前言
锁是计算机协调多个进程或线程并发访问某一资源的控制机制。在数据库中,除了计算资源(CPU、I/O)的争用之外,数据也是一种多用户共享的资源。如何保证数据并发访问的一致性和有效性是所有数据库必须解决的一个问题。相对于其他数据库而言,mysql的锁机制比较简单,最显著的特点是不同的存储引擎支持不同的锁机制。比如MyISAM和MEMORY采用表级锁;BDB存储引擎采用页面锁,但也支持表级锁;InnoDB存储引擎采用行级锁,也支持表级锁,默认情况使用行级锁。三种锁的特点如下:
- 表级锁:开销小,加锁快;不会出现死锁;锁定力度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度小,发生锁冲突的概率最低,并发度也高。
- 页面锁:开销和加锁时间介于表锁和行锁之间;会出现死锁;锁粒度介于表锁和行锁之间,并发度一般。
表锁
Mysql表锁有两种模式:表共享读锁(table read lock)和表独占写锁(table write lock)。对表的读操作不会阻塞其他用户对同一表的读操作,但会阻塞对同一表的写请求;对表的写操作,会阻塞其他用户对同一表的读和写操作。
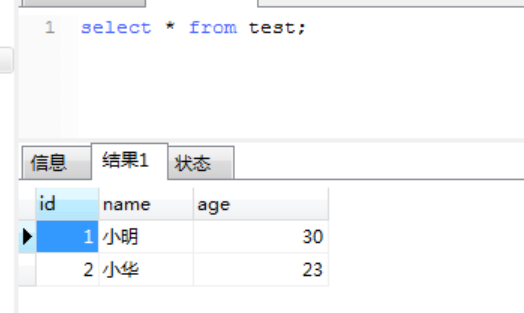
准备数据:
CREATE TABLE `test` (
`id` bigint(20) NOT NULL auto_increment,
`name` varchar(100) NOT NULL,
`age` int(10) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COMMENT='测试表';
表独占写锁
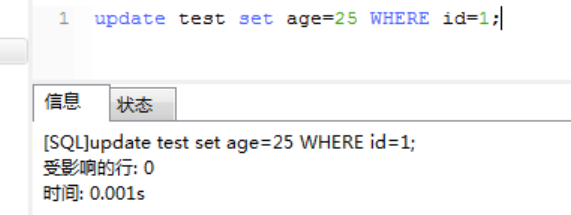
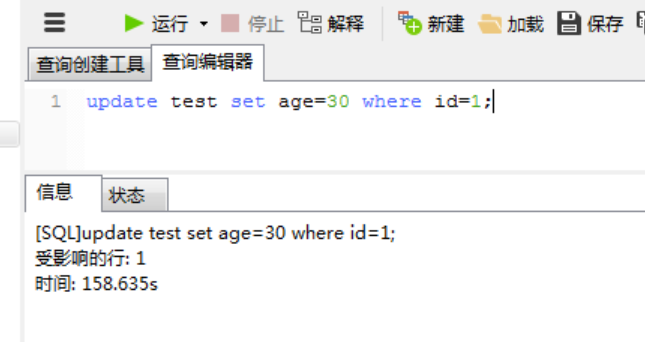
1、用户1:lock table test write; 给test表加独占写锁 2、当前用户1对test表的read,update和insert都可以执行
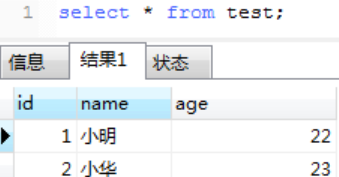
 用户2对test表的查询被阻塞,需要等待用户1对test表的写锁释放
用户2对test表的查询被阻塞,需要等待用户1对test表的写锁释放
 3、用户1释放test表的写锁
3、用户1释放test表的写锁
 用户2立刻查询到结果
用户2立刻查询到结果
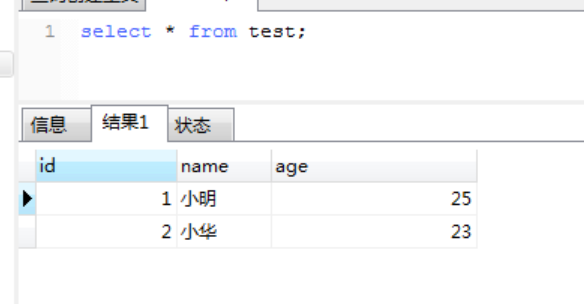
表共享读锁
1、用户1给test表加共享读锁
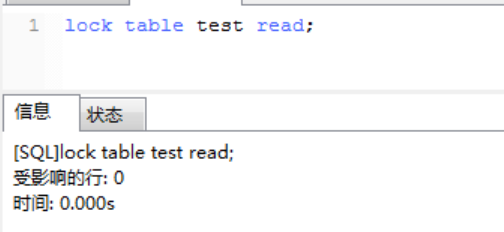 2、当前用户1可以查询test表的数据,用户2也可以查询test表的数据
