有时候在地铁上刷刷今日头条或者抖音,看到一些比较搞笑的视频段子,刚好会
python爬虫,就尝试通过爬虫requets库将视频抓取下来
一、具体代码实现
- 1、将今日头条上的视频分享到微信,然后用浏览器打开视频地址
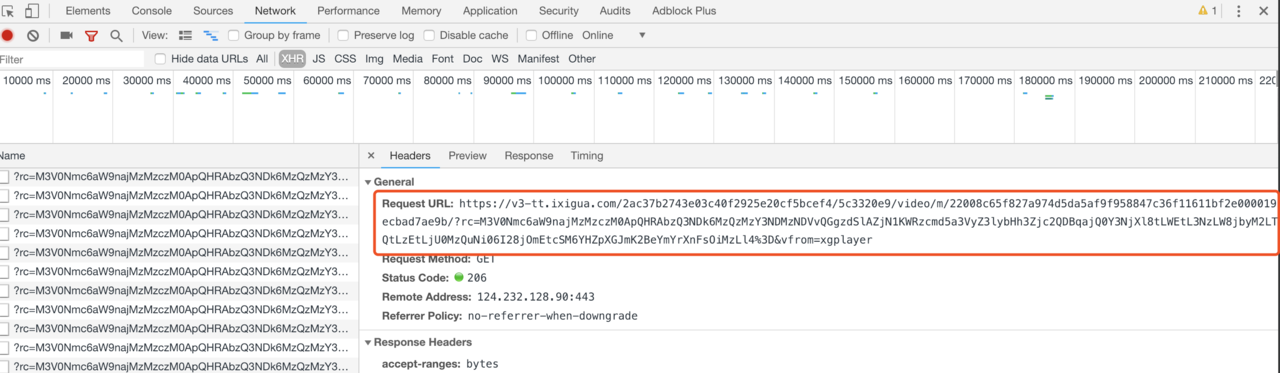
- 2、点击播放视频,然后点击
network中复制视频的播放地址
- 3、具体的代码实现
import os
import requests
# video_url = 'https://v11-tt.ixigua.com/2bd2336ad4f8906e2d4a0a3dea50a6c2/5c331e0d/video/m/220842fd7f1c11542a6bd63ffcdb06d957511610e66400001750f278748c/?rc=andpMzl0bDc2ajMzZTczM0ApQHRAbzc6NzM5MzQzMzM2NDMzNDVvQGgzdSlAZjN1KWRzcmd5a3VyZ3lybHh3Zjc2QGBtbDBxZzRpMF8tLTUtL3NzLW8jbyMzLzUvLzEtLi40MzQuNi06I28jOmEtcSM6YHZpXGJmK2BeYmYrXnFsOiMzLl4%3D&vfrom=xgplayer'
video_url = 'https://v3-tt.ixigua.com/2ac37b2743e03c40f2925e20cf5bcef4/5c3320e9/video/m/22008c65f827a974d5da5af9f958847c36f11611bf2e000019ecbad7ae9b/?rc=M3V0Nmc6aW9najMzMzczM0ApQHRAbzQ3NDk6MzQzMzY3NDMzNDVvQGgzdSlAZjN1KWRzcmd5a3VyZ3lybHh3Zjc2QDBqajQ0Y3NjXl8tLWEtL3NzLW8jbyM2LTQtLzEtLjU0MzQuNi06I28jOmEtcSM6YHZpXGJmK2BeYmYrXnFsOiMzLl4%3D&vfrom=xgplayer'
def do_load_media(url, path):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/71.0.3578.98 Safari/537.36'}
pre_content_length = 0
# 循环接收视频数据
while True:
# 若文件已经存在,则断点续传,设置接收来需接收数据的位置
if os.path.exists(path):
headers['Range'] = 'bytes=%d-' % os.path.getsize(path)
res = requests.get(url, stream=True, headers=headers)
content_length = int(res.headers['content-length'])
# 若当前报文长度小于前次报文长度,或者已接收文件等于当前报文长度,则可以认为视频接收完成
if content_length < pre_content_length or (
os.path.exists(path) and os.path.getsize(path) == content_length) or content_length == 0:
break
pre_content_length = content_length
# 写入收到的视频数据
with open(path, 'ab') as file:
file.write(res.content)
file.flush()
print('下载成功,file size : %d total size:%d' % (os.path.getsize(path), content_length))
except Exception as e:
print(e)
def load_media():
url = video_url
path = '许仙吹牛.mp4'
do_load_media(url, path)
if __name__ == '__main__':
load_media()