1. 接口框架
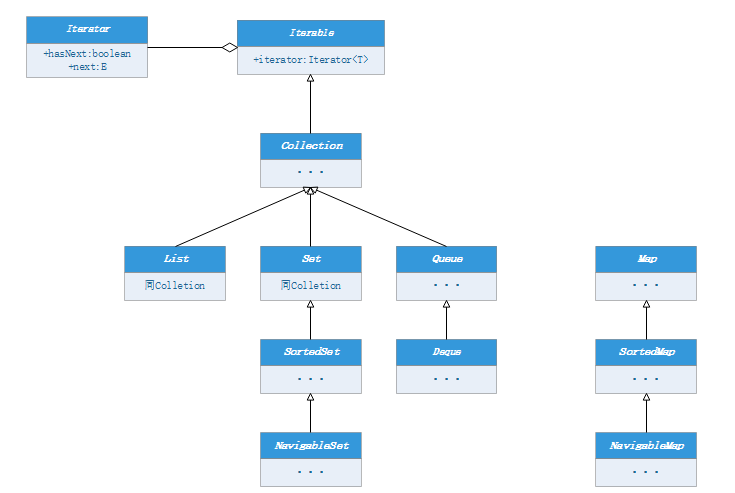
1.1 Iterable
/**
* 实现该接口说明其对象可以使用 for-each 循环遍历
*/
public interface Iterable<T> {
//返回一个T类型的迭代器
Iterator<T> iterator();
···
}
1.2 Iterator
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
···
}
1.3 Collection
public interface Collection<E> extends Iterable<E> {
int size();
boolean isEmpty();
boolean contains(Object o);
Iterator<E> iterator();
Object[] toArray();
<T> T[] toArray(T[] a);
boolean add(E e);
boolean remove(Object o);
boolean containsAll(Collection<?> c);
boolean addAll(Collection<? extends E> c);
boolean removeAll(Collection<?> c);
boolean retainAll(Collection<?> c);
boolean equals(Object o);
int hashCode();
}
1.4 List
public interface List<E> extends Collection<E> {
//基本与Collection接口定义的方法相同
}
1.5 Set
/**
* 不能存在重复的元素,即不能使任意两个元素满足e1.equals(e2)成立
**/
public interface Set<E> extends Collection<E> {
//基本与Collection接口定义的方法相同
}
1.6 SortedSet
/**
* 元素升序排列的Set
**/
public interface SortedSet<E> extends Set<E> {
Comparator<? super E> comparator(); //比较器
SortedSet<E> subSet(E fromElement, E toElement);
SortedSet<E> headSet(E toElement);
SortedSet<E> tailSet(E fromElement);
E first();
E last();
}
1.7 NavigableSet
public interface NavigableSet<E> extends SortedSet<E> {
···
}
1.8 Queue
public interface Queue<E> extends Collection<E> {
boolean add(E e);
boolean offer(E e); //可以看作add方法的改良版,在一些限制长度的队列中队列满时,如果过再添加,则返回false,而不是add那样直接抛出错误
E remove();
E poll(); //与remove区别在于队列为空时使用不会抛异常,而是返回null值
E element();
E peek(); //用于查看队列头部元素而不推出元素,与element区别在于队列为空时不会抛异常而是返回null
}
1.9 Dueue
/**
* 允许从头部和尾部及逆行 插入、删除
**/
public interface Deque<E> extends Queue<E> {
void addFirst(E e);
void addLast(E e);
boolean offerFirst(E e);
boolean offerLast(E e);
E removeFirst();
E removeLast();
E pollFirst();
E pollLast();
E getFirst();
E getLast();
E peekFirst();
E peekLast();
boolean removeFirstOccurrence(Object o);
boolean removeLastOccurrence(Object o);
···
}
1.10 Map
public interface Map<K,V> {
int size();
boolean isEmpty();
boolean containsKey(Object key);
boolean containsValue(Object value);
V get(Object key);
V put(K key, V value);
V remove(Object key);
