这几天刚刚开始学习Python,就像写个爬虫小项目练练手,自从间书的“××豚”事件后搬到掘金,感觉掘金在各个方面做的都很不错,尤其是文章的质量和写文章的编辑器做的很舒服。
但是,我每次想要搜索一个自己感兴趣的关键字时,下面就会出现大量文章,想按照“点赞数”排序连按钮也找不到,必须得一直向下一行行浏览才能找到我们需要的文章。所以,我在想能否利用刚学习的爬虫做个功能:只需输入关键字和通过被点赞数,就能自动给出一个列表,它包含了符合(点赞数大于我们设定的)我们需求的文章。说干就开始,首先上结果图:
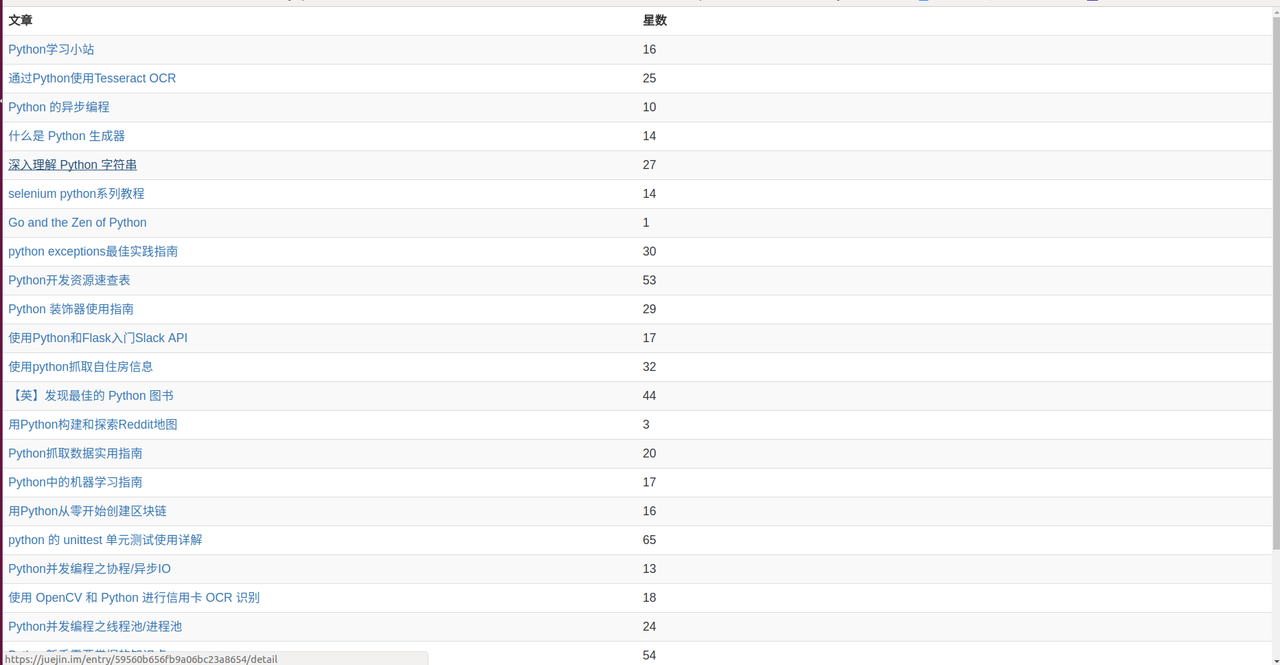
下面开始正式的工作:
1.项目构成
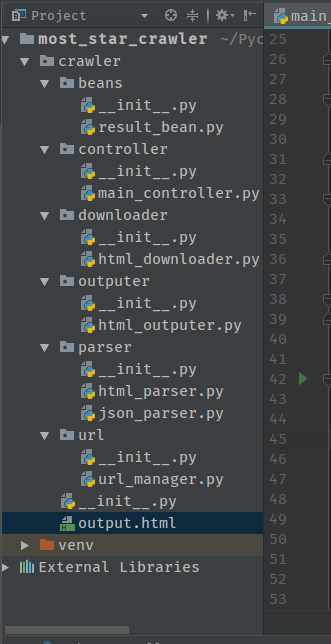 程序主要分为:controller(主控制器)、downloader(下载器)、parser(解析器)、url_manager(url管理器)、outputer(输出器)。
程序主要分为:controller(主控制器)、downloader(下载器)、parser(解析器)、url_manager(url管理器)、outputer(输出器)。
2. URL管理器(url_manager)
URL管理器主要负责产生、维护需要爬取的网站链接,对于我们要爬取的网站“掘金”,主要分为两类:静态页面URL,AJAX动态构建的页面。
这两种请求的URL的构成截然不同,并且返回内容也不同:静态页面URL返回HTML页面,AJAX请求返回的是JSON字符串。针对这两种访问方式,我们可以这样编写URL管理器:
class UrlManager(object):
def __init__(self):
self.new_urls = set() # 新的url的集合
# 构建访问静态页面的url
def build_static_url(self, base_url, keyword):
static_url = base_url + '?query=' + keyword
return static_url
# 根据输入的base_url(基础地址)和params(参数字典)来构造一个新的url
# eg:https://search-merger-ms.juejin.im/v1/search?query=python&page=1&raw_result=false&src=web
# 参数中的start_page是访问的起始页数字,gap是访问的页数间隔
def build_ajax_url(self, base_url, params, start_page=0, end_page=4, gap=1):
if base_url is None:
print('Invalid param base_url!')
