Master 节点周期性地向集群中的其他节点发送ping, 检查节点是否仍然活跃,如果发现集群中节点数量不足,则放弃 master 身份,重新执行选主流程。其他节点也周期性地检查 master 是否活跃,如果得不到 master 的恢复则该节点重新执行选主流程
集群中节点发现和选主依赖 Discovery Interface,ES 内置的实现是 Zen Discovery
Elasticsearch的选主算法 — Bully
Elasticsearch 集群中节点数量有限,单个节点能够处理和其他所有节点间的连接,集群中不会出现节点频繁加入和离开的情况,因此 Zen Discovery 中使用了实现比较简单的 Bully 算法。
使用 Bully 算法的集群中有一个 master 维护整个集群的状态信息,并定时向集群中其他节点推送集群状态的版本信息,如果直接使用 Bully 算法,会遇到下面几个问题,因此 Elasticsearch 做了特殊化的处理
问题1:master节点假死
master 可能因负载过重而处于不稳定的状态,可能无法响应某些节点的请求,但短时间内可以恢复正常,为了避免频繁的选举,ES 中使用了推迟选举的方法,直到 master 失效才进行选举。当节点收不到 master 的响应时会先请求其他节点,获取活跃 master 的列表,确定 master 挂掉后再发起选举。
问题2:脑裂
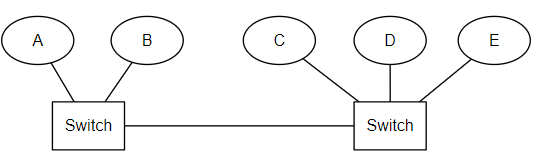
考虑下面这种情况,原集群由 A、B、C、D、E 组成,主节点是 A。当两个交换机之间连接中断之后,A、B 不能再与C、D、E 进行通信,形成了两个网络分区。A、B 组成的集群中 master 仍然是 A,而C、D、E 会选出一个新的 master,客户端访问 A、B 或者高 C、D、E 时数据不一致。
Elasticsearch 采用了设置 “法定得票人数过半” 解决,在选举过程中当节点得票达到 discovery.zen.minimum_master_nodes 的值时才能成为 master,这个值通常设定为(具有master资格节点数 / 2)+1。
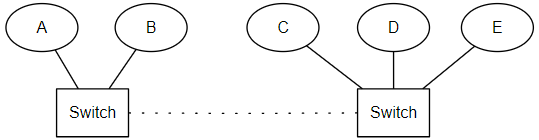
将上例中 discovery.zen.minimum_master_nodes 设置为3。当两个交换机之间连接中断之后,A不能再与C,D,E进行通信,C、D、E所组成的网络分区中不存在活跃的master,因此发起选举。A的集群中只剩下A和B,不足minimum_master_nodes,因此放弃 master 身份。C、D、E进行投票,直到达成一致选出一个 master,形成一个新的集群,其中节点数量为 3,刚好满足 minimum_master_nodes,而A、B不再处理来自客户端的请求。
选主过程
通过 ZenDiscovery::findMaster 确定临时 master:
private DiscoveryNode findMaster() {
// 1. PING 所有节点,获取各节点保存的集群信息
List<ZenPing.PingResponse> fullPingResponses = pingAndWait(pingTimeout).toList();
// 2. 由于上面是获取的其他节点的信息,这里需要将本节点加上
final DiscoveryNode localNode = transportService.getLocalNode();
fullPingResponses.add(new ZenPing.PingResponse(localNode, null, this.clusterState()));
// 3. 若设置了 master_election_ignore_non_masters 则去掉没有 master 资格(node.master: false)的节点
final List<ZenPing.PingResponse> pingResponses = filterPingResponses(fullPingResponses, masterElectionIgnoreNonMasters, logger);
// 4. 将各节点认为的 master 加入 activeMasters 列表
List<DiscoveryNode> activeMasters = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {
// 避免未经其他节点检查就将本节点选为 master
if (pingResponse.master() != null && !localNode.equals(pingResponse.master())) {
activeMasters.add(pingResponse.master());
}
}
// 5. 将 PING 到的具有 master 资格的节点加入 masterCandidates 列表作为候选节点
List<ElectMasterService.MasterCandidate> masterCandidates = new ArrayList<>();
for (ZenPing.PingResponse pingResponse : pingResponses) {
if (pingResponse.node().isMasterNode()) {
masterCandidates.add(new ElectMasterService.MasterCandidate(pingResponse.node(), pingResponse.getClusterStateVersion()));
}
}
if (activeMasters.isEmpty()) {
// 6. 没有活跃的 master
if (electMaster.hasEnoughCandidates(masterCandidates)) {
// 7. 拥有足够的候选节点,则进行选举
final ElectMasterService.MasterCandidate winner = electMaster.electMaster(masterCandidates);
return winner.getNode();
} else {
// 8. 无法选举,无法得到 master,返回 null
return null;
}
} else {
assert !activeMasters.contains(localNode) : "local node should never be elected as master when other nodes indicate an active master";
// 9. 有活跃的 master,从 activeMasters 中选择
