coursera课程 text retrieval and search engine 第三周 推荐。
如何评估一个算法是否有效
思路:构建一个可以重复使用的数据集,并且定义测量办法,来衡量结果。
感性的来说,使用不同的算法作用于同一个数据集,得到不同的结论,根据使用者的使用场景【测量】来判断哪个算法更有效,这是因为具体的场景使用,这应该是知道什么样的结果是最想要的;
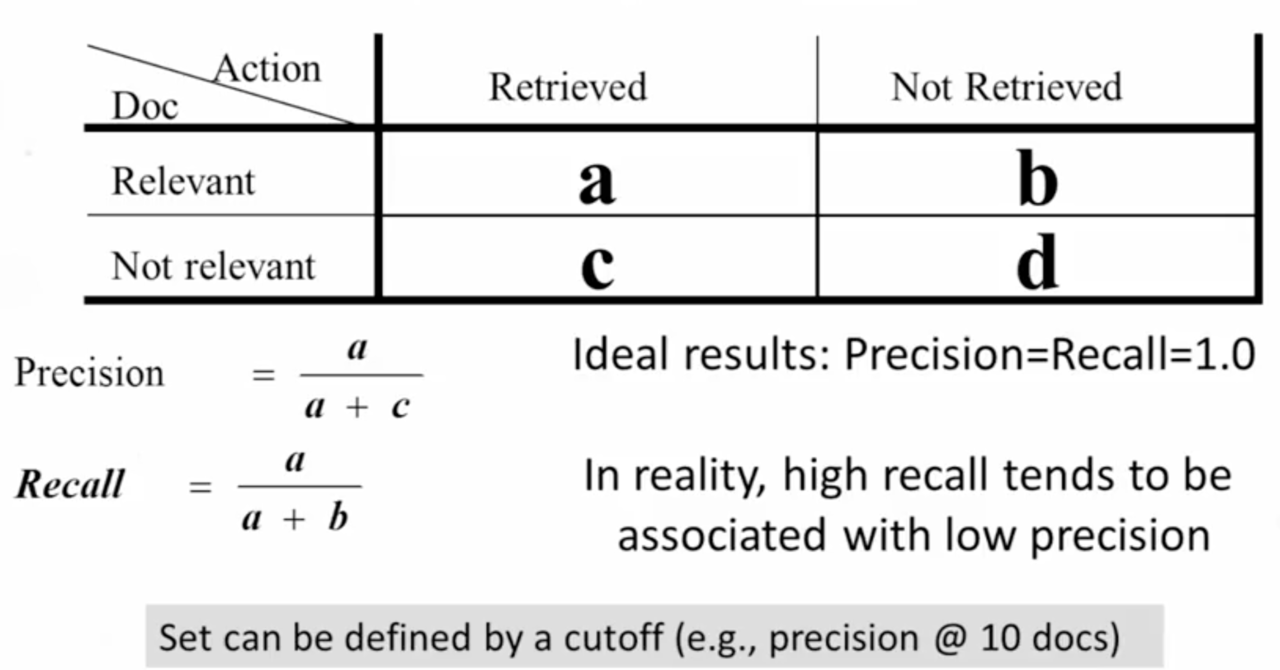
另一方面可以从理性的角度来衡量,1是精度(Precision),2是召回率(recall)
- 精度 用来度量算法返回的结果中,有多少是有用的
- 召回率 用来度量在所有的结果中,有多少被返回了
 一般说来,高的召回率意味着低精度
一般说来,高的召回率意味着低精度
当尝试去找更多的文档的时候,那也会查找更多的文件,精度随之降低 从实用性来讲,用户使用一般只看返回结果的第一屏【一般是10】,那么可以在这个范围内来衡量【前10】的准确率
可以使用PR曲线来衡量精度和召回率的关系,一个良好的PR曲线它不会偏向于任何一个算法
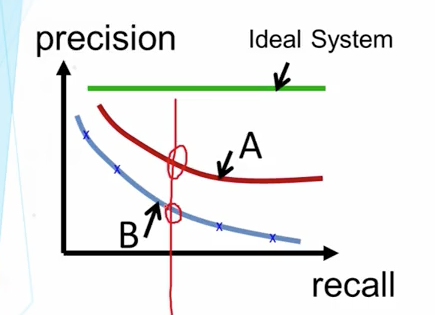
对于理想的系统而言,它的精度不会受召回率的影响。通常相同的召回率,精度越高越好,但是如果A/B两条曲线存在交点,这时候就要根据系统自己的使用场景,是关心高召回率还是高精度来选择
