工作模型
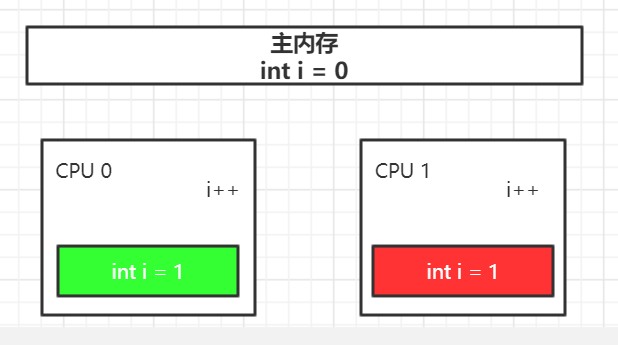
缓存一致性协议 (MESI)
modify :修改状态,表示共享数据只缓存在当前 CPU 并且是修改状态,也就是缓存的数据与主内存中不一致
shared:共享状态,多个 CPU 缓存中的内容与主内存中内容一致
invalid :失效状态,某个CPU 缓存中的内容进行了修改,对将其余 CPU 缓存中的数据设为 Invalid 状态
exclusively:独有状态,只有某个 CPU 缓存有这个数据,并且数据没有进行修改
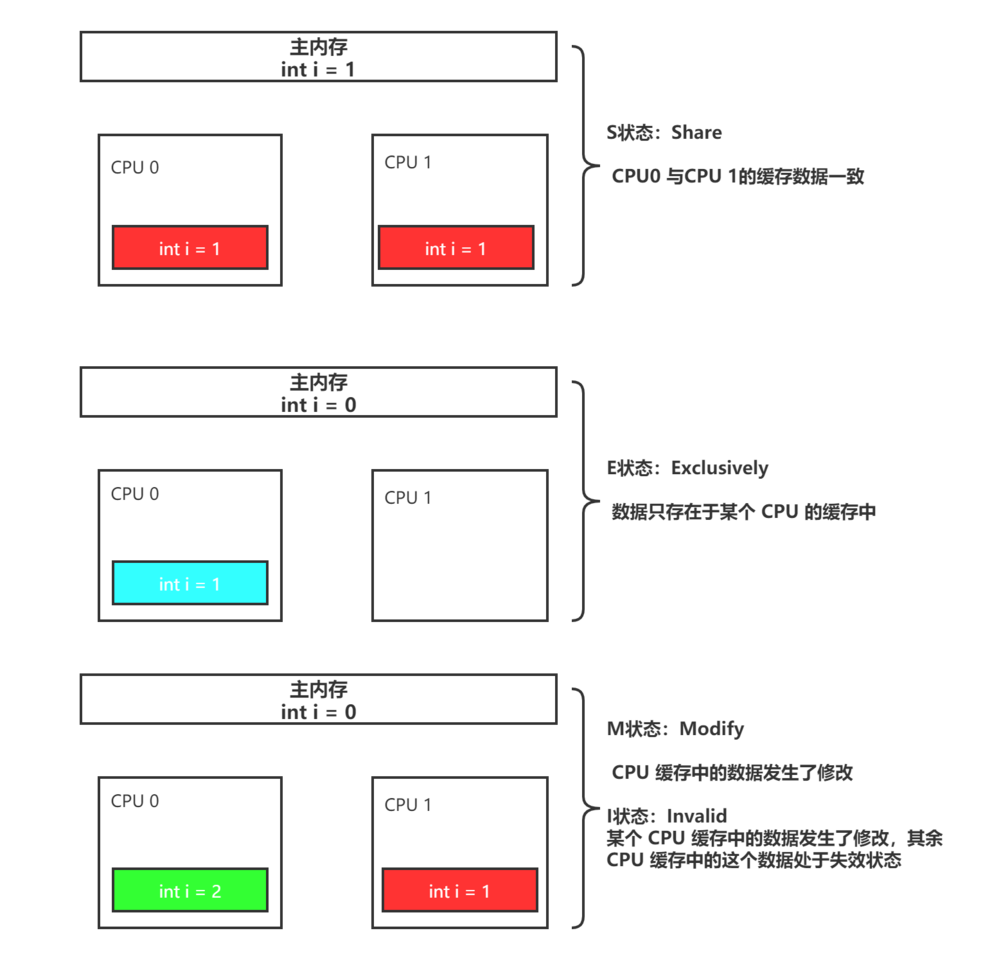
缓存一致性协议,通过设置缓存的几种状态,用来告知应该从哪里读写数据,在演进的过程中存在堵塞的情况。
当我们对某个 CPU 的缓存数据进行更新时,当前 CPU 需要与其他 CPU 进行一个通信,告知其他 CPU 将该缓存值设置为 I状态(Invalid),在收到其他 CPU 全部的确认之后,才会继续往下执行指令,在这段时间中一直是处于一个阻塞的状态,影响性能。
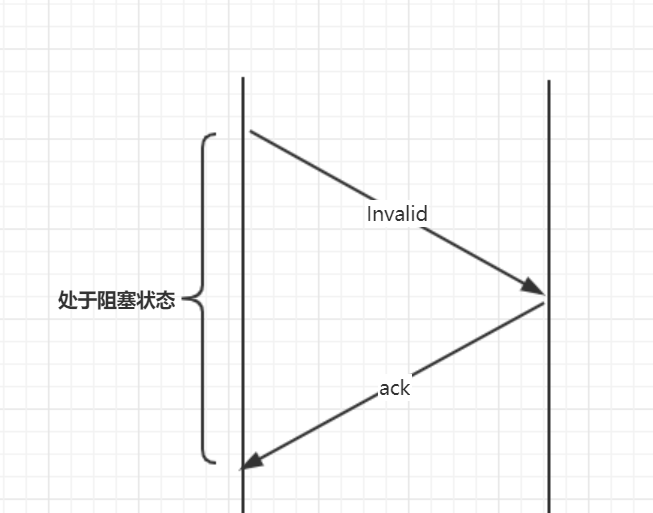
随后,出现了 storebuffer ,CPU 将 M 状态的数据写入到该文件中,并向其余 CPU 发送失效通知,这时,无需等待其余 CPU 将信息返回,可以接着往下执行指令,但相应的,带来了代码乱序执行的问题
int value = 3;
public void cpu0() {
value = 10; (1)
boolean flag = true; (2)
}
public void cpu1() {
if (flag) { (3)
assert value == 10; (4)
}
}
flag 值只存在于 CPU0 中,是一个 E 状态,value 处于一个 S 状态
(1)对 value 进行更改,状态由 S -》M,同时将操作写入到 storebuff 文件中,并发送失效通知
(2)flag 赋值
(3)读取 flage 值,由于 flag 属于一个独占状态,所以只能从主内存中去获取,也就是 if (flag) = true
(4)由于 (1) 进行的操作需要同步和通知,是一个异步操作,因此在执行到 (4) 的时候,同步可能并没有完成,读取的依旧是当前 value 的缓存值 3,也就是 assert value == 10 返回结果为 false
上述结果,与我们实际想要的结果并不符合,因为 storebuffer 的异步操作,导致代码的乱序执行,影响了最后的结果,这时 CPU 提供了一个内存屏障,比如在 (1,2)之间,插入一个 Store Memory Barrier 写屏障,要求将数据强制刷入主内存中,在(3,4)之前插入一个 Load Memory Barrier 读屏障,要求强制读取主内存中的数据,这样也就解决了乱序执行的问题,但这就相当于绕过了 CPU 为了优化而引入了 高速缓存。
JMM
- JMM ,Java 内存模型,基本工作原理和 CPU 一致
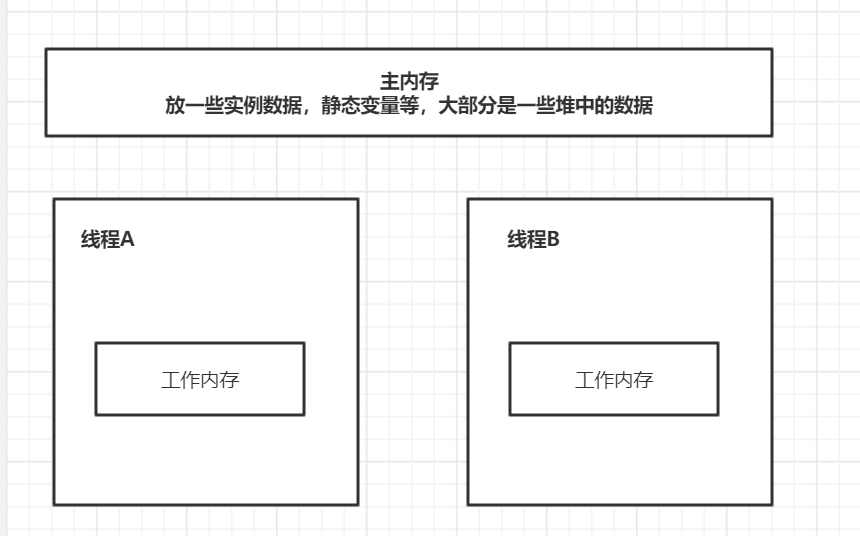
主内存中存放一些堆中可以共享的数据内容,每个线程都有自己的工作内存为线程私有,所有的计算等操作需要在工作内存中完成
Java 内存模型简单来说就是通过插入内存屏障来达到禁止重排序的功能,编译器根据具体的底层架构执行相对应的 CPU 指令,对于编译器来说,内存屏障会禁止指令重排序,CPU的内存屏障会强制读写缓存
- JMM 提供了一些解决可见性和重排序的方法
- volatile()
- synchronized
