Insertion Sort
把最大的元素往右边一直迁移
for i in range(len(data)):
num = data[i]
j = i -1
while j>-1 and data[j]>num:
data[j+1] = data[j]
j-=1
data[j+1]=num
耗时分析:外部循环需要n次,内部最坏情况下也需要n次,总共次数为
Merge Sort
把一个数组拆成左右两个部分,一直到不可拆分,然后对左右两个数组进行合并,合并方式为,新建左右两个数组来存储原有的左右数据,然后使用两个索引分别指向左右两个数组,将比较的结果放入原数组即可
def mergeLR(self,start,mid,end,data):
i=0
j=0
k=start
# python3 语法 range(start,mid+1) mid+1无法返回
l=[ data[v] for v in range(start,mid+1) ]
r=[ data[v] for v in range(mid+1,end+1) ]
while i<len(l) and j<len(r):
if l[i] >= r[j]:
data[k]=r[j]
k+=1
j+=1
else:
data[k]=l[i]
i+=1
k+=1
for li in range(i,len(l)):
data[k]=l[li]
k+=1
for rj in range(j,len(r)):
data[k]=r[rj]
k+=1
# end 取值 如果给的是数组的长度,那么在merge的时候需要区分左侧merge和右侧merge end是否可以取得到
# 1分隔到最小的单元再合并
# 2合并左侧取到中间值,右侧则不获取
def subMerge(self,start,end,data):
if start != end :
mid = (end+start) // 2
self.subMerge(start,mid,data)
self.subMerge(mid+1,end,data)
self.mergeLR(start,mid,end,data)
耗时分析:

使用递归树分析如下:
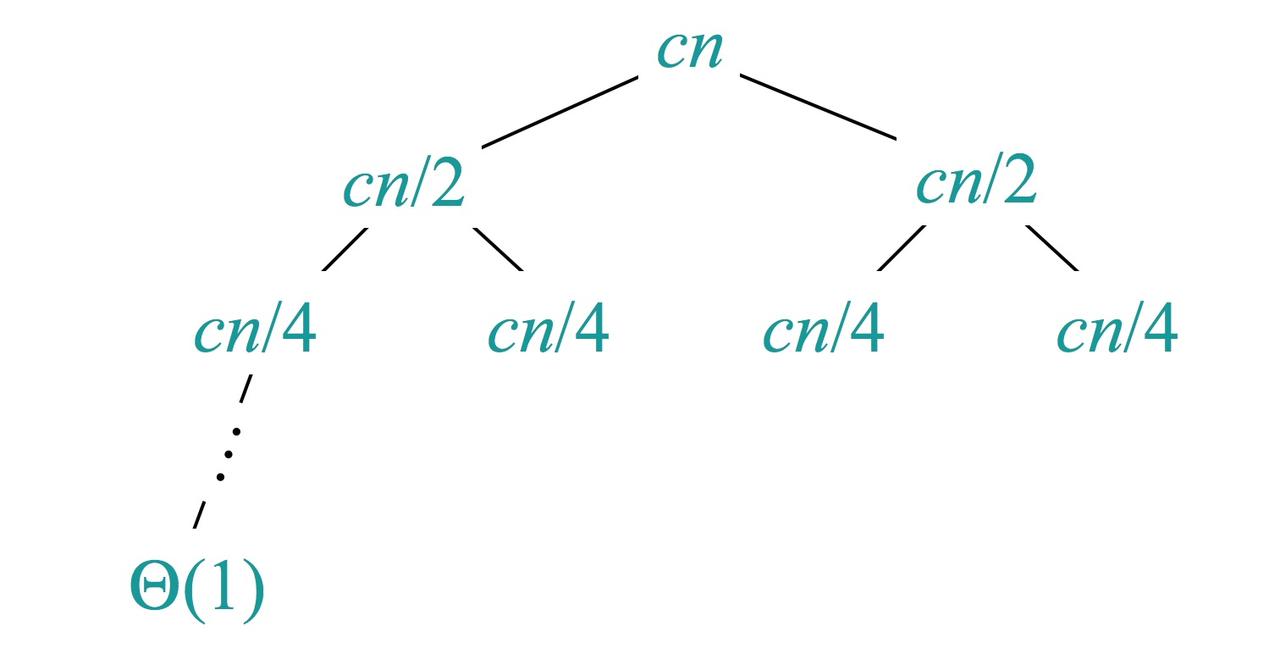 从上到下,每次叠半,那么层数为lgn,横向看每层需要合并的数量之和为cn,所以总共耗时为
从上到下,每次叠半,那么层数为lgn,横向看每层需要合并的数量之和为cn,所以总共耗时为  ,同时需要的空间为O(n)
,同时需要的空间为O(n)
java中的Arrays.sort(T[] a, int fromIndex, int toIndex,Comparator<? super T> c)可以使用MergeSort,只是后续不再使用,转而使用TimSort
Heap Sort
什么是堆
使用数组来存储元素,这个数组可以被看做一个完全二叉树
完全二叉树:所有的叶子节点具有相同的深度,树的每一层,可能除了最后一层,都是满的,比如数组a={16,14,10,8,7,9,3,2,4,1},展现形式为
可以得到一些简单的性质:parent(i)=i/2,left(i)=2i,right(i)=2i+1
- 最大堆:一个节点的值大于它的子节点的值