2、当前用户1可以查询test表的数据,用户2也可以查询test表的数据
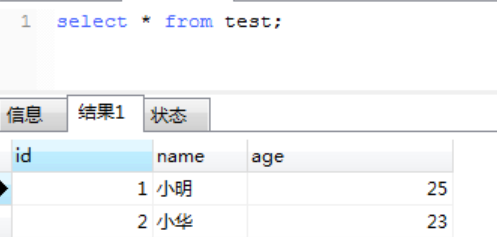 3、用户1对test表进行更新,插入报错,用户2对test表的更新和插入会等待锁
3、用户1对test表进行更新,插入报错,用户2对test表的更新和插入会等待锁
用户1更新报错:
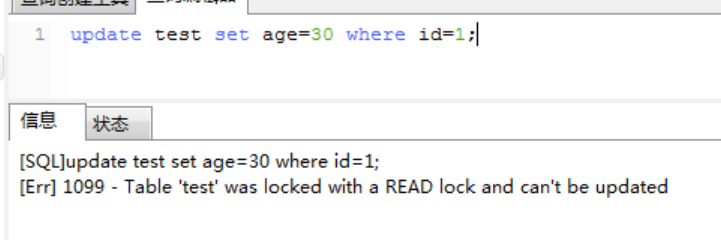 用户2更新会等待锁释放:
用户2更新会等待锁释放: 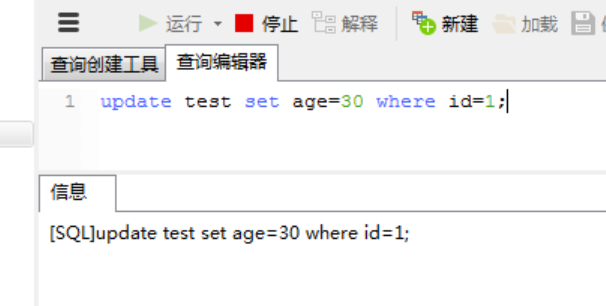 4、用户1查询其他表也会报错,用户2可以查询其他表
4、用户1查询其他表也会报错,用户2可以查询其他表
用户1查询其他表报错:
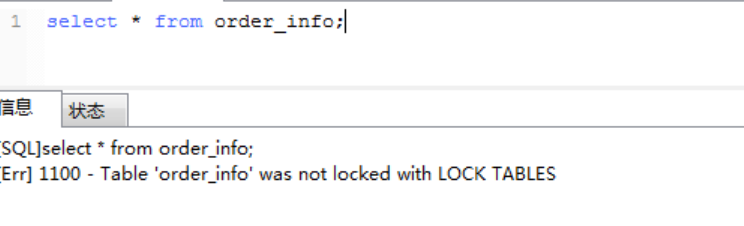 5、用户1释放表读锁,用户2等到了锁释放,更新完成
5、用户1释放表读锁,用户2等到了锁释放,更新完成
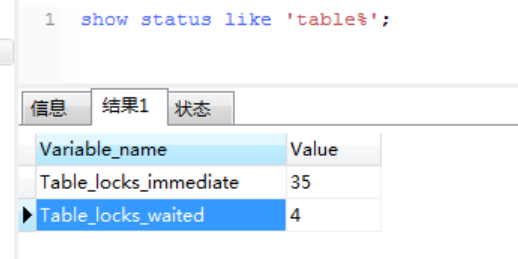
查询表级锁竞争情况
可以通过检查table_locks_waited和table_locks_immediate状态变量来分析系统上的表锁定争夺:如果table_lock_waited的值比较高,则说明存在较严重的表级锁争用情况。
并发插入
上面提到MyISAM表的读和写是串行的,但这是就总体而言。在一定条件下,MyISAM也支持查询和插入的并发执行。MyISAM存储引擎有一个系统变量concurrent_insert,专门用来控制并发插入的行为,可以取值0,1,2;
- 当concurrent_insert=0,不允许并发插入。
- 当concurrent_insert=1,如果MyISAM表中没有空洞(即表的中间没有被删除的行),允许一个进程在查询数据,另一个进程在表尾插入记录,这也是mysql的默认设置。
- 当concurrent_insert=2,无论MyISAM表有没有空洞,都可以在表尾插入记录。
举例:
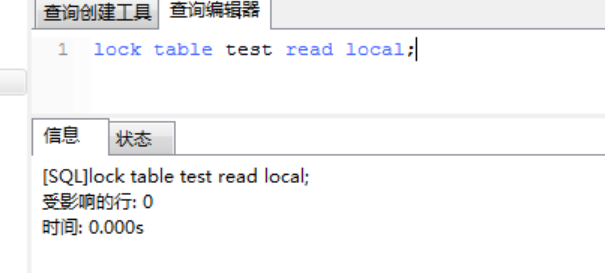
1、用户1对test表加共享读锁(注意这里要用read local)
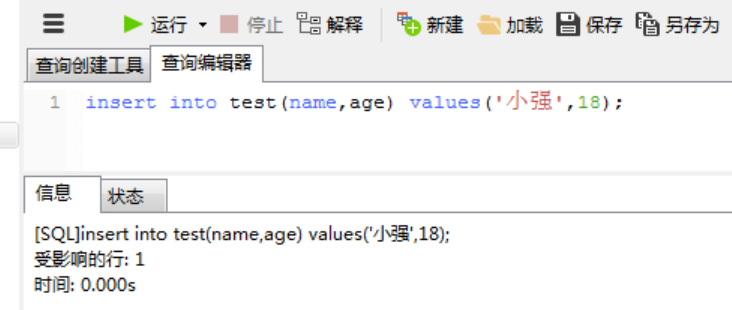
 2、用户2可以对test表进行插入操作,但是更新会等待锁释放
2、用户2可以对test表进行插入操作,但是更新会等待锁释放
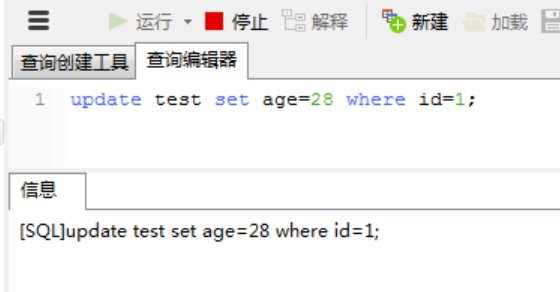
但是即使用户2插入成功,但是用户1还是只能查到加锁之前的记录,查询不到用户2新插入的记录
InnoDb行锁
两种行锁
- 共享锁(s):又称读锁。允许一个事务去读一行,阻止其他事务获得相同数据集的排它锁。若事务1对记录A加上S锁,则事务1可以读取A但不能修改A,其他事务只能再对A加S锁,不能加X锁。这就保证了其他事务可以读A,但在事务1释放A上的S锁之前不能对A做任何的修改。
