最近在读《Java程序性能优化》这本书,写这篇博客记录一下所学。 ##1. Java虚拟机内存模型 我们知道Java虚拟机的内存是Java程序运行的基础,所以很有必要弄清楚Java内存模型的构造和作用,Java虚拟机内存模型可以分为以下几个部分:
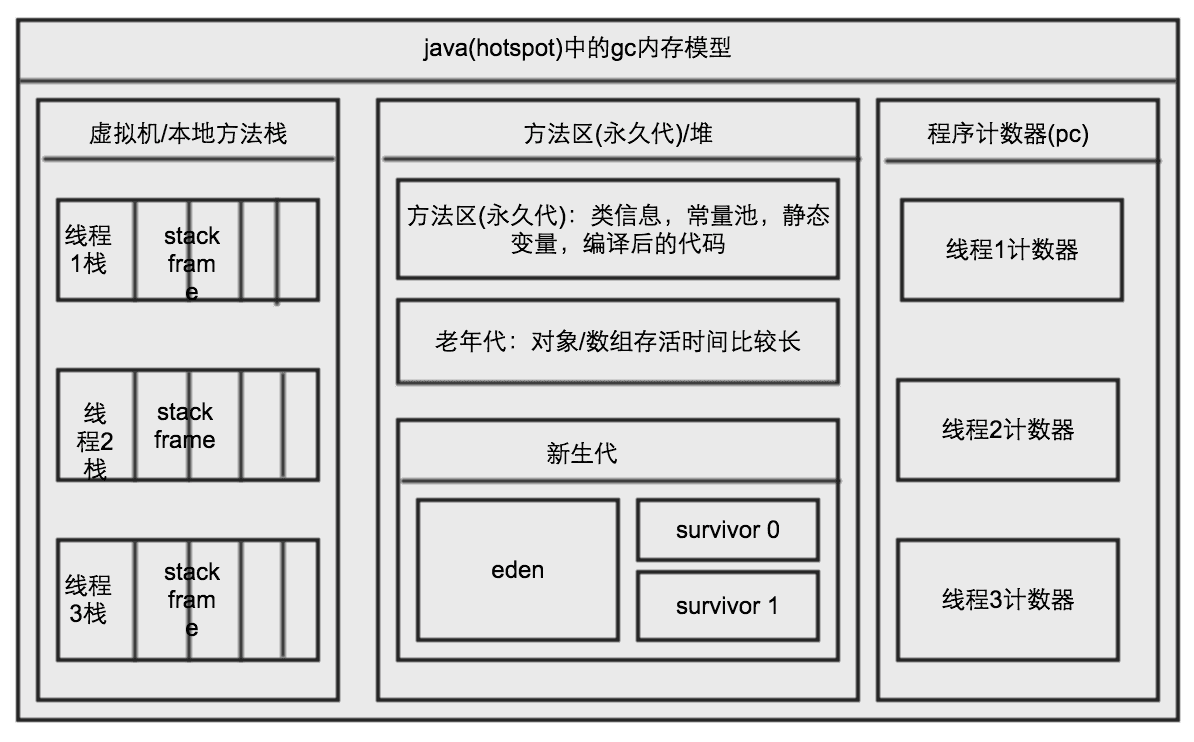
1). 程序计数器:每条线程都有一个独立的计数器,用于记录下一条要运行的程序; 2). Java虚拟机栈:线程私有的内存空间,用于保存方法的局部变量、结果、方法的调用和返回等,虚拟机为线程的每个方法创建一个栈帧,每个栈帧中又包含了局部变量表、操作数栈、返回地址等结构; 3). 本地方法栈:与Java虚拟机栈类似,不同之处在于本地方法栈保存的是C语言实现的本地方法; 4). Java堆:与程序计数器、Java虚拟机栈不同,Java堆是所有线程共享的,所有的对象实例和数组都存放于此,是较大的一块内存块且是垃圾回收的主要对象; 5). 方法区:与Java堆一样也是被所有线程所共有的,方法区内保存的信息大部分来自于class文件,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。也称为“永久区”,说明此区较少有垃圾回收;
下面用一个简单的例子说明:
MyObject myObject = new MyObject(int num,String str);
首先通过“MyObject myObject ”在Java虚拟机栈创建一个栈帧,里面存放了形参num、str,并且保存了myObject作为reference类型数据。而“new MyObject()”在Java堆中创建了一块包含该实例所有信息的结构化内存。reference类型数据myObject直接或间接地指向了Java堆中它所引用的实例。
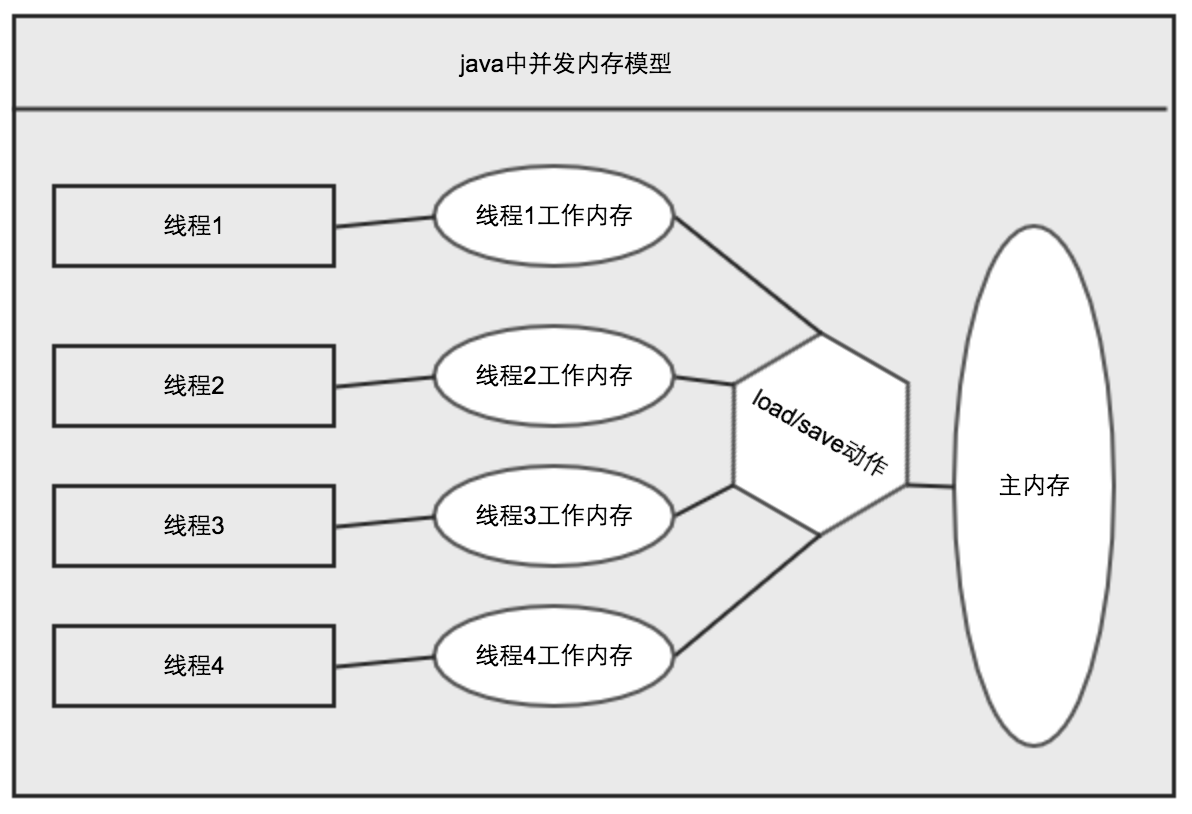 如上图所示,我们知道为了速度匹配CPU通过高速缓存与主内存进行数据传输,通过高速缓存来缓解CPU与主内存之间较大的速度差异。与CPU相类似,Java程序中可以近似认为每个线程就是一个独立工作的CPU,每个线程都有自己的工作内存,不同线程之间的工作内存是独立的,都通过load/save与主内存进行数据传输,每个线程都只能通过自己的工作内存区读取主内存上的数据,也只能通过工作内存区改写主内存。但是不同的线程是无法获取、改变其他线程的工作内存的,所以就出现了内存数据一致性的问题。