- final
- 重排序问题
编译器对于更好的利用 CPU 会对代码进行重排序,重排序的规则是不影响单线程下运行的结果
CPU 也会对指令进行相关的重排序操作,以便更有效率的执行
- 为了保证内存可见性,Java编译器在生成指令的时候,会插入一些适当的屏障来完成
volatile
增加一个 volatile 的参数,通过 javap -v class.class,然后我们找到相对应的源码

// accessFlag.hpp
class AccessFlags VALUE_OBJ_CLASS_SPEC {
friend class VMStructs;
private:
jint _flags;
public:
// Java access flags
bool is_public () const { return (_flags & JVM_ACC_PUBLIC ) != 0; }
bool is_private () const { return (_flags & JVM_ACC_PRIVATE ) != 0; }
bool is_protected () const { return (_flags & JVM_ACC_PROTECTED ) != 0; }
bool is_static () const { return (_flags & JVM_ACC_STATIC ) != 0; }
bool is_final () const { return (_flags & JVM_ACC_FINAL ) != 0; }
bool is_synchronized() const { return (_flags & JVM_ACC_SYNCHRONIZED) != 0; }
bool is_super () const { return (_flags & JVM_ACC_SUPER ) != 0; }
// is_volatile
bool is_volatile () const { return (_flags & JVM_ACC_VOLATILE ) != 0; }
bool is_transient () const { return (_flags & JVM_ACC_TRANSIENT ) != 0; }
bool is_native () const { return (_flags & JVM_ACC_NATIVE ) != 0; }
bool is_interface () const { return (_flags & JVM_ACC_INTERFACE ) != 0; }
bool is_abstract () const { return (_flags & JVM_ACC_ABSTRACT ) != 0; }
bool is_strict () const { return (_flags & JVM_ACC_STRICT ) != 0; }
接着我们找到这个方法对应的调用逻辑,可以发现,它通过调用 OrderAccess 增加了内存屏障
if (cache->is_volatile()) {
if (tos_type == itos) {
obj->release_int_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == atos) {
VERIFY_OOP(STACK_OBJECT(-1));
obj->release_obj_field_put(field_offset, STACK_OBJECT(-1));