void putAll(Map<? extends K, ? extends V> m);
void clear();
Set<K> keySet();
Collection<V> values();
Set<Map.Entry<K, V>> entrySet();
interface Entry<K,V> {
K getKey();
V getValue();
V setValue(V value);
}
}
1.11 SortedMap
public interface SortedMap<K,V> extends Map<K,V> {
Comparator<? super K> comparator();
SortedMap<K,V> subMap(K fromKey, K toKey);
SortedMap<K,V> headMap(K toKey);
SortedMap<K,V> tailMap(K fromKey);
K firstKey();
K lastKey();
···
}
1.12 NavigableMap
public interface NavigableMap<K,V> extends SortedMap<K,V> {
Map.Entry<K,V> lowerEntry(K key);
K lowerKey(K key);
Map.Entry<K,V> floorEntry(K key);
}
2. 类框架
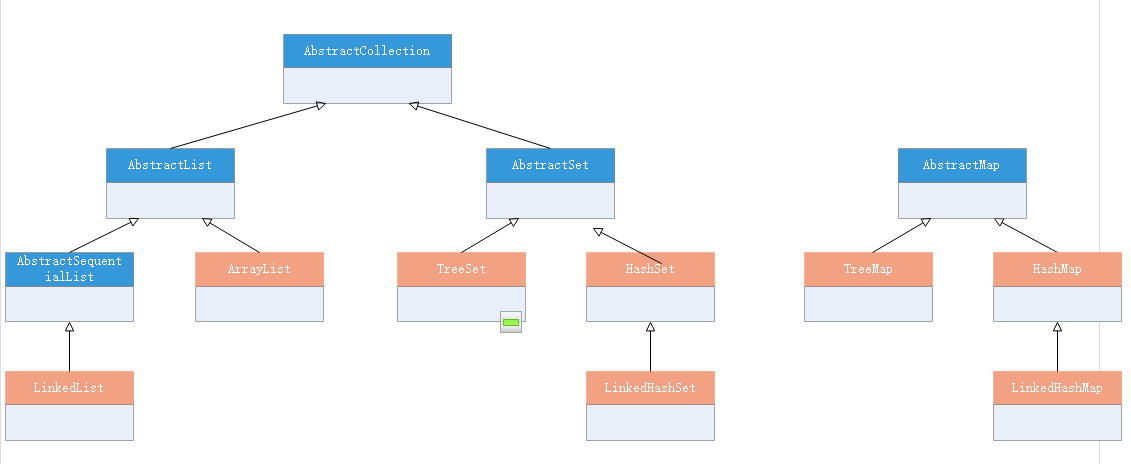
2.1 AbstractCollection
实现了Collection接口的大部分方法:
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8; //集合对象的最大容量
//已实现方法
public boolean isEmpty()
public boolean contains(Object o)
public Object[] toArray()
public <T> T[] toArray(T[] a)
private static <T> T[] finishToArray(T[] r, Iterator<?> it)
private static int hugeCapacity(int minCapacity)
private static int hugeCapacity(int minCapacity)
public boolean containsAll(Collection<?> c)
public boolean addAll(Collection<? extends E> c)
public boolean removeAll(Collection<?> c)
public boolean retainAll(Collection<?> c)
public void clear()
2.2 AbstractList
AbstractList也是一个抽象类,继承于AbstractCollection并且实现了List接口:
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
···
}
2.3 ArrayList
ArrayList继承于AbstractList,并实现了多个接口
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
···
}
2.4 AbstractSequentialList、LinkedList
public abstract class AbstractSequentialList<E> extends AbstractList<E> {
}
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
···
}
2.5 AbstractSet
继承于AbstractCollection的抽象类
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {
···
}
2.6 TreeSet
继承于AbstractSet的实现类。
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
···
}
2.7 HashSet、LinkedHashSet
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
···
}
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable {
···
}
2.8 AbstractQueue
继承于AbstractCollection的抽象类
public abstract class AbstractQueue<E>
extends AbstractCollection<E>