- 排他锁(X):又称写锁。获取排他锁的事务可以更新数据,阻止其他事务获取相同数据集的共享读锁和排他写锁。若事务1对记录A加了X锁,则事务1可以读A,也可以修改A,其他事务不能对A加任何锁,知道事务1释放A上的锁。
注意:对于共享锁很好理解,就是多个事务只能读取数据不能修改数据。但是排他锁容易错误地理解成:如果一个事务锁住一行数据后,其他事务不能读物和修改该行数据。其实排他锁指的是一个事务对一条记录加上排他锁,其他事务不能对该记录加其他的锁。innoDb引擎默认的update,delete和insert会自动给涉及的数据加上排他锁,select语句默认不会加任何锁。所以加过排他锁的数据行在其他事务中不能修改数据,也不能通过for update加排他锁或者lock in share mode加共享锁,但是可以直接通过select…from…的方式查询数据,因为普通的查询没有任何锁机制。
事务可以通过以下语句显式给记录集加共享锁或排他锁: - 共享锁(S):SELECT * FROM table_name WHERE … LOCK IN SHARE MODE。
- 排他锁(X):SELECT * FROM table_name WHERE … FOR UPDATE。
行锁实现方式
InnoDb行锁是通过给索引上的索引项加锁来实现的,这一点mysql与oracle不同,oracle是通过在数据块中对相应数据行加锁来实现的。InnoDb的这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDb才会使用行级锁,否则InnoDb将使用表锁。 举个例子:
- 在不通过索引条件查询的时候,InnoDb使用的是表锁,而不是行锁。
create table test_no_index
(
id bigint(20) not null,
name varchar(50) not null
) ENGINE = INNODB COMMENT ='测试innoDb的行锁实现方式';
insert into test_no_index(id,name) values(1,'1');
insert into test_no_index(id,name) values(2,'2');
1、当用户1查询id=1的记录并对这行记录加上排他锁(要把自动提交关掉)
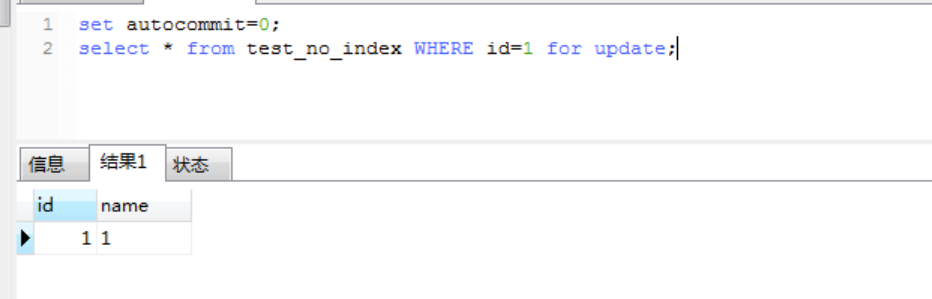 2、这时用户2查询id=2的记录却需要等待。原因是在没有索引的情况下,InnoDb只能使用表锁。
2、这时用户2查询id=2的记录却需要等待。原因是在没有索引的情况下,InnoDb只能使用表锁。
