之前基于集群和单机安装过kafka,现在利用kafka提供的API构建一个简单的生产者消费者的项目示例,来跑通kafka的流程,具体过程如下:
首先使用eclipse for javaee建立一个maven项目,然后在pom.xml添加如下依赖配置:
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.2.2</version>
</dependency>
这里kafka版本是kafka_2.9.2-0.8.2.2,保存之后maven会自动下载依赖,注意要关闭windows防火墙,尽量专用网络和外网都要关闭,否则下载的很慢,下载好之后就可以编写项目代码了,这里的pom.xml所有配置如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>kafkatest</groupId>
<artifactId>kafkatest</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>kafkatest</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.9.2</artifactId>
<version>0.8.2.2</version>
</dependency>
</dependencies>
</project>
然后,我们建立一个简单生产者类SimpleProducer,代码如下:
package test;
import java.util.Properties;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
public class SimpleProducer {
private static Producer<Integer,String> producer;
private final Properties props=new Properties();
public SimpleProducer(){
//定义连接的broker list
props.put("metadata.broker.list", "192.168.1.216:9092");
//定义序列化类 Java中对象传输之前要序列化
props.put("serializer.class", "kafka.serializer.StringEncoder");
producer = new Producer<Integer, String>(new ProducerConfig(props));
}
public static void main(String[] args) {
SimpleProducer sp=new SimpleProducer();
//定义topic
String topic="mytopic";
//定义要发送给topic的消息
String messageStr = "This is a message";
//构建消息对象
KeyedMessage<Integer, String> data = new KeyedMessage<Integer, String>(topic, messageStr);
//推送消息到broker
producer.send(data);
producer.close();
}
}
类的代码很简单,我这里是kafka单机环境端口就是kafka broker端口9092,这里定义topic为mytopic当然可以自己随便定义不用考虑服务器是否创建,对于发送消息的话上面代码是简单的单条发送,如果发送数据量很大的话send方法多次推送会耗费时间,所以建议把data数据按一定量分组放到List中,最后send一下AarrayList即可,这样速度会大幅度提高
接下来写一个简单的消费者类SimpleHLConsumer,代码如下:
package test;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import kafka.consumer.Consumer;
import kafka.consumer.ConsumerConfig;
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
import kafka.javaapi.consumer.ConsumerConnector;
public class SimpleHLConsumer {
private final ConsumerConnector consumer;
private final String topic;
public SimpleHLConsumer(String zookeeper, String groupId, String topic) {
Properties props = new Properties();
//定义连接zookeeper信息
props.put("zookeeper.connect", zookeeper);
//定义Consumer所有的groupID
props.put("group.id", groupId);
props.put("zookeeper.session.timeout.ms", "500");
props.put("zookeeper.sync.time.ms", "250");
props.put("auto.commit.interval.ms", "1000");
consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(props));
this.topic = topic;
}
public void testConsumer() {
Map<String, Integer> topicCount = new HashMap<String, Integer>();
//定义订阅topic数量
topicCount.put(topic, new Integer(1));
//返回的是所有topic的Map
Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreams = consumer.createMessageStreams(topicCount);
//取出我们要需要的topic中的消息流
List<KafkaStream<byte[], byte[]>> streams = consumerStreams.get(topic);
for (final KafkaStream stream : streams) {
ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator();
while (consumerIte.hasNext())
System.out.println("Message from Topic :" + new String(consumerIte.next().message()));
}
if (consumer != null)
consumer.shutdown();
}
public static void main(String[] args) {
String topic = "mytopic";
SimpleHLConsumer simpleHLConsumer = new SimpleHLConsumer("192.168.1.216:2181/kafka", "testgroup", topic);
simpleHLConsumer.testConsumer();
}
}
消费者代码主要逻辑就是对生产者发送过来的数据做简单处理和输出,注意这里的地址是zookeeper的地址并且包括节点/kafka,topic名称要一致
上面两个类已经可以实现消息的生产和消费了,但是现在服务器需要做一定的配置才可以,否则会抛出异常,就是在之前配置的server.properties基础之上进行修改,进入kafka安装目录下,使用命令 vim config/server.properties 打开配置文件,找到host.name这个配置,首先去掉前面的#注释,然后把默认的localhost改成IP地址192.168.1.216,因为eclipse远程运行代码时读取到localhost再执行时就是提交到本地了,所以会抛出异常,当然把代码打成jar包在服务器运行就不会出现这样的问题了,这里要注意:
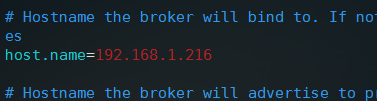
修改之后保存并退出,然后确保zookeeper的正常运行
如果之前kafka正在运行,那么就执行 bin/kafka-server-stop.sh 停止kafka服务,然后再执行
nohup bin/kafka-server-start.sh config/server.properties >> /dev/null & 启动服务,如果原来就是停止的,那么直接启动即可
启动之后先运行启动消费者,消费者处于运行等待
然后启动生产者发送消息,生产者发送完成立即关闭,消费者消费输出如下:
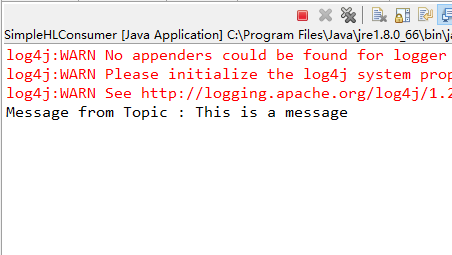
到这里,就完成了kafka从生产到消费简单示例的开发,消息队列可以跑通了