如上图所示,我们知道为了速度匹配CPU通过高速缓存与主内存进行数据传输,通过高速缓存来缓解CPU与主内存之间较大的速度差异。与CPU相类似,Java程序中可以近似认为每个线程就是一个独立工作的CPU,每个线程都有自己的工作内存,不同线程之间的工作内存是独立的,都通过load/save与主内存进行数据传输,每个线程都只能通过自己的工作内存区读取主内存上的数据,也只能通过工作内存区改写主内存。但是不同的线程是无法获取、改变其他线程的工作内存的,所以就出现了内存数据一致性的问题。
关于主内存与工作内存之间的交互协议,即一个变量如何从主内存拷贝到工作内存。如何从工作内存同步到主内存中的实现细节。java内存模型定义了8种操作来完成。这8种操作每一种都是原子操作。8种操作如下:
lock(锁定):作用于主内存,它把一个变量标记为一条线程独占状态; unlock(解锁):作用于主内存,它将一个处于锁定状态的变量释放出来,释放后的变量才能够被其他线程锁定; read(读取):作用于主内存,它把变量值从主内存传送到线程的工作内存中,以便随后的load动作使用; load(载入):作用于工作内存,它把read操作的值放入工作内存中的变量副本中; use(使用):作用于工作内存,它把工作内存中的值传递给执行引擎,每当虚拟机遇到一个需要使用这个变量的指令时候,将会执行这个动作; assign(赋值):作用于工作内存,它把从执行引擎获取的值赋值给工作内存中的变量,每当虚拟机遇到一个给变量赋值的指令时候,执行该操作; store(存储):作用于工作内存,它把工作内存中的一个变量传送给主内存中,以备随后的write操作使用; write(写入):作用于主内存,它把store传送值放到主内存中的变量中。
###2. 垃圾收集器 首先,我们先提出三个问题:
1). 哪些对象需要回收? 2). 什么时候回收这些对象? 3). 如何回收?