return electMaster.tieBreakActiveMasters(activeMasters);
}
}
1、 在没有活跃的 master 时使用,上面第 7 步执行 master 的选举,通过 MasterCandidate::compare 对候选节点进行比较
// ElectMasterService.MasterCandidate::compare
public static int compare(MasterCandidate c1, MasterCandidate c2) {
// 优先选择集群状态版本最新的节点
int ret = Long.compare(c2.clusterStateVersion, c1.clusterStateVersion);
if (ret == 0) {
ret = compareNodes(c1.getNode(), c2.getNode());
}
return ret;
}
// ElectMasterService::compareNodes
private static int compareNodes(DiscoveryNode o1, DiscoveryNode o2) {
// 集群状态版本相同时优先选择具有 master 资格的节点
if (o1.isMasterNode() && !o2.isMasterNode()) {
return -1;
}
if (!o1.isMasterNode() && o2.isMasterNode()) {
return 1;
}
// 以上条件都相同时选择 ID 较小的节点
return o1.getId().compareTo(o2.getId());
}
2、 在有活跃的 master 时,上面第 9 步通过 ElectMasterService::tieBreakAcitveMasters 使用 ElectMasterService::compareNodes 的规则从 activeMasters 中选择
根据选出的临时 master 是否本节点等待或投票
if (transportService.getLocalNode().equals(masterNode)) {
// 选出的临时 master 是本节点,则等待被选举为真正的 master
final int requiredJoins = Math.max(0, electMaster.minimumMasterNodes() - 1);
nodeJoinController.waitToBeElectedAsMaster(requiredJoins, masterElectionWaitForJoinsTimeout,
new NodeJoinController.ElectionCallback() {
@Override
public void onElectedAsMaster(ClusterState state) {
// 成功被选举为 master
synchronized (stateMutex) {
joinThreadControl.markThreadAsDone(currentThread);
}
}
@Override
public void onFailure(Throwable t) {
// 等待超时,重新开始选举流程
synchronized (stateMutex) {
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
}
}
);
} else {
// 选出的临时 master 不是本节点,不再接收其他节点的 join 请求
nodeJoinController.stopElectionContext(masterNode + " elected");
// 向临时节点发送 join 请求(投票),被选举的临时 master 在确认成为 master 并新的集群状态后才会返回
final boolean success = joinElectedMaster(masterNode);
// 成功加入之前选择的临时 master 节点,则结束线程,否则重新选举
synchronized (stateMutex) {
if (success) {
DiscoveryNode currentMasterNode = this.clusterState().getNodes().getMasterNode();
if (currentMasterNode == null) {
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
} else if (currentMasterNode.equals(masterNode) == false) {
joinThreadControl.stopRunningThreadAndRejoin("master_switched_while_finalizing_join");
}
joinThreadControl.markThreadAsDone(currentThread);
} else {
joinThreadControl.markThreadAsDoneAndStartNew(currentThread);
}
}
}
选举完成
NodeJoinController::checkPendingJoinsAndElectIfNeeded 在节点获得足够的得票时使节点成为 master,并新的集群状态
private synchronized void checkPendingJoinsAndElectIfNeeded() {
// 计算节点得票数
final int pendingMasterJoins = electionContext.getPendingMasterJoinsCount();
if (electionContext.isEnoughPendingJoins(pendingMasterJoins) == false) {
...
} else {
// 得票数足够,成为 master
electionContext.closeAndBecomeMaster();
}
}
public synchronized int getPendingMasterJoinsCount() {
int pendingMasterJoins = 0;
// 统计节点得票数,只计算拥有 master 资格节点的投票
for (DiscoveryNode node : joinRequestAccumulator.keySet()) {
if (node.isMasterNode()) {
pendingMasterJoins++;
}
}
return pendingMasterJoins;
}