该文主要为个人阅读《RocketMQ实战与原理解析》与学习RocketMQ过程中的知识总结,图片与内容部分摘自书籍与相关博文,如有雷同,敬请见谅[doge]。
简介
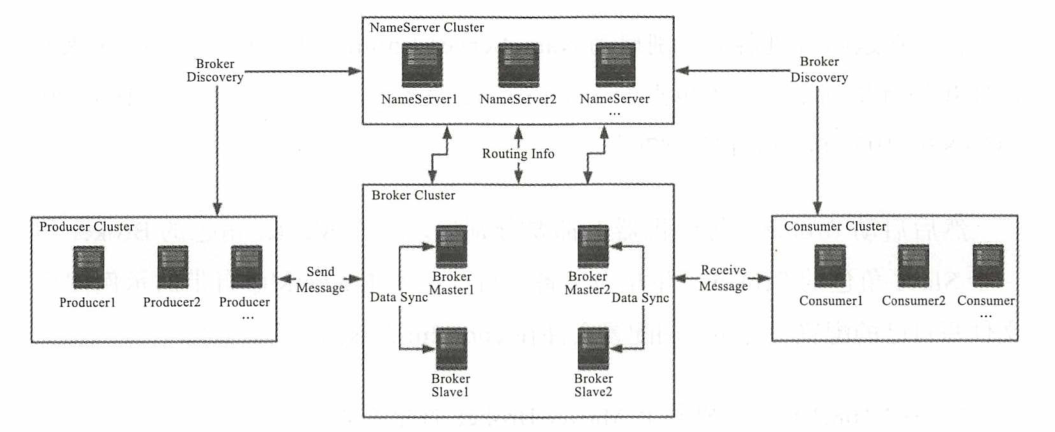
RocketMQ 作为一款分布式的消息中间件经历了多次双十一高并发的洗礼,使其在国内日受欢迎,该文章主要介绍RocketMQ中的主要概念模型与在Java中核心类,主要围绕以下四部分进行介绍与引申:
- Producer:生产消息
- Consumer:从Broker读取消费消息
- Broker:存储Producer发送过来的消息与相关信息
- NameServer:为Producer或Consumer路由消息到Broker

核心概念
-
Producer
在RocketMQ中,Producer负责生产消息,每个Producer都要为其标志所属的ProducerGroup,在ProducerGroup中的所有Producer发送同一类消息且逻辑一致,当发送事务消息后发送生产者实例崩溃了Broker可以通过ProducerGroup中的其它实例进行事务提交或回滚。 RocketMQ生产者提供的消息策略十分多,用户可根据不同的业务场景用不同的写入策略项消息队列里写入消息,如同步发送、异步发送、延迟发送、发送事务消息等。如果发送的是事物消息且生产者在发送之后崩溃,Broker服务器会联系同一生产者组的其他生产者实例以提交或回溯消费。 RocketMQ的生产者主要为DefaultMQProducer,其具体实现在DefaultMQProducerImpl中,不同的send方法提供不同的消息发送策略,如:
- send(Message msg):发送同步消息
- send(Message msg, SendCallback sendCallback):发送异步消息
- sendMessageInTransaction(Message msg, …):发送事务消息
-
NameServer(名字服务)
在一个消息队列集群里,每个机器的角色、IP地址都不相同,且这些信息是变动的,NameServer是整个消息队列中的状态服务器,机器的每个组件都通过它来了解全局信息。各个角色的机器都要定期向NameServer上报自己的状态,超时不上报NameServer会认为某个机器出故障不可用了,其它组件会把该机器从可用列表里移除。NameServer本身是无状态的,即NameServer中的Broker、Topic等状态信息不会持久存储。
-
Broker(代理服务器)
Broker是RocketMQ的核心,大部分“重量级”工作都是由Broker完成的,如:
- 接收Producer信息
- 处理Consumer的消费消息请求
- Topic维护,消息持久化存储
- 消息的HA(高可用)机制
- 服务端过滤(如消息Tag)功能等 Broker在集群中有3种角色(brokerRole),可通过Borker配置文件进行配置,主要如下:
brokerRole 描述 SYNC_MASTER 当前broker为主机,与从机同步消息后同步发送成功状态 ASYNC_MASTER 当前broker为主机,与从机同步消息后异步发送成功状态 SLAVE 当前broker为从机 需要注意的是若Broker Master宕机,Slave不能切换为Master,Slave可读不可写,类似于 Mysql 主备方式,与Redis集群的主从切换不同。
-
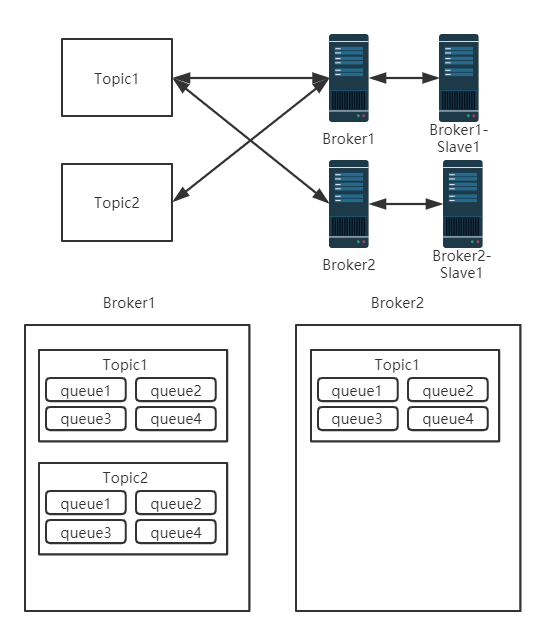
Topic(主题)与Queue(队列)
