本文是基于已经搭建好且正常运行的Spark以及Hadoop集群上进行,为了支持Spark on Yarn是需要额外的配置。
1、Spark on Yarn配置
在搭建好的Spark上修改spark-env.sh文件:
# vim $SPARK_HOME/conf/spark-env.sh
添加以下配置:
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
yarn的capacity-scheduler.xml文件修改配置保证资源调度按照CPU + 内存模式:
<property>
<name>yarn.scheduler.capacity.resource-calculator</name>
<!-- <value>org.apache.hadoop.yarn.util.resource.DefaultResourceCalculator</value> -->
<value>org.apache.hadoop.yarn.util.resource.DominantResourceCalculator</value>
</property>
2、Spark on Yarn日志配置
在yarn-site.xml开启日志功能:
<property>
<description>Whether to enable log aggregation</description>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
修改spakr-defaults.conf文件:
spark.eventLog.dir=hdfs:///user/spark/applicationHistory
spark.eventLog.enabled=true
spark.yarn.historyServer.address=http://master:18018
修改spark-evn.sh环境变量:
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18018 -Dspark.history.fs.logDirectory=hdfs:///user/spark/applicationHistory"
yarn查看日志命令: yarn logs -applicationId <application_1590546538590_0017>
启动Hadoop和Spark历史服务器:
# mapred --daemon start historyserver
# $SPARK_HOME/sbin/start-history-server.sh
查看效果:
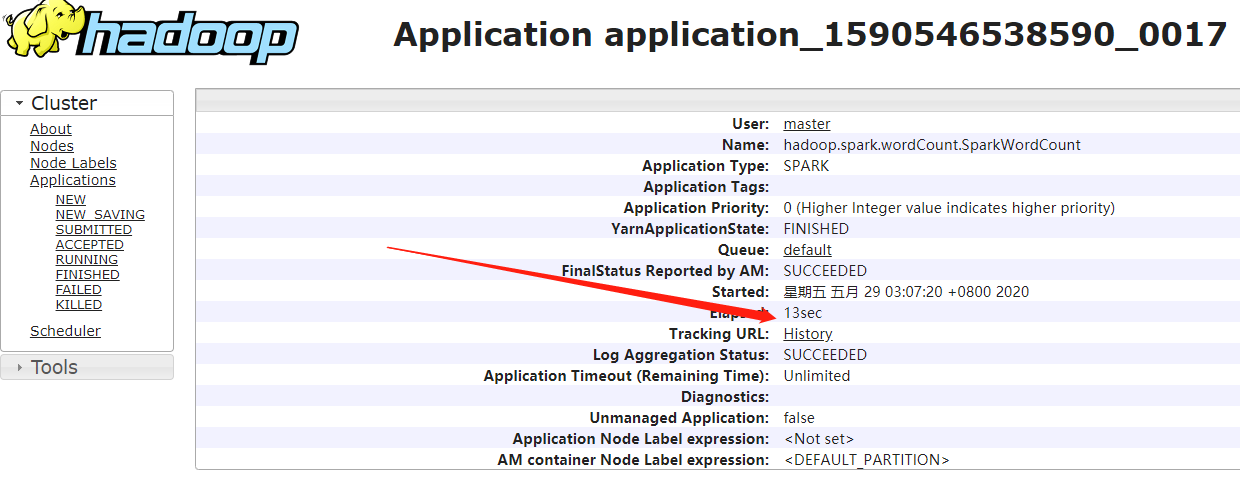
1)先进入YARN管理页面查看Spark on Yarn应用,并点击如下图的History:
2)跳转到如下的Spark版本的WordCount作业页面:
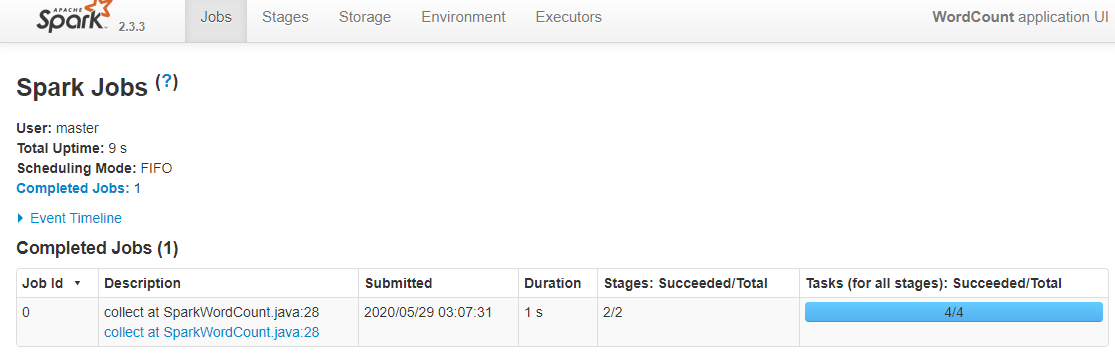
3)如上已经对Spark on Yarn日志功能配置成功。
4) SparkShell词频统计测试:
./bin/spark-shell --master yarn --deploy-mode client --total-executor-cores 3 --num-executors 3 --executor-memory 4g --executor-cores 1
在master:8080查看spark任务:

执行WordCount任务:
scala> val text = sc.textFile("hdfs:///user/liangmingbiao/wordcount_test.txt")
scala> text.flatMap(s => s.split(" ")).map(s => (s, 1)).reduceByKey((x, y) => x+y).collect().foreach(kv => println(kv))
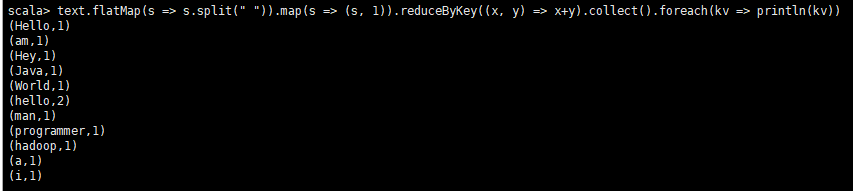
从master:8080进入查看Job任务历史:

3、调优之Jar包共享
这是SPARK on YARN调优的一个手段,节约每个NODE上传JAR到HDFS的时间,在默认情况:Spark on YARN要用Spark jars(默认就在Spark安装目录),但这个jars也可以再HDFS任何可以读到的地方,这样就方便每次应用程序跑的时候在节点上可以Cache,这样就不用上传这些jars。
解决方案:
1、 创建archive:
# jar cv0f spark-jars.jar -C $SPARK_HOME/jars/*.jar
2、 上传jar包到HDFS:
# hdfs dfs -mkdir -p /user/spark/jars
# hdfs dfs -copyFromLocal spark-jars.jar /user/spark/jars
3、 在spark-default.conf中设置
# spark.yarn.archive=hdfs:///user/spark/jars/spark-jars.jar