针对不同的情况,JVM会为我们的程序选择对应特点的垃圾收集器,为了针对我们的程序和运行环境使其达到最优化,我们需要了解不同垃圾收集器之间的区别、特点和原理。下面简单介绍几个重要的垃圾处理算法: ###(1)引用计数法 对于一个对象A,只要有任何一个对象引用了它,则A的引用计数器就加一,若一个引用失效,则计数器减一,当A的计数器为0时即表示对象A应该被回收。
但是引用计数器法有一个很严重的问题,就是不能回收相互引用的对象,因为两个相互引用的对象相互持有对方的引用,引用计数器始终不为0。
(2)标记-清除算法
标记-清除算法包括了两个阶段:标记、清除。首先在标记阶段,通过根节点开始标记可达对象,未被标记的对象就是未被引用的垃圾对象。然后在清除阶段将未被标记的对象清除。
但是标记清除算法而有一个缺点:回收后的空间是不连续的,而在大对象的内存分配中,不连续的内存会影响分配的效率。
(3) 复制算法
将内存空间分为两部分,每次只使用其中一块,在垃圾回收时,将正在使用的内存块中的存活对象复制到另一块空间中,然后再将使用中的内存块中的所有对象清空,完成垃圾回收。
从复制算法的原理来看,比较适合有较多垃圾对象的情景,因为此时需要复制的对象比较少,复制过程的效率比较高,并且可以确保复制后的内存是连续的。
但是复制算法也有自己的缺点,它将内存分为两部分,降低了内存的利用率。
为了增加内存的利用率,在Java的新生代串行垃圾回收器中,将内存块分为三个部分,一个eden,两个survivor,其中eden表示创建新对象的地方,大部分最新创建的对象都会被放入eden中,而survivor表示对象至少经历过一次垃圾回收后仍然存活下来,将被移入survivor中,其中survivor又分为大小相同的两部分:from、to。
在改进的复制算法中,垃圾回收时eden空间中的新的、存活的对象会被复制到survivor中一个未被使用的空间(假设为to),survivor中正在使用的from空间中的年轻的、存活的对象也会被复制到to中,大对象或者老年对象会直接移入老年代,然后清除eden和from空间。
所以我们说复制算法是建立在存活对象少、垃圾对象多的前提下,比较适用于新生代。
(4) 标记-压缩算法
标记-压缩算法是一种适用于老年代的回收算法,它在标记-清除算法的基础上做了一些优化,与标记-清除算法一样,它首先从根节点进行标记,然后将所有存活的对象压向内存块的一端,最后清理边界外的空间。