OrderAccess::release_store(&BYTE_MAP_BASE[(uintptr_t)obj >> CardTableModRefBS::card_shift], 0);
} else if (tos_type == btos) {
obj->release_byte_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ltos) {
obj->release_long_field_put(field_offset, STACK_LONG(-1));
} else if (tos_type == ctos) {
obj->release_char_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == stos) {
obj->release_short_field_put(field_offset, STACK_INT(-1));
} else if (tos_type == ftos) {
obj->release_float_field_put(field_offset, STACK_FLOAT(-1));
} else {
obj->release_double_field_put(field_offset, STACK_DOUBLE(-1));
}
// 新增内存屏障
OrderAccess::storeload();
由次可以,volatile 提供了四种内存屏障
// orderAccess
inline void OrderAccess::loadload() { acquire(); }
inline void OrderAccess::storestore() { release(); }
inline void OrderAccess::loadstore() { acquire(); }
inline void OrderAccess::storeload() { fence(); }
- loadload:step1 loadload step2 :表示步骤1的数据加载优先于步骤2及其之后的操作
- storestore:step1 storestore step2:确保步骤1的写入对其他处理器优先于步骤2的写入
- loadstore:step1 loadstore step2:确保步骤1的数据状态优先于步骤2的指令执行
- storeload:step1 storeload step2 :全屏障
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
我们观察 storeload() 屏障调用的 fence 方法,可以看到,从JVM层面调用 volatie 进行重排序,在底层通过 lock 指令保证CPU层面的可见性和重排序问题
happens-before
- 顺序执行原则
- 一个线程中的操作 happends-before 该线程下后面的操作,也就是单线程下代码顺序不管怎么变,结果不变
- volatile 规则
- 对于 volatile 修饰的变量的写操作 happends-before 之后的读操作
- 传递规则
- 1 happends-before 2,2 happends-before 3,所有 1 happends-before 3
- start 规则
- start 启动之前的操作 对于 线程可见
- join 规则
- join 启动之前的操作 对于 线程阻塞
- 监视器规则
- 锁对象的释放 happends-before 锁对象的加锁
happends-before :表示 前者的操作对后者可见