implements Queue<E> {
···
}
2.9 AbstractMap
继承于AbstractCollection的抽象类,表示键值对集合
public abstract class AbstractMap<K,V> implements Map<K,V> {
···
}
2.10 HashMap、LinkedHashMap
2.11 TreeMap
3 简析常用的集合类
3.1 List
3.1.1 ArrayList
特点:底层数据结构为数组,所以是有序的、可重复的、按索引访问元素快、增删慢、线程不安全
首先我们需要了解ArrayList处于Java集合框架的哪个位置:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
其次,我们可以从她的属性中得知ArrayList的底层是通过数组实现的:
private static final int DEFAULT_CAPACITY = 10; // 数组默认容量
transient Object[] elementData; // 数组对象
private int size; // ArrayList的大小
然后,通过ArrayList的构造函数是怎么利用数组来工作的:
/**
* 根据设置的容量初始化ArrayList
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
//初始化数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
//如果initialCapacity==0,则初始化数组为一个空数组
this.elementData = EMPTY_ELEMENTDATA; //EMPTY_ELEMENTDATA是一个空数组
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* 由集合对象创建ArrayList
*/
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// replace with empty array.
this.elementData = EMPTY_ELEMENTDATA;
}
}
因为底层是由数组构成的,而数组的容量是不可变的,所以在扩容操作上要比链表更加复杂:
public void ensureCapacity(int minCapacity) {
//检查数组是不是DEFAULTCAPACITY_EMPTY_ELEMENTDATA?如果是,则minExpand=10,否则为0
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
? 0: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity); //根据数组实际大小确定一下是否需要扩容
}
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 首先要求设置的最小容量要大于数组的长度,才能进行扩容操作
if (minCapacity - elementData.length > 0)
grow(minCapacity); //扩容操作
}
/**
* 真正的扩容操作
*/
private void grow(int minCapacity) {
// 计算出新数组的容量应该是多少
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //1.5倍
//新数组容量取newCapacity、minCapacity中的较大者
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//新数组容量的上限限制
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 拷贝数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
设下的就是ArrayList的增添删改操作,都是针对数组的操作,这里暂时不做展开了。
3.1.2 LinkedList
特点:底层数据结构为双向链表,所以也是排列有序、可重复,按索引访问较慢,但是增删快,线程不安全
首先,LinkedList继承于AbstractSequentialList,我们可以得知LinkedList底层原理与链表有关,而不同于ArrayList的数组:
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
再看一下LinkedList的属性:
transient int size = 0;
transient Node<E> first; //Pointer to first node.