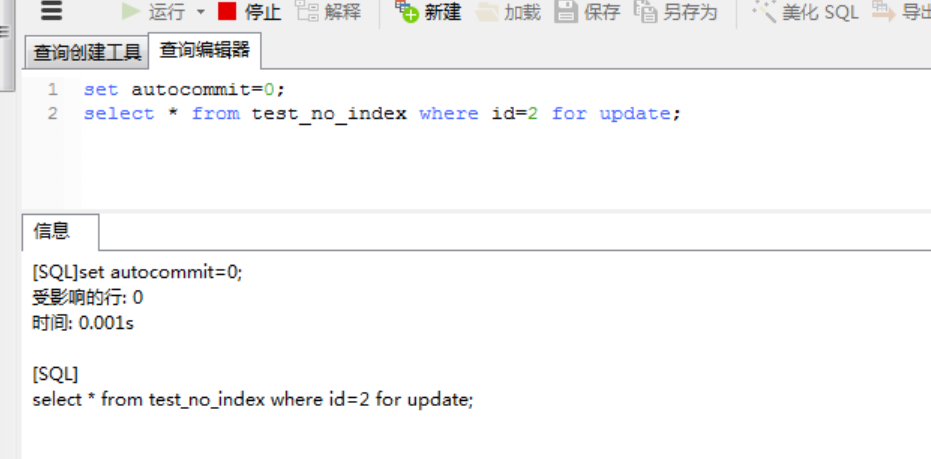 3、当我们给这个表的id字段加上一个索引后,再重复执行第1,2步骤
3、当我们给这个表的id字段加上一个索引后,再重复执行第1,2步骤
alter table test_no_index add index id(id);
用户1成功锁定id=1的记录
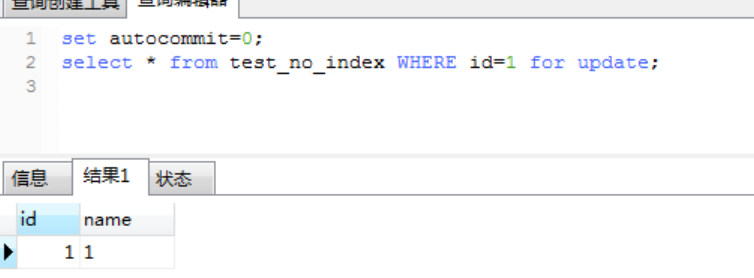 用户2也可以成功查询并锁定id=2的记录
用户2也可以成功查询并锁定id=2的记录
间隙锁(Next-Key锁)
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDb会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但不存在的记录,叫做间隙(GAP),InnoDb也会对这个“间隙”加锁,这种机制就是所谓的“间隙锁”。
例如:假如emp表中有101条数据,id的值分别是1,2,…,100,101,下面的sql:
select * from emp where id>100 for update;
是一个范围条件的检索,InnnoDb不仅会对符合条件的id=101的记录加锁,也会对id>101的间隙加锁。
InnoDb使用间隙锁的目的,一方面是为了防止幻读,以满足隔离级别的要求。对于上面的例子,要是不使用间隙锁,如果其他事务插入了id>100的任何记录,那么本事务如果再次执行上述语句,就会产生幻读。另一方面,是为了满足其恢复和复制的需要。
显然,在使用范围条件检索并锁定记录时,InnoDb这种锁机制会阻塞符合条件范围内键值的并发插入,这往往会造成严重的锁等待。因此,在实际应用开发中,尤其是并发插入比较多的应用,要尽量优化业务逻辑,尽量使用相等来访问和更新数据,尽量避免使用范围条件。
悲观锁和乐观锁
首先,悲观锁和乐观锁都是一种思想,并不是真实存在于数据中的一种机制。
悲观锁
当认为数据被并发修改的几率比较大,需要在修改之前借助于数据库的锁机制对数据进行加锁的思想称为悲观锁,又称PCC(Pessimisic Concurrency Control)。在效率方面,处理锁的操作会产生额外的开销,而且增加了死锁的机会。当一个线程在处理某行数据的时候,其它线程只能等待。 ** 实现方式 ** 悲观锁的实现依赖数据库的锁机制,流程如下:
- 修改记录前,对记录加上排他锁。
- 如果加锁失败,说明这条记录正在被修改,那么当前查询要等待会抛出异常。
- 如果加锁成功,可以对这条记录进行修改,事务完成后进行解锁。
- 加锁修改期间,其他事务想要对这条记录进行操作,都要等待锁释放或者不想等待抛出异常。 注意:在使用innoDb引擎实现悲观锁时,必须关闭自动提交。举例:
set autocommit=0;
//事务开始
begin;