Topic是一类消息的集合,每个主题包含若干条消息,每条消息只能属于一个主题,是RocketMQ进行消息订阅的基本单位。 Queue是组成Topic的更小单元,集群消费模式下一个消费者只消费该Topic中部分Queue中的消息,当一个消费者开启广播模式时则会消费该Topic下所有Queue中的消息。 集群模式下Topic与Broker为多对多的关系, 一个Topic可在多个Broker上拥有队列,一个Broker可存储多个Topic,Topic 在所有Broker上的所存储所有消息队列里所有消息合并起来才是该Topic的全量消息。关系范例图如下(同一Topic不同Broker下的消息队列数目可能不同,正常都为相同):
-
Message(消息)
消息载体,生产和消费数据的最小单位,每条消息必须属于一个Topic。RocketMQ中的每条消息都拥有唯一的Message ID,且可添加相应的键(keys)在Broker进行消息过滤。常用属性:
- topic: 所属topic
- tags: 消息标签,用做Broker端消息过滤,可理解为二级Topic。一般一个应用只含一个topic,应用下的不同业务消息可以通过tag进行划分
- keys: 消息关键词,查询消息使用
- body: 消息内容
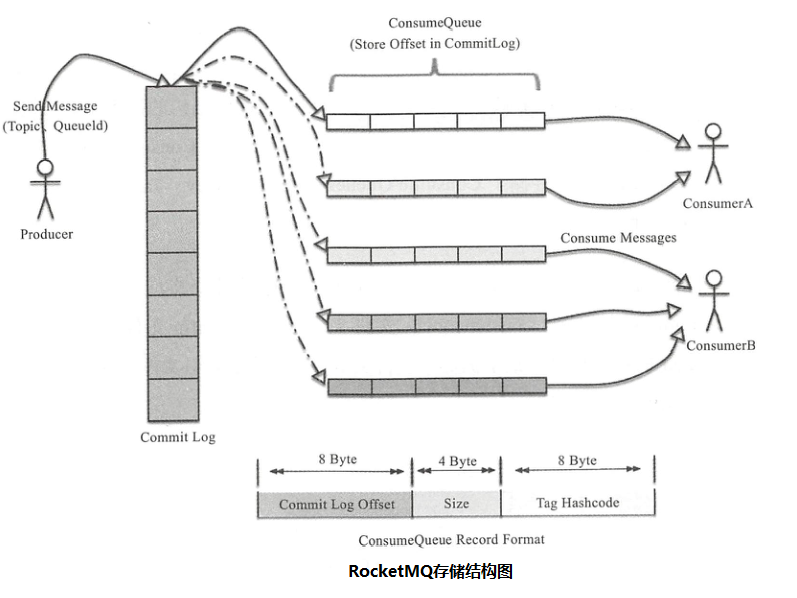
RocketMQ消息的存储是由ConsumeQueue和ConsumeLog完成的,消息物理存储文件是CommitLog,CommitQueue是消息的逻辑队列,类似于索引文件,存储得失指向物理存储的地址(offset)。
-
Consumer(消费者)
Consumer负责根据业务消费从Broker拉取到的消息,在应用中RocketMQ的主要业务实现部分。每个Consumer都需配置ConsumerGroup,作用与ProducerGroup类似,当一个Consumer实例故障后可通过ConsumerGroup的其它实例进行消息消费。需注意的是,消费者组的消费者实例必须订阅完全相同的Topic。
Consumer支持的两种消息消费模式
- Clustering 同一个ConsumerGroup里的每个Consumer只消费所订阅消息的一部分内容,同一个ConsumerGroup里的所有Consumer消费的消息合起来才是所订阅Topic的消息整体,即每条消息只会被其中一个Consumer消费,从而达到负载均衡的目的。
- BroadCasting 同一个ConsumerGroup里的每个Consumer都能消费到所订阅Topic的全部消息,即一个消费可被多次分发,被多个Consumer消费。
不同类型的消费者
根据使用者对读取操作的控制情况,消费者可分为两种类型:
- DefaultMQPushConsumer – 系统控制读取操作
DefaultMQPushConsumer的消息处理逻辑实际在DefaultMQPushConsumerImpl类中,消息的处理逻辑在pullMessage函数里的PullCallBack中。虽然命名为PushConsumer,但其实现方式还是通过PullRequest“长轮询”方式达到Push效果的方法,既有Pull的优点,又兼具Push方式的实时性。DefaultMQPushConsumerImpl.pullMessage()部分代码:
PullCallback pullCallback = new PullCallback() {
@Override
public void onSuccess(PullResult pullResult) {
if (pullResult != null) {
pullResult = DefaultMQPushConsumerImpl.this.pullAPIWrapper.processPullResult(
pullRequest.getMessageQueue(), pullResult, subscriptionData);
switch (pullResult.getPullStatus()) {
case FOUND:
// ...