transient Node<E> last; //Pointer to last node
与ArrayList类似,LinkedList也有两种构造方式:
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
接下来,我们看一下组成链表的节点类(内部类):
private static class Node<E> {
E item; //值
Node<E> next; //前向指针
Node<E> prev; //后向指针
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
由此我们可以知道LinkedList内部维护了一个双向链表。下面我们看一下针对链表特点的操作:
/**
* 在链表头部插入新节点
*/
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
/**
* 在链表尾部插入新节点
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
/**
* 在节点succ前插入一个新节点
*/
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev; //succ的前驱节点
final Node<E> newNode = new Node<>(pred, e, succ); //新节点
succ.prev = newNode;
//判断是不是第一个节点
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
下面通过LinkedList的remove方法和clear方法看一下链表的遍历:
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
/**
* 清空整个list
*/
public void clear() {
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null; //help gc
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
我们知道链表善于插入、删除一个节点,但是不善于按索引访问,在Java中也用一些手段尽可能的优化通过索引访问元素的算法,其实也非常简单:在循环遍历之前首先判断期望的索引值距离链表头部更近还是距离尾部更近。
Node<E> node(int index) {
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
3.1.3 Vector
Vector与ArrayList的实现非常相似,底层都是通过数组实现,只是Vector是线程安全的,Vector通过在增删查改等方法上加入同步(synchronized)保证线程安全的同时也放弃了部分效率。
3.2 Set
3.2.1 HashSet
特点:底层数据结构为HashMap,排列无序、不可重复、存取速度快
HashSet继承于AbstractSet:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
由其属性可知内部使用HashMap保存数据:
private transient HashMap<E,Object> map; //底层数据结构
private static final Object PRESENT = new Object(); //仿制值,作为Set存储时HashMap的默认的val值
然后我们看一下HashSet的几种构造器:
public HashSet() {
map = new HashMap<>();
}
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
上面列举了部分构造器,可见HashSet就是根据传入的参数去初始化一个对应的HashMap作为底层存储的数据结构,而后面的增删查改都是围绕HashMap展开的:
public boolean add(E e) {
return map.put(e, PRESENT)==null; //默认空对象作为Map的默认val值
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
