的节点的找到最小的序列节点,获取分布式锁,执行相应处理,依次类推……
- 引入Maven依赖
<dependency>
<groupId>com.101tec</groupId>
<artifactId>zkclient</artifactId>
<version>0.10</version>
</dependency>
- 创建Lock接口

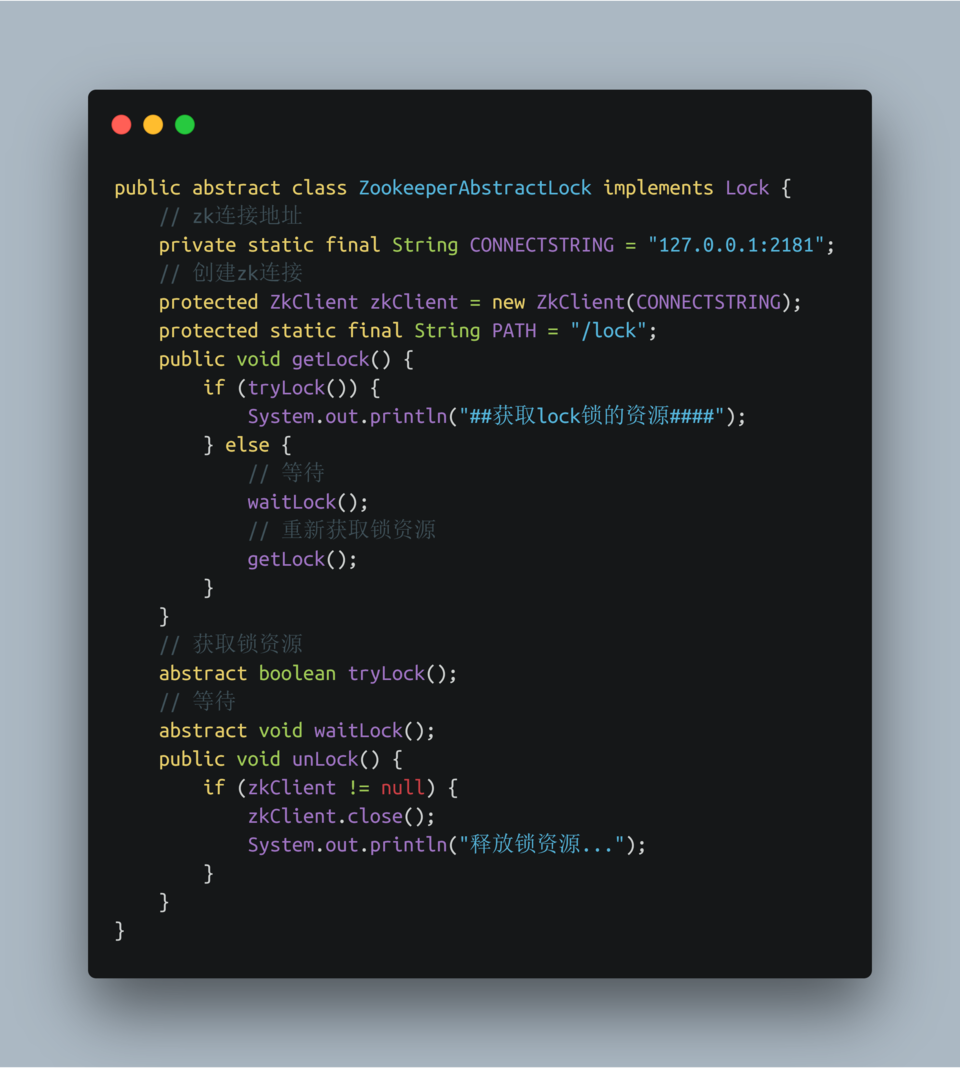
- 创建ZookeeperAbstractLock抽象类
- ZookeeperDistrbuteLock类
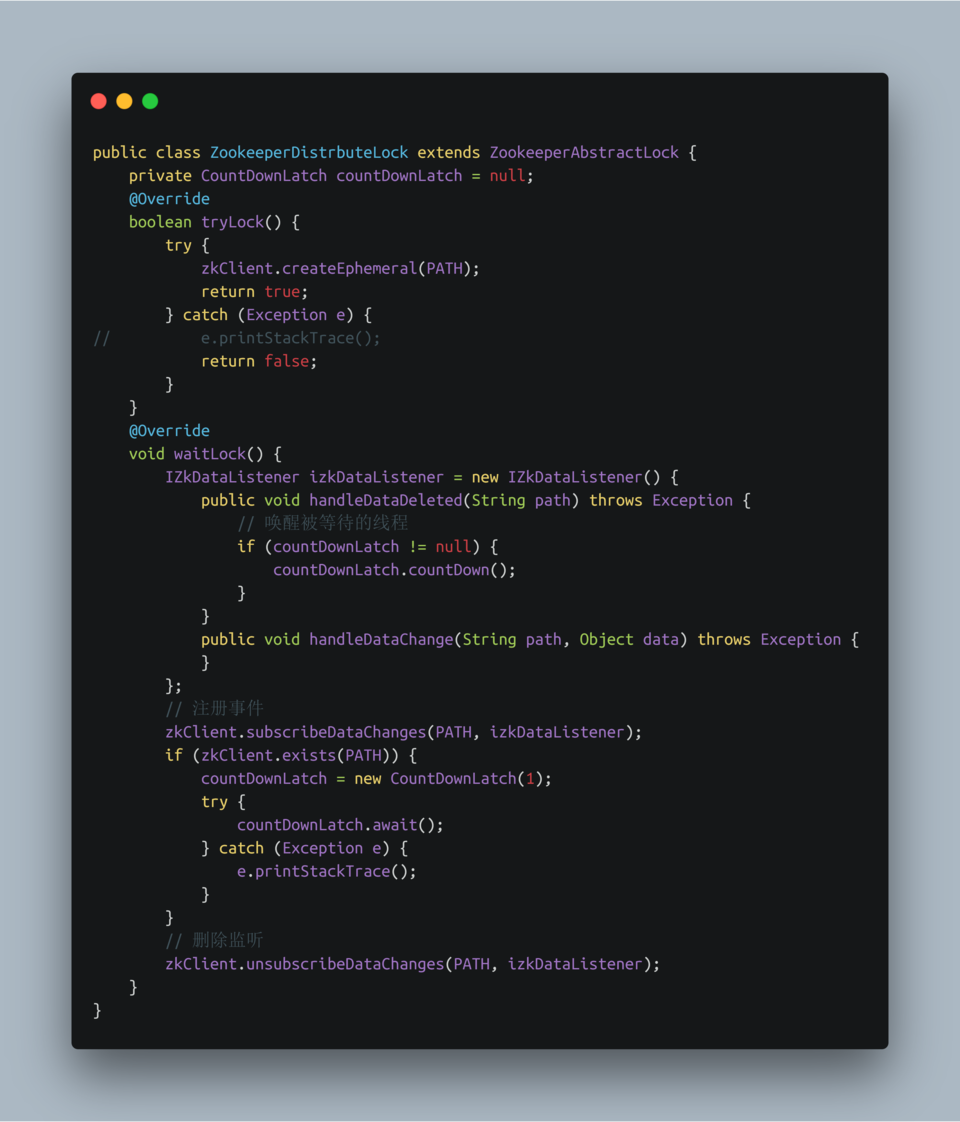
- 使用Zookeeper锁运行效果
3.5 Zookeeper实现Master选举
假设,在多个服务器启动的时候,会在zookeeper上创建相同的临时节点,谁能够创建成功,谁就为主服务器,如果主服务器宕机后,绘画连接也会失效,其他服务器开始重新选举
master选举使用场景及结构 现在很多时候我们的服务需要7*24小时工作,假如一台机器挂了,我们希望能有其它机器顶替它继续工作。此类问题现在多采用master-salve模式,也就是常说的主从模式,正常情况下主机提供服务,备机负责监听主机状态,当主机异常时,可以自动切换到备机继续提供服务(这里有点儿类似于数据库主库跟备库,备机正常情况下只监听,不工作),这个切换过程中选出下一个主机的过程就是master选举。 对于以上提到的场景,传统的解决方式是采用一个备用节点,这个备用节点定期给当前主节点发送ping包,主节点收到ping包后会向备用节点发送应答ack,当备用节点收到应答,就认为主节点还活着,让它继续提供服务,否则就认为主节点挂掉了,自己将开始行使主节点职责。