- 最小堆:一个节点的值小于它的子节点的值
从一个无序数组构建堆
def buildMaxHeap(self,data):
length=len(data)
# python3 语法,-1不会输出
for i in range(length//2,-1,-1):
self.maxHeapify(i,data,length-1)
从length//2+1开始,后面所有的元素都是叶子节点
往前查询的时候,新的元素可能小于它的子节点,需要维持堆的性质
def maxHeapify(self,i,data,heapSize):
lChild = 2*i+1
rChild = lChild+1
largeIndex = i
if lChild <= heapSize and data[lChild] > data[i] :
largeIndex = lChild
if rChild <= heapSize and data[rChild] > data[largeIndex]:
largeIndex = rChild
if largeIndex != i:
temp = data[i]
data[i]=data[largeIndex]
data[largeIndex]=temp
self.maxHeapify(largeIndex,data,heapSize)
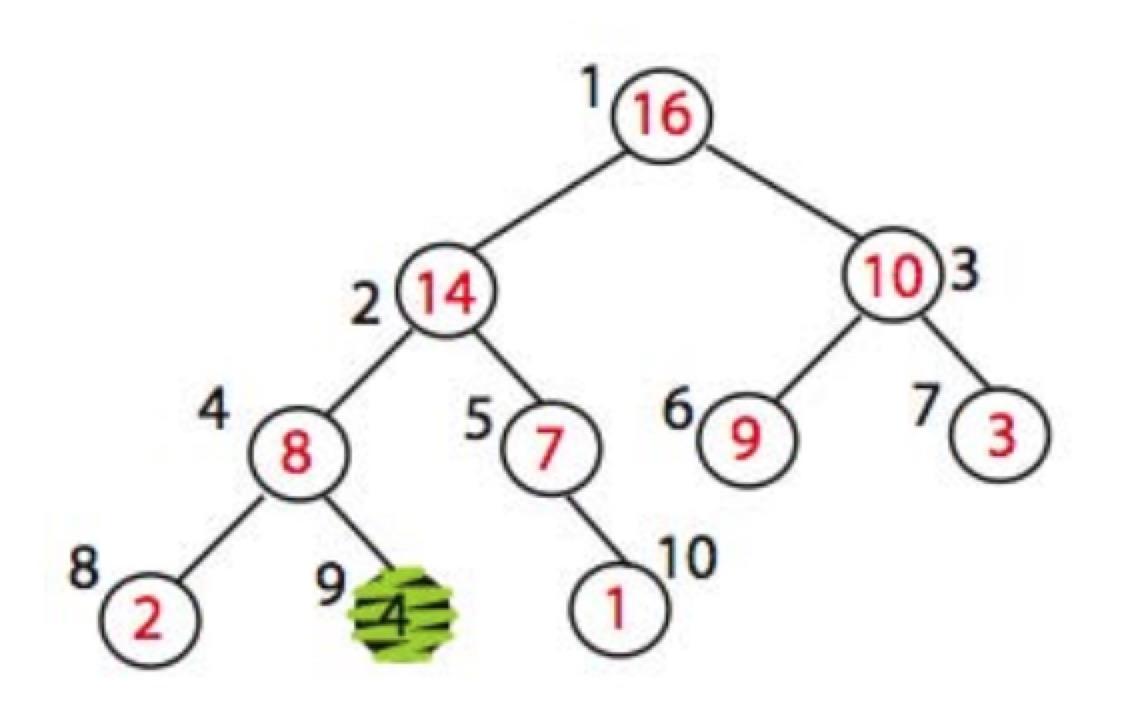
假设要构建最大堆,当前数组如下
4违反了最大堆的性质,它的左右节点是满足最大堆的,这时需要调整,找到左右节点中最大值的下标,交换父节点的值,这里就是交换下标2和下标4
再迭代,直到满足堆的性质就可以停止
构建堆的时间分析
可以看到首先要遍历一半的数组,然后有可能面对从顶层到最底层的一次修正操作,而树的高度为lgn,那么时间一定是O(nlgn),可以更细的来分析:
- 在叶子节点上一层,最多只交换1次,所需要的时间是O(1),在叶子节点上的l层,次数为O(l);
- 第1层,总共元素为 n/4个,第2层元素为n/8个,。。。,第lgn层为1个,那么时间为
 ,令
,令  ,有
,有








因此,构建一个堆的时间实际上是O(n)
c 代表常量时间,实际可证得是

堆排序
1、 从无序数组中构建一个最大堆,耗时
2、 找到最大的元素,和数组最后一个元素交换,此时最大元素在数组的最后面
3、 移除数组最后一个元素,使得堆大小减1
4、 对头部元素执行一次maxHeapify,恢复最大堆的性质
def maxHeap(self):
data = self.loadData(self.tsf)
# 1构建堆
self.buildMaxHeap(data)
# 2排序
self.sort(data)
def sort(self,data):
for i in range(len(data)-1,0,-1):
temp=data[0]
data[0]=data[i]
data[i]=temp
self.maxHeapify(0,data,i-1)
java中PriorityQueue就是一个堆,往PriorityQueue中添加元素后,维护原有的堆关系:
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (key.compareTo((E) e) >= 0)//当父节点大于子节点的时候停止