F-measure
组合Precision和recall,来衡量算法的有效性
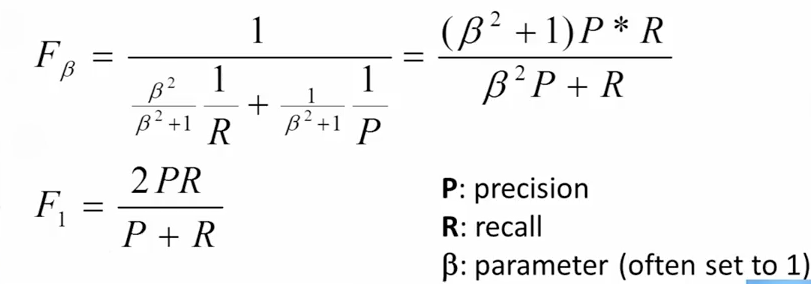
如何来衡量排序方式
使用平均精度。
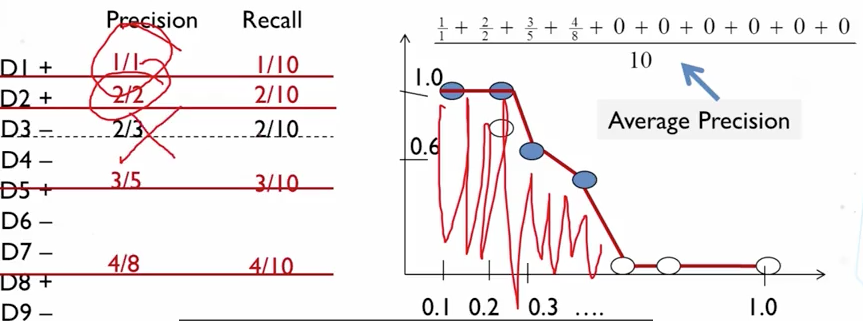
图中+号表示正确的结果,从上到下表示顺序
平均精度计算中,没有出现的精度,认为是0
此时,当任意一个文档的顺序发生变化,比如,位置下降,那么整体精度下降,上升,整体精度上身,能对排序产生灵敏的反应
衡量多个查询的排序影响
MAP:对每一个的平均值做算术平均值,即把每个平均值相加再除以中的数量
gMAP:几何平均值,即把所有的平均值相乘,再做n次幂的根号运算
MAP的值主要取决于最大的值,也就是那个查询特别相关;gMAP则受单次平均值低的影响,所以当想要提高搜索结果的质量,可以用gMAP来衡量,想让整体的查询最好,就用MAP
单个排序衡量
有的查询结果只有1个结果,比如想知道某个网站的主页,使用排序位置的倒数更好,当排在后面的时候,衡量结果越小,更直观
多层次相关性判断
每个查询结果和查询的关键字的相关性程度是不一样的,比如结果1的相关性是3,结果2的相关性是2,值越大,越相关。