其他方法与上诉方法类似,都是利用HashMap进行操作,这里不再赘述。
3.2.2 TreeSet
与HashSet的构成类似,TreeSet底层数据结构为TreeMap,内部实现了NavigableSet接口,而NavigableSet接口是SortedSet接口的扩展,所以我们可以得知TreeSet是有序的、不可重复的:
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
属性为:
private transient NavigableMap<E,Object> m;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
构造函数:
public TreeSet() {
this(new TreeMap<E,Object>());
}
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
/**
* 传入自定义的比较器作为元素排序的依据
*/
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
...
3.2.3 LinkedHashSet
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
有类信息可知LinkedHashSet是HashSet的扩展,下面看一下构造函数:
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
//父类HashSet的构造函数
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor); //LinkedHashSet的底层数据结构是LinkedHashMap
}
所以,我们可以得知LinkedHashSet的底层数据结构是LinkedHashMap,双向链表记录插入顺序。
3.3 Map
3.3.1 Hashtable
关于Hashtable我们至少需要知道以下几点:
1.Hashtable的key和value都不允许为null,而HashMap的key和value都允许为null;
2.Hashtable中的方法几乎都是同步(synchronized)的,相比于HashMap来说性能较低,在要求线程安全的情形下更加推荐使用ConcurrentHashMap;
3.Hashtable的底层是一个数组:Entry<?,?>[] table,通过Entry的链表结构以"拉链法"构建散列表。
类定义:
public class Hashtable<K,V>
extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable
属性:
private transient Entry<?,?>[] table; //底层维护的散列表
private transient int count;
private int threshold; //扩容阈值,capacity * loadFactor
private float loadFactor; //负载因子
private transient int modCount = 0;
部分构造函数:
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
3.3.2 TreeMap
类定义:
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
由类定义中可看继承于AbstractMap,并且实现了NavigableMap等接口,说明TreeMap是一个键值对类型,并且支持一些”导航”操作、可复制、可序列化。
下面看一下TreeMap的属性:
private final Comparator<? super K> comparator; //比较器
private transient Entry<K,V> root; //红黑树的根节点
private transient int size = 0; //Map大小
private transient int modCount = 0; //修改的次数
部分构造器:
/**
* 默认构造器,构建一个新的、空的TreeMap,并且使用默认的比较器
*/
public TreeMap() {