return None
if params is None or len(params)==0:
print('Invalid param request_params!')
return None
if end_page < start_page:
raise Exception('start_page is bigger than end_page!')
equal_sign = '=' #键值对内部连接符
and_sign = '&' #键值对之间连接符
# 将base_url和参数拼接成url放入集合中
for page_num in range(start_page, end_page, gap):
param_list = []
params['page'] = str(page_num)
for item in params.items():
param_list.append(equal_sign.join(item)) # 字典中每个键值对中间用'='连接
param_str = and_sign.join(param_list) # 不同键值对之间用'&'连接
new_url = base_url + '?' + param_str
self.new_urls.add(new_url)
return None
# 从url集合中获取一个新的url
def get_new_url(self):
if self.new_urls is None or len(self.new_urls) == 0:
print('there are no new_url!')
return None
return self.new_urls.pop()
# 判断集合中是否还有url
def has_more_url(self):
if self.new_urls is None or len(self.new_urls) == 0:
return False
else:
return True
如上代码,在初始化函数__init__中维护了一个集合,创建好的URL将会放入到这个集合中。然后根据网址的结构分为基础的网址+访问参数,两者之间通过’?’链接,参数之间通过’&’链接。通过函数build_ajax_url将两者连接起来,构成完整的URL放入到集合中,可以通过get_new_url获取集合中的一条URL,has_more_url判断集合中是否还有未消费的URL。
2.下载器(html_downloader)
import urllib.request
class HtmlDownloader(object):
def download(self, url):
if url is None:
print('one invalid url is found!')
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200:
print('response from %s is invalid!' % url)
return None
return response.read().decode('utf-8')
这段代码比较简单,使用urllib库访问URL并返回得到的返回数据。
3.JSON解析器(json_parser)
import json
from crawler.beans import result_bean
class JsonParser(object):
# 将json字符创解析为一个对象
def json_to_object(self, json_content):
if json_content is None:
print('parse error!json is None!')
return None
print('json', str(json_content))
return json.loads(str(json_content))
# 从JSON构成的对象中提取出文章的title、link、collectionCount等数据,并将其封装成一个Bean对象,最后将这些对象添加到结果列表中
def build_bean_from_json(self, json_collection, baseline):
if json_collection is None:
print('build bean from json error! json_collection is None!')
list = json_collection['d'] # 文章的列表
result_list = [] # 结果的列表
for element in list:
starCount = element['collectionCount'] # 获得的收藏数,即获得的赞数
if int(starCount) > baseline: # 如果收藏数超过baseline,则勾结结果对象并添加到结果列表中
title = element['title']
link = element['originalUrl']
result = result_bean.ResultBean(title, link, starCount)
result_list.append(result) # 添加到结果列表中
print(title, link, starCount)
return result_list
对于JSON的解析主要分为两部:1.将JSON字符串转换为一个字典对象;2.将文章题目、链接、赞数等信息从字典对象中提取出来,根据baseline判断是否将这些数据封装成结果对象并添加到结果列表中。
3.HTML解析器(html_parser)
我们可以通过访问:’https://juejin.im/search?query=python’得到一个HTML网页,但是只有一页数据,相当于访问’https://search-merger-ms.juejin.im/v1/search?query=python&page=0&raw_result=false&src=web’获得的数据量,但是区别是一个返回内容的格式是HTML,第二个返回的是JSON。这里我们也将HTML的解析器也放到这里,项目中可以不用到这个:
from bs4 import BeautifulSoup
from crawler.beans import result_bean
class HtmlParser(object):
# 创建BeautifulSoup对象,将html结构化
def build_soup(self, html_content):
self.soup = BeautifulSoup(html_content, 'html.parser')
return self.soup
# 根据获得的赞数过滤得到符合条件的tag
def get_dom_by_star(self, baseline):
doms = self.soup.find_all('span', class_='count')
# 根据最少赞数过滤结果,只保留不小于baseline的节点
for dom in doms:
if int(dom.get_text()) < baseline:
doms.remove(dom)
return doms
# 根据节点构建结果对象并添加到列表中
def build_bean_from_html(self, baseline):
doms = self.get_dom_by_star(baseline)
if doms is None or len(doms)==0:
print('doms is empty!')