break;
case NO_NEW_MSG:
// ...
break;
case NO_MATCHED_MSG:
// ...
break;
case OFFSET_ILLEGAL:
// ...
break;
default:
break;
}
}
}
@Override
public void onException(Throwable e) {
// ...
}
};
**Push方式优点:**
* Server端收到消息后,主动把消息推送给Client端,实时性高
**缺点:**
* 加大Server端工作量,进而影响Server的性能
* Client的处理能力各不相同,Client的状态不受Server控制,如果Client不能及时处理Server推送过来的消息,会造成各种潜在问题
**Pull方式优点:**
* Client循环从Server拉取消息,主动权在Client手里,拉取一定消息后,处理妥当了再拉取
**缺点:**
* 拉取时间间隔不好设定,间隔太短就处于一个“忙等”的状态,浪费时间,间隔太长可能导致到来的消息没有被及时处理
“长轮询”方式通过Client端与Server端的配合,达到既有Pull的优点,又能保证实时性。
* **DefaultMQPullConsumer - 使用者控制读取操作** 需额外处理事情:
1. 遍历MessageQueue读取消息
2. 维护offset,拉取消息时需传入offset参数,读取消息后续把offset存储下来(内存、数据库等)
3. 根据不同消息状态做不同的处理,具体状态类:PullStatus
### offset ###
offset用于记录消息的位置,主要有以下三种:
* maxOffset(TopicOffset类):队列里消息的最大offset+1,即下条消息入队的位置
* minOffset(TopicOffset类):标识当前队列的最小offset。由于消息存储一段时间后,消费了的消息会从从磁盘物理删除,message queue的min offset也就对应增长,即比minOffset小的消息不存在broker上了
* consumerOffset(DefaultMQPushConsumer.offsetStore维护):Consumer Group在MessageQueue上的消息消费进度,其实际值为队列中消费了的消息数+1,表示下次拉取消息的位置
DefaultMQPushConsumer.setConsumeFromWhere(ConsumerFromWhere)可设置从哪开始消费消息,但该设置的优先级在offsetStore后,当从offsetStore中读取不到offset的时候,ConsumerFromWhere的设置才生效。大部分该设置在ConsumerGroup初次启动时才有效(启动会一般会存储offset),即使Consumer正常运行时重启,依旧会接着上次的offset(从offset store中获取)开始消费,ConsumeFromWhere的设置无效。
![101\_4.png][101_4.png]
各MQ产品对比(译自RocketMQ官方文档)
| RocketMQ | Kafka | ActiveMQ | |
|---|---|---|---|
| 客户端SDK | Java,C ++,Go | Java,Scala等 | Java,.NET,C ++等 |
| 协议规范 | 拉模型,支持TCP,JMS,OpenMessaging | 拉模型,支持TCP | 推送模型,支持OpenWire,STOMP,AMQP,MQTT,JMS |
| 消息排序 | 确保对消息进行严格排序,并可以正常扩展 | 确保分区内消息的顺序 | 排他消费者或排他队列可确保顺序 |
| 定时消息 | 支持 | 不支持 | 支持 |
| 批量消息 | 支持,具有同步模式,可避免消息丢失 | 支持,带异步Producer | 不支持 |
| 广播消息 | 支持 | 不支持 | 支持 |
| 消息过滤器 | 支持,基于SQL92的属性过滤器表达式过滤 | 支持,使用kafka stream过滤 | 支持 |
| 服务器触发重新交付 | 支持 | 不支持 | 不支持 |
| 消息存储 | 高性能和低延迟文件存储 | 高性能文件存储 | 使用JDBC和高性能日志(例如levelDB,kahaDB)存储支持非常快速持久性 |
| 消息追溯 | 支持时间戳和偏移量追溯 | 支持的偏移量追溯 | 支持 |
| 消息优先级 | 不支持 | 不支持 | 支持 |
| 高可用与故障切换 | 支持主从模式 | 支持,需额外配置ZooKeeper服务器 | 支持,取决于存储,如果使用kahadb,则需要ZooKeeper服务器 |
| 消息追踪 | 支持 | 不支持 | 不支持 |
| 配置特点 | 开箱即用,用户只需要注意一些配置 | 使用键值对格式进行配置,这些值可以从文件或以编程方式提供 | 默认配置为低级别,用户需要优化配置参数 |
| 操作管理工具 | 支持,Web控制台和终端命令都可操作管理 | 支持,使用终端命令管理 | 支持 |