comparator = null;
}
/**
* 设置比较器
*/
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
/**
* 由Map构建一个新的TreeMap
*/
public TreeMap(Map<? extends K, ? extends V> m) {
comparator = null;
putAll(m);
}
/**
* 由SortedMap构建一个新的TreeMap
*/
public TreeMap(SortedMap<K, ? extends V> m) {
comparator = m.comparator();
try {
buildFromSorted(m.size(), m.entrySet().iterator(), null, null);
} catch (java.io.IOException cannotHappen) {
} catch (ClassNotFoundException cannotHappen) {
}
}
由于TreeMap内部是有红黑树维护的,所以关于TreeMap的增删方法需要重视:
/**
* 1.如果是空树,则直接创建新节点并使之成为二叉树的根节点
* 2.获取比较器,如果设置了特殊比较器,通过特殊比较器利用红黑树的二分特性查找应该插入成为其子节点的父节点;如果时自然比较器,则使用key的默认比较器进行查找
* 3.创建新节点,插入到刚刚找到的父节点的下面
* 4.重新调整使之满足红黑树的特点
*/
public V put(K key, V value) {
Entry<K,V> t = root; //Dummy root
//如果是空树,之间新建一个root节点
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent; //指向新节点的父节点
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
//如果比较器不是自然比较器
if (cpr != null) {
//遍历红黑树,根据红黑树的二分特点找到新节点应在的位置
do {
parent = t;
cmp = cpr.compare(key, t.key); //使用设定的比较器进行比较
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value); //直接覆盖值
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key); //没有设置特殊的比较器,使用key的默认比较器进行比较
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//创建新节点
Entry<K,V> e = new Entry<>(key, value, parent);
//将新节点插入父节点的下面
if (cmp < 0)
parent.left = e;
else
parent.right = e;
//重新整理红黑树
fixAfterInsertion(e);
//Map大小增加、修改次数增加
size++;
modCount++;
return null;
}
这几涉及到了红黑树,所以我们先熟悉下红黑树的特性:
1. 一个节点要么是红色的,要么是黑色的;
2. 根节点是黑色的;
3. 如果一个节点是红色的,那么她的两个孩子节点一定都是黑色的;
4. 对于路径上的任意一个节点,她到叶子节点的每条路径上的黑色节点的个数是相同的。
每次插入一个新节点时,都设置这个新节点为红色,这是为了满足第4条特性,即新插入的节点不会影响路径上黑色节点的个数。但是这个红色的新节点有时就会不满足条件3:如果新插入的节点的父亲节点也是红色。所以,我们在每次插入新节点之后,都需要去判断是否要调整二叉树使之重新成为一棵红黑树,在刚刚的put()方法中,插入新节点后就调用了fixAfterInsertion()方法进行重新调整:
private void fixAfterInsertion(Entry<K,V> x) {
x.color = RED; //将当前节点设置为红色
while (x != null && x != root && x.parent.color == RED) {