return None
results = []
for dom in doms:
starCount = dom.get_text() # 获得的赞数
root = dom.find_parent('div', class_='info-box') #这篇文章的节点
a = root.find('a', class_='title', target='_blank') #包含了文章题目和链接的tag
link = 'https://juejin.im' + a['href'] + '/detail' #构造link
title = a.get_text()
results.append(result_bean.ResultBean(title, link, starCount))
print(link, title, starCount)
return results
为了更加高效地解析HTML文件,这里需要用到’bs4’模块。
4.结果对象(result_bean)
结果对象是对爬虫结果的一个封装,将文章名、对应的链接、获得的赞数封装成一个对象:
# 将每条文章保存为一个bean,其中包含:题目、链接、获得的赞数 属性
class ResultBean(object):
def __init__(self, title, link, starCount=10):
self.title = title
self.link = link
self.starCount = starCount
5.HTML输出器(html_outputer)
class HtmlOutputer(object):
def __init__(self):
self.datas = [] # 輸入結果列表
# 構建輸入數據(結果列表)
def build_data(self, datas):
if datas is None:
print('Invalid data for output!')
return None
# 判断是应该追加还是覆盖
if self.datas is None or len(self.datas)==0:
self.datas = datas
else:
self.datas.extend(datas)
# 输出html文件
def output(self):
fout = open('output.html', 'w', encoding='utf-8')
fout.write('<html>')
fout.write("<head><meta http-equiv=\"content-type\" content=\"text/html;charset=utf-8\">")
fout.write("<link rel=\"stylesheet\" href=\"http://cdn.static.runoob.com/libs/bootstrap/3.3.7/css/bootstrap.min.css\"> ")
fout.write("<script src=\"http://cdn.static.runoob.com/libs/bootstrap/3.3.7/js/bootstrap.min.js\"></script>")
fout.write("</head>")
fout.write("<body>")
fout.write("<table class=\"table table-striped\" width=\"200\">")
fout.write("<thead><tr><td><strong>文章</strong></td><td><strong>星数</strong></td></tr></thead>")
for data in self.datas:
fout.write("<tr>")
fout.write("<td width=\"100\"><a href=\"%s\" target=\"_blank\">%s</a></td>" % (data.link, data.title))
fout.write("<td width=\"100\"> %s</td>" % data.starCount)
fout.write("</tr>")
fout.write("</table>")
fout.write("</body>")
fout.write("</html>")
fout.close()
将解析后得到的结果对象列表中的数据保存在HTML表格中。
6.控制器(main_controller)
from crawler.url import url_manager
from crawler.downloader import html_downloader
from crawler.parser import html_parser, json_parser
from crawler.outputer import html_outputer
class MainController(object):
def __init__(self):
self.url_manager = url_manager.UrlManager()
self.downloader = html_downloader.HtmlDownloader()
self.html_parser = html_parser.HtmlParser()
self.html_outputer = html_outputer.HtmlOutputer()
self.json_paser = json_parser.JsonParser()
def craw(self, func):
def in_craw(baseline):
print('begin to crawler..')
results = []
while self.url_manager.has_more_url():
content = self.downloader.download(self.url_manager.get_new_url()) # 根据URL获取静态网页
results.extend(func(content, baseline))
self.html_outputer.build_data(results)
self.html_outputer.output()
print('crawler end..')
print('call craw..')
return in_craw
def parse_from_json(self, content, baseline):
json_collection = self.json_paser.json_to_object(content)
results = self.json_paser.build_bean_from_json(json_collection, baseline)
return results
def parse_from_html(self, content, baseline):
self.html_parser.build_soup(content) # 使用BeautifulSoup将html网页构建成soup树
results = self.html_parser.build_bean_from_html(baseline)
return results
在控制器中,通过__init__函数创建前面的几个模块的实例。函数parse_from_json和parse_from_html分别负责从JSON和HTML中解析出结果;函数craw中利用闭包将解析函数抽象出来,使我们方便选择需要的解析器,就将解析器作为参数’func’传入craw函数中,这点类似于Java中对接口的使用,但是更加灵活,主函数中具体的用法可以是:
if __name__ == '__main__':
base_url = 'https://juejin.im/search' # 要爬取的HTML网站网址(不含参数)
ajax_base_url = 'https://search-merger-ms.juejin.im/v1/search' #要通过ajax访问的网址(不含参数,返回JSON)
keyword = 'python' # 搜索的关键字
baseline = 10 # 获得的最少赞数量
# 创建控制器对象
crawler_controller = MainController()
static_url = crawler_controller.url_manager.build_static_url(base_url, keyword) # 构建静态URL
# craw_html = crawler_controller.craw(crawler_controller.parse_from_html) # 选择HTML解析器
# craw_html(static_url, baseline) #开始抓取
# ajax请求的网址例子:'https://search-merger-ms.juejin.im/v1/search?query=python&page=0&raw_result=false&src=web'
params = {} # 对应的请求参数
# 初始化请求参数
params['query'] = keyword
params['page'] = '1'
params['raw_result'] = 'false'
params['src'] = 'web'
crawler_controller.url_manager.build_ajax_url(ajax_base_url, params) # 构建ajax访问的网址
craw_json = crawler_controller.craw(crawler_controller.parse_from_json) # 选择JSON解析器
craw_json(baseline) #开始抓取