一种简便的方式是直接加上所有的相关性,这种方式对相同相关性的顺序无法体现。
这时可以给每个位置一个加权,同样的相关性,越排在后面,它被用户选中的几率越小,因此共享越低,一种方式是相关性除以logR,R为顺序,这种方式称作DCG。
但是由于他会随着高相关的一直递增,而对于某些结果而言,高相关的结果本来就少,就会失去公正性,所以实行标准化,称作NDCG

A-B测试
将两个方法返回的结果混合起来,在用户不知道的情况下进行选择,用户最终点击那个方法的连接多,就证明那个方法更好
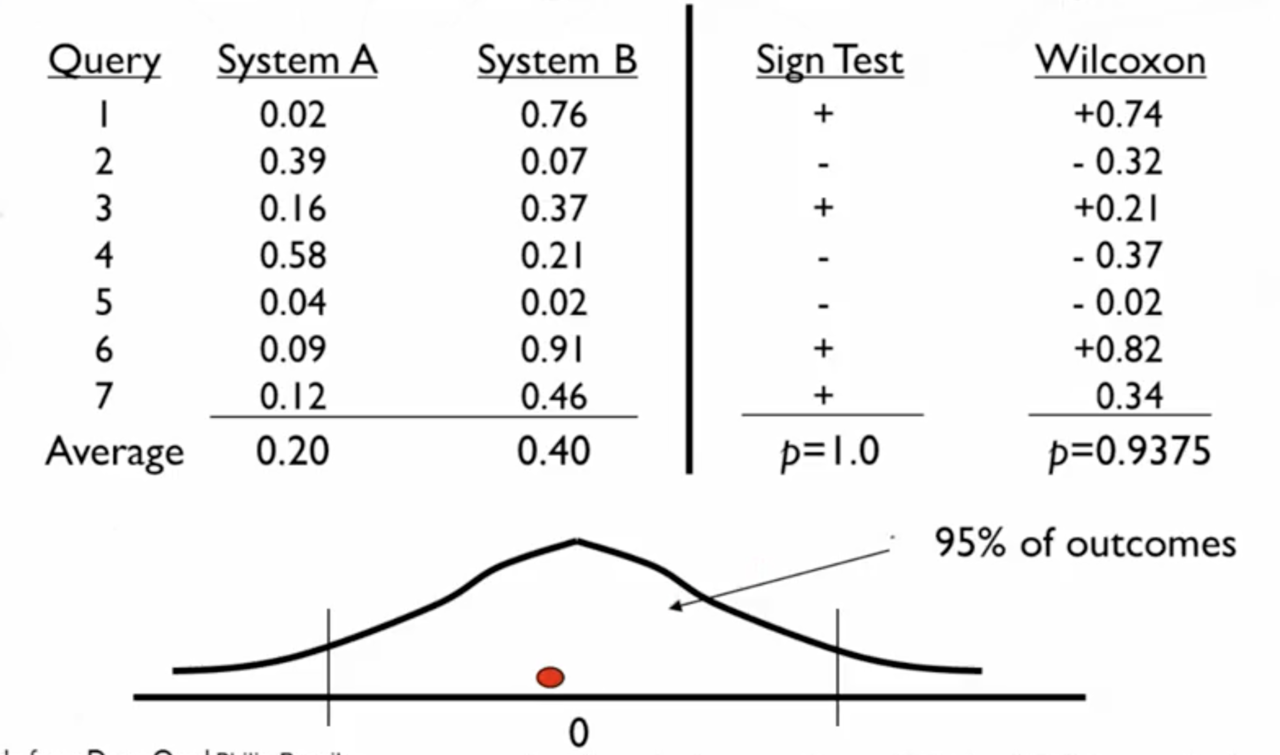
符号统计测试
对于多次实验的结果做平均值,如果表明实验A的平均值比B的平均值低,真的表明A比B要好么?而不是因为你选的特定的查询呢?
可以通过符号统计来说:
- 一是做简单的比较(sign test),如果B比A好,用减号,否则用加号;
- 二是使用Wilcoxon方法,不仅看符号而且看数值,一般来说,当得到的统计结果在95%区间之外,就可以认为平均值计算是成立的
选择全部文档的子集做判断用于测试
1、 选择多个排序的方法
2、 让每个排序方法返回前k个结果
3、 将所有的排序返回的k个结果合成一个结果池以供人来判断
4、 未放入池中的结果认为是不相关
这种方式对已有的文档系统是有效的,但是新的产生的效果可能不好