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
注意它的本身不是线程安全的,线程安全的实现为PriorityBlockingQueue
至此可以得到。堆排的时间是O(nlgn)
Count Sort
将要排序的每一个数映射到一个数组的下标,然后按照顺序输出数组的值即可
def sort(self):
k=self.maxValue+1
L=[[] for i in range(k)] //创建大小为k的数组
n=len(self.data)
for j in range(n):
# 保证原有的相同元素顺序不会更改 计算下标
L[self.data[j]].append(self.data[j])
print(L)
output=[]
for i in range(k):
output.extend(L[i])
print(output)
时间分析:需要创建最大的k个数组,时间为O(k),然后遍历n原值,时间为O(n),最后拼接到原有的输出值,每次需要判断L[i]==0?不是则加入,一直需要判断到k为止,整个过程中需要遍历L,把所有的元素加入新的元素,总共有n个,那么所耗时为O(n+k)。所需要的空间也是O(n+k),如果k=O(n),性能不错
Radix Sort
假设所有要排序的数字都是b进制,那么这个数字的位数 ,k表示最大的数(或者说要排序的数的最大的范围),排序规则为,首先查看所有数字的最低位,使用count sort来对最低位进行排序,然后第2位,一直到最高位即可
,k表示最大的数(或者说要排序的数的最大的范围),排序规则为,首先查看所有数字的最低位,使用count sort来对最低位进行排序,然后第2位,一直到最高位即可
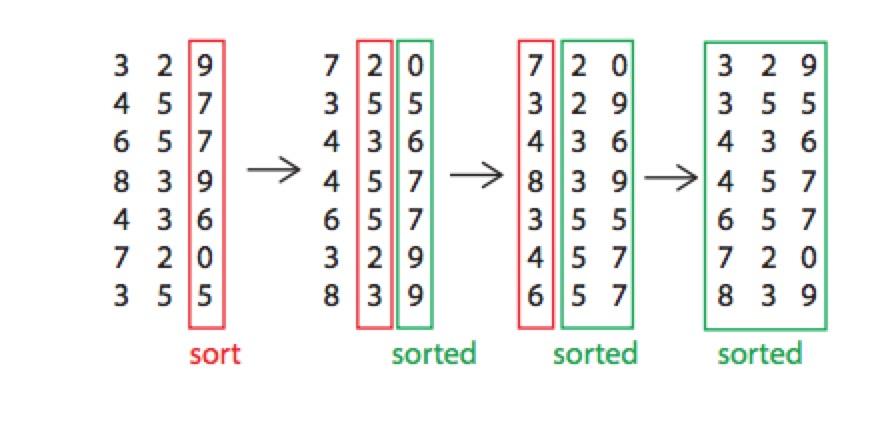
def sort(self):
for i in range(1,self.maxDigit+1):
self.__countSort(i)
def __countSort(self,n,b=10):
"""b代表进制,比如10进制,说明,最大数字是10,使用count sort解决"""
L=[[] for i in range(b)]
for x in range(len(self.data)):
v=self.data[x]
vn=self.significantIntDigit(n,v) //获取对应位数
L[vn].append(self.data[x])
print(L)
self.data=[]
for i in range(b):
self.data.extend(L[i])
def significantIntDigit(self,n,value):
"""
处理10进制
int类型直接使用,与str相比不需要len
"""
return(value // 10 **(n-1))%10
时间分析:每次排序使用的是count sort,需要时间为O(n+b),总共需要循环的次数为d次,总时间为 ,通常情况下,
,通常情况下, 时,能取到最小值为O(n)
时,能取到最小值为O(n)
快速排序
