snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
这个算法单机每秒内理论上最多可以生成1000*(2^12),也就是409.6万个ID。 有很多基于雪花算法的开源实现。比如
- 美团 Leaf:美团分布式ID生成服务开源
- 百度 UidGenerator 百度开源的分布式唯一ID生成器UidGenerator,解决了时钟回拨问题
- 。。。
各家的实现大同小异,性能也都差不多,如果项目有需要的话,我们甚至可以自己实现一个,比如实现日志链的问题。
雪花算法的实现
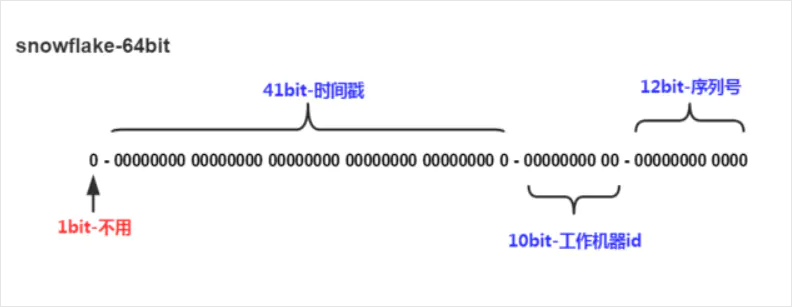
64bit id如上图所示
- 1位,不用。二进制中最高位为 1 的都是负数,但是我们生成的 id 一般都使用整数,所以这个最高位固定是 0
- 41位,用来记录时间戳(毫秒)。
- 10位,用来记录工作机器 id 这个id可以根据ip算出来。
- 12位,序列号,用来记录同毫秒内产生的不同 id
go 实现
- 根据ip生成机器id
//获取节点Ip
func GetNodeIP() string {
addrs, err := net.InterfaceAddrs()
if err != nil {
panic(err)
}
ipCount := len(addrs)
for _, address := range addrs {
if ipnet, ok := address.(*net.IPNet); ok && !ipnet.IP.IsLoopback() {
if ipnet.IP.To4() != nil {
ipNum := strings.Split(ipnet.IP.String(), ".")
if strings.Compare("10", ipNum[0]) == 0 ||
strings.Compare("172", ipNum[0]) == 0 ||
(strings.Compare("192", ipNum[0]) == 0 && strings.Compare("168", ipNum[1]) == 0) {
if ipCount > 1 && strings.Compare(ipNum[3], "1") != 0 {
return ipnet.IP.String()
}
}
}
}
}
return ""
}
// 转成int64
func ConvertToIntIP(ip string) (int64, error) {
ips := strings.Split(ip, ".")