1. 从输入到输出的总过程
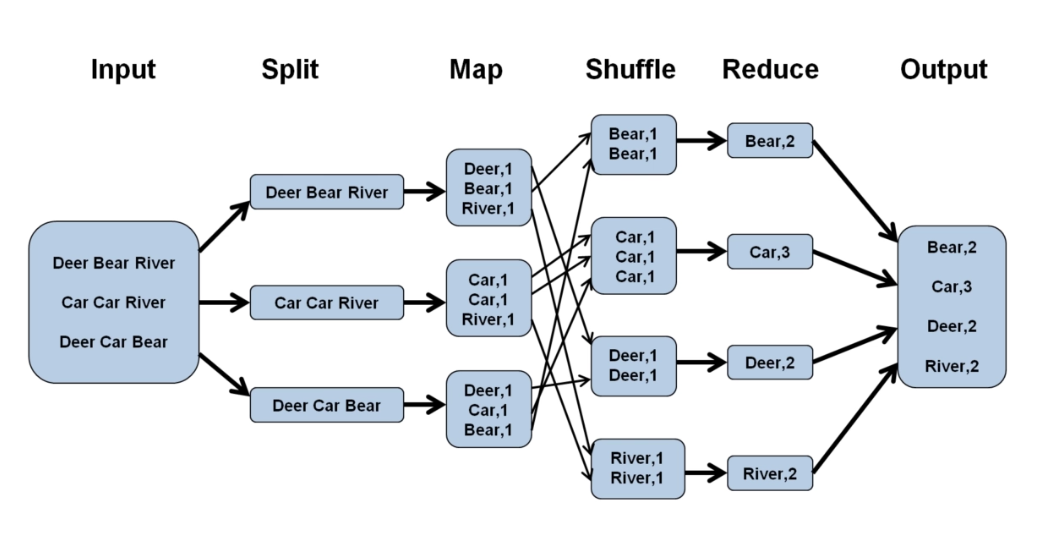
2. 过程分解
(1)split分片–>Map
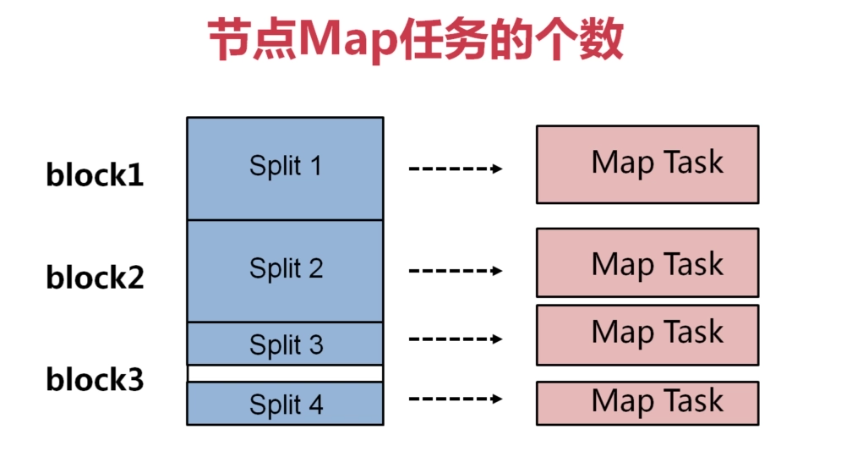 由上图所示,是Hadoop的分片过程,在Hadoop中默认每个“块”是128M,从图中可以看出输入了两个文件,第一个文件比较大,占用了2+个块,第二个文件比较小(<128M);所以,第一个文件被分为3个分片:split1~3,第二个文件单独被分为一个分片split4。 一般来说一个分片split对应一个Map任务,所以Map任务数也为4个。但是Map任务数量其实并不是这么简单,她与很多因素有关,一般最好将一个datanode中的Map任务数控制在10~100之间。 由此可以看出,Hadoop的Hdfs文件系统更加适合处理大文件,不适合处理有大量小文件的情况,这时最好将小数据进行压缩、合并等操作。 ####(2)Map–>Shufflr–>Reduce 如果分得更细一些,这其中的过程可以表示为:
由上图所示,是Hadoop的分片过程,在Hadoop中默认每个“块”是128M,从图中可以看出输入了两个文件,第一个文件比较大,占用了2+个块,第二个文件比较小(<128M);所以,第一个文件被分为3个分片:split1~3,第二个文件单独被分为一个分片split4。 一般来说一个分片split对应一个Map任务,所以Map任务数也为4个。但是Map任务数量其实并不是这么简单,她与很多因素有关,一般最好将一个datanode中的Map任务数控制在10~100之间。 由此可以看出,Hadoop的Hdfs文件系统更加适合处理大文件,不适合处理有大量小文件的情况,这时最好将小数据进行压缩、合并等操作。 ####(2)Map–>Shufflr–>Reduce 如果分得更细一些,这其中的过程可以表示为:
Map–>Combine–>网络混洗–>Shuffle–>Reduce
Map输出大量键值对后,需要经过网络混洗,然后经过Shuffle进入Reduce,但是大量的散片键值对会造成巨大的网络压力,所以在进行网络传输之前,要对Map输出的键值对进行一轮排序、合并,再进行网络混洗,这个过程就是Combine。过程示意图如下:
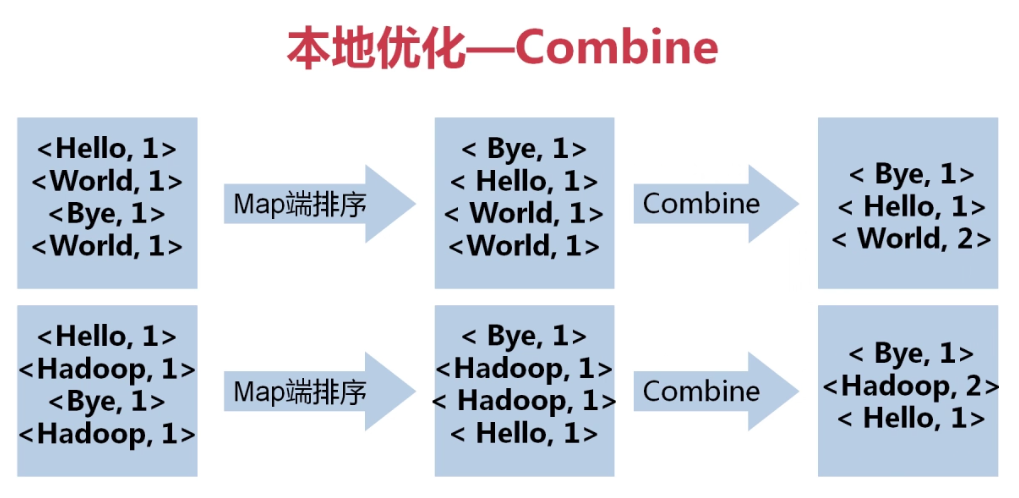
在得到键值对后,分别对每个Map函数输出的键值对进行排序(按字母顺序),然后将键值相同的键值对进行合并。也可以将Combine认为是对Map结果的“本地Reduce操作”。
(3)Map–>Reduce
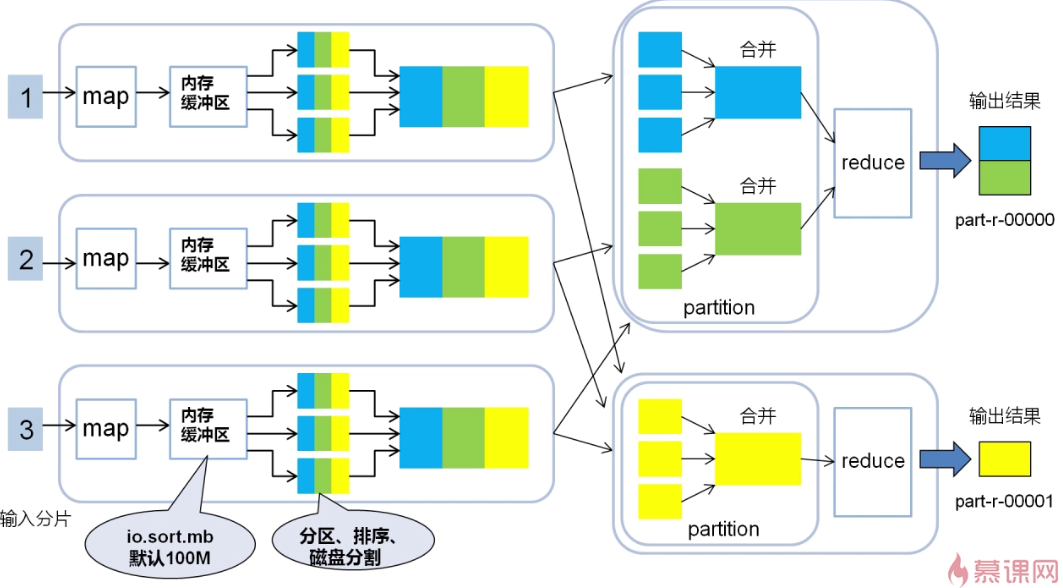 由上图所示,Map输出数据保存到内存缓冲区,多余溢出的数据将会保存到磁盘中,其中不同的颜色代表不同的键值,然后是将每个Map输出的数据以键值为标准合并成大数据; 然后数据进入partition中,将数据按键值合并(不累加,列表形式)输出到相应的Reduce中。 注意:在一个MapReduce中,partition、Reduce任务、输出结果的数量是相同的
由上图所示,Map输出数据保存到内存缓冲区,多余溢出的数据将会保存到磁盘中,其中不同的颜色代表不同的键值,然后是将每个Map输出的数据以键值为标准合并成大数据; 然后数据进入partition中,将数据按键值合并(不累加,列表形式)输出到相应的Reduce中。 注意:在一个MapReduce中,partition、Reduce任务、输出结果的数量是相同的