核心思想:将要排序的数组分成两个部分,分别与选定的数据进行比较,使得,执行一遍之后,左边的数都小于选定的数右边的数都大于选定的数
def sort(data,start,end):
if start>=end:
return
//使得执行完之后,数组左边的数都小于选定的数,小于右边的数
index=partition(data,start,end)
sort(data,start,index-1)
sort(data,index+1,end)
def partition(data,start,end):
//选定最后一个数作为标准
choose=data[end];
i=start-1;
j=start;
while j<end:
if data[j]<choose:
i=i+1;
swap(data,i,j)
j=j+1
i=i+1;
swap(data,i,end)
return i;
def swap(data,i,j):
temp=data[i]
data[i]=data[j];
data[j]=temp;
图例: 假设数组原始值如下
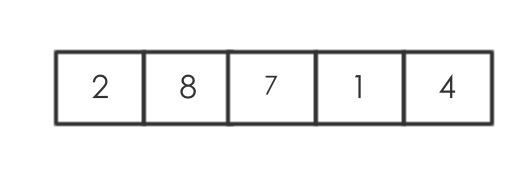 首选选定要比较的值为最后一个,即
首选选定要比较的值为最后一个,即 choose=data[end]。然后从做往右执行划分。初始化的时候,所有变量的值分别为
- i=-1
- j= 0
- choose=4
第一回:data[j]<choose,需要交换,即交换 data[i]=data[0],data[j]=data[0],执行之后如下
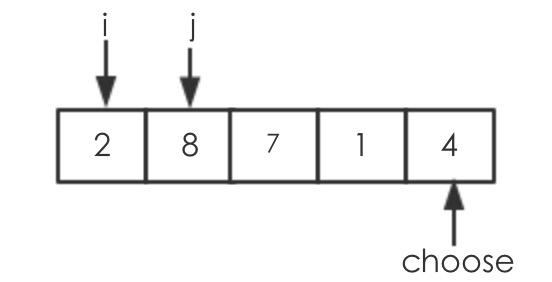 第二回:data[j]>choose,不需要执行交换操作,仅j+1
第二回:data[j]>choose,不需要执行交换操作,仅j+1
第三回:data[j]>choose,不需要执行交换操作,仅j+1,经过这两回合,数组如下 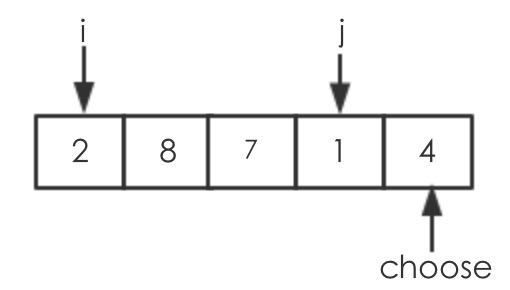 第四回:data[j]<choose,需要交换,即交换data[i]=data[1],data[j]=data[3],执行后如下:
第四回:data[j]<choose,需要交换,即交换data[i]=data[1],data[j]=data[3],执行后如下:
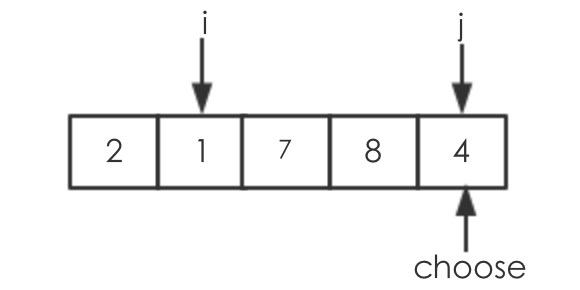 此时已经到达最后的位置,执行最后一次的交换,data[i]=data[2]与choose=data[end]交换
此时已经到达最后的位置,执行最后一次的交换,data[i]=data[2]与choose=data[end]交换
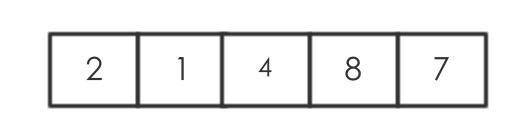 可以看到数组左边的都小于选中的数据,小于右边的数据
可以看到数组左边的都小于选中的数据,小于右边的数据
耗时分析:假设一次划分使得刚好分半,而且每次如此,可得它的划分函数为

可得T(n)=nlgn
实际上可以得到期望运行时间就是 nlgn。
但如果刚好使得每次的划分之后结果为

此时 ,这也就是快排的最坏结果
,这也就是快排的最坏结果
可以不每次只选定最后一个数,而是随机选一个数作为值,然后再比较