//查询商品在某个仓库的库存
select * from inventory_summary where sku_id=1000 and warehouse_id=123456 for update;
//修改商品库存为2
update inventory_summary set quantity=2 where sku_id=1000 and warehouse_id=123456;
//提交事务
commit;
乐观锁
乐观锁的实现不需要借助数据库的锁机制,只要两个步骤:冲突检测(比较)和数据更新,其中一种典型的实现方法就是CAS(比较交换,Compare And Swap)。CAS这里不做详细解释,就是先比较后更新,在对一个数据进行更新前,先持有这个数据原有值得备份,如果当前更新的值和原来的备份相等才进行更新,否则判断为数据被其他线程改过了。当前线程再次进行重试。 *** ABA问题 ***
//查询出商品的库存是3,然后用库存为3作为条件进行更新
select quantity from inventory_summary where sku_id=1000 and warehouse_id=123456;
//修改库存为2
update inventory_summary set quantity=2 where sku_id=1000 and warehouse_id=123456 and quantity=3;
在更新之前,先查询原有的库存数,在更新库存时,用原有的库存数作为修改条件。相等则更新,否则认为是被改过的数据。但是会存在这样的情况下,比如线程A取出库存数3,线程B先将库存数更新为2,又将库存数更新为3,然后线程A更新的时候发现库存仍然是3,然后更新成功。但是这个过程可能存在问题。** 解决ABA问题一个方法是通过一个顺序递增的version字段或者时间戳**
//查询商品库存表,version=1
select version from inventory_summary where sku_id=1000 and warehouse_id=123456;
//修改商品库存为2
update inventory_summary set quantity=2,version=version+1 where sku_id=1000 and warehouse_id=123456 and version=1;
在每次更新的时候都带上一个版本号,一旦版本号和数据版本号一致就可以执行修改并对版本号执行+1操作,否则执行失败。因为每次操作版本号递增,所以不会出现ABA问题。还可以使用时间戳,因为时间戳具有天然的顺序递增性。
乐观锁和悲观锁比较
乐观锁并不是真正的加锁,优点是效率高,缺点是更新时间的概率比较高(尤其是并发度比较高的环境中);悲观锁依赖于数据库锁机制,更新失败的概率低,但是效率也低。