//如果当前节点的父亲节点是其父亲节点的:左孩子
if (parentOf(x) == leftOf(parentOf(parentOf(x)))) {
Entry<K,V> y = rightOf(parentOf(parentOf(x))); //当前节点的叔叔节点(右孩子)
//如果叔叔(右孩子)节点是红色的
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
//如果叔叔(右孩子)节点是黑色的
//并且当前节点是父亲节点的右孩子
if (x == rightOf(parentOf(x))) {
//以父亲节点作为当前节点
x = parentOf(x);
//左旋转
rotateLeft(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
//以x的祖父节点进行右旋转
rotateRight(parentOf(parentOf(x)));
}
} else {
//如果当前节点的父亲节点是其父亲节点的右节点
Entry<K,V> y = leftOf(parentOf(parentOf(x))); //y为x节点的左、叔叔节点
//如果左、叔叔节点是红色的
if (colorOf(y) == RED) {
setColor(parentOf(x), BLACK);
setColor(y, BLACK);
setColor(parentOf(parentOf(x)), RED);
x = parentOf(parentOf(x));
} else {
//如果左、叔叔节点是黑色的
//如果当前节点是父亲节点的左孩子
if (x == leftOf(parentOf(x))) {
//以x的父亲节点作为当前节点
x = parentOf(x);
//进行右旋转
rotateRight(x);
}
setColor(parentOf(x), BLACK);
setColor(parentOf(parentOf(x)), RED);
rotateLeft(parentOf(parentOf(x)));
}
}
}
root.color = BLACK;
}
下面结合代码分析下调整的过程:
- 情形一:
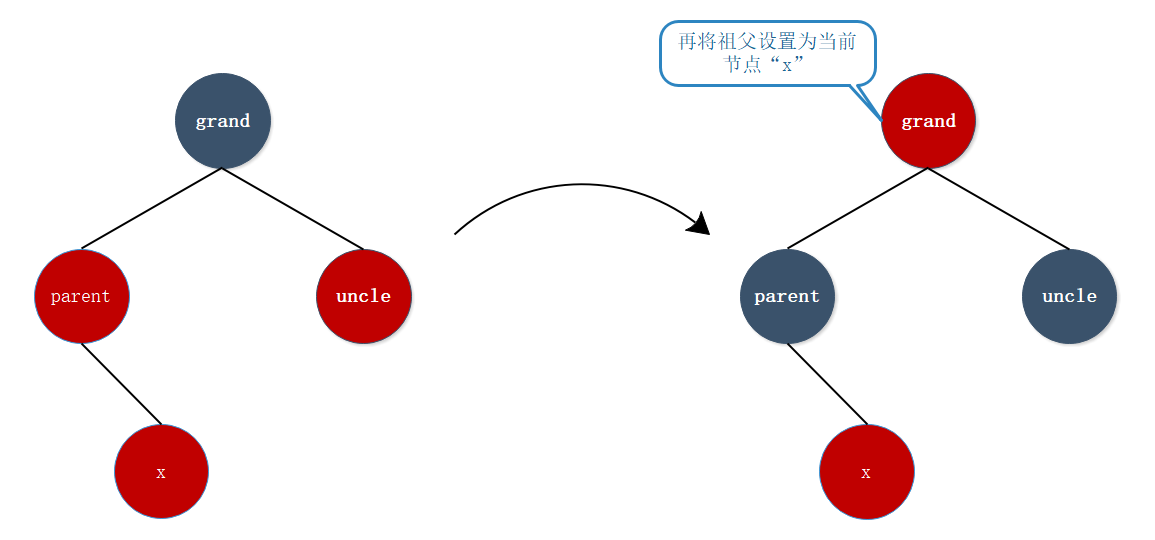 如果当前节点x的父亲节点与叔叔节点都是红色时,则将当前节点的父亲、叔叔节点改为黑色,祖父节点改为红色。但是这样的话祖父节点可能会违反红黑树规则,则将祖父节点设为下次循环的“当前节点”。
如果当前节点x的父亲节点与叔叔节点都是红色时,则将当前节点的父亲、叔叔节点改为黑色,祖父节点改为红色。但是这样的话祖父节点可能会违反红黑树规则,则将祖父节点设为下次循环的“当前节点”。
- 情形二:
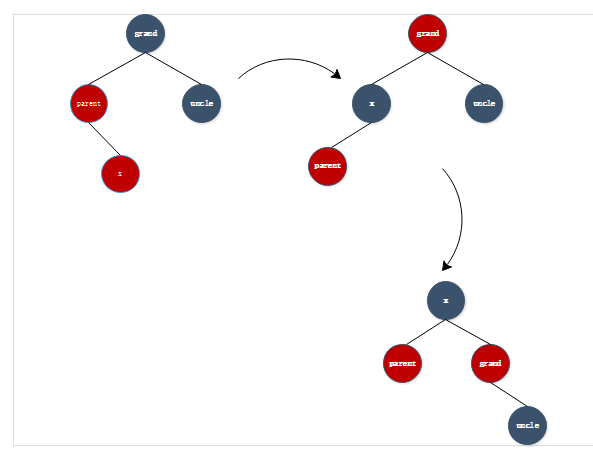 在情形二中,首先以父亲节点为支点进行左旋转,然后该改变原当前节点x和叔叔节点的颜色为黑色,祖父节点改为红色,然后以祖父节点为支点进行右旋转。
在情形二中,首先以父亲节点为支点进行左旋转,然后该改变原当前节点x和叔叔节点的颜色为黑色,祖父节点改为红色,然后以祖父节点为支点进行右旋转。
- 情形三:
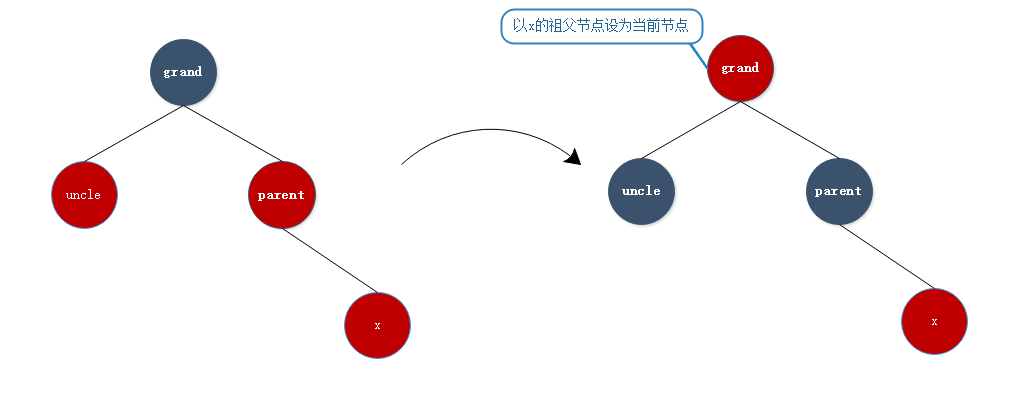 在情形三中,与情形一类似,直接改变父亲、叔叔、祖父节点的颜色,再将祖父节点作为当前节点进入下次循环。
在情形三中,与情形一类似,直接改变父亲、叔叔、祖父节点的颜色,再将祖父节点作为当前节点进入下次循环。
- 情形四:
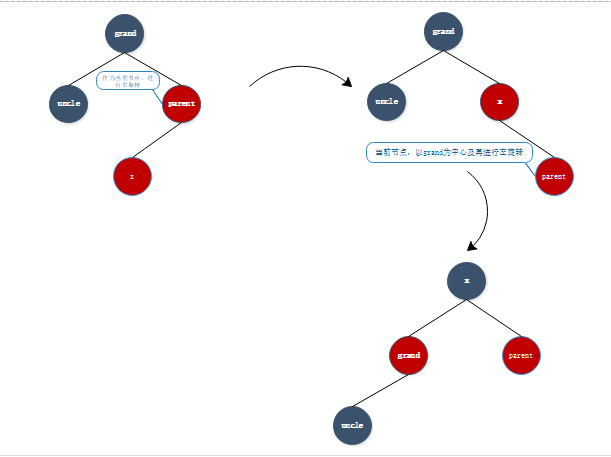 这种情况与情形二类似,需要首先以当前节点的父亲节点为支点进行右旋转,然后改变x和祖父节点的颜色,再以祖父节点为支点进行左旋转。
这种情况与情形二类似,需要首先以当前节点的父亲节点为支点进行右旋转,然后改变x和祖父节点的颜色,再以祖父节点为支点进行左旋转。
综上所述,TreeMap中大概分为了4中情形,我们可以再抽象为二种:
1.如果当前节点(新插入的节点)的父亲、叔叔节点都是红色的,则直接将父亲、叔叔、祖父的颜色反转,然后再以祖父为当前节点进入下次循环继续进行调整;
2.如果当前节点的父亲节点和叔叔节点颜色不同,且父亲节点为红色,则需要将当前节点和祖父节点的颜色反转,再以祖父节点为支点进行旋转,使当前节点作为子树的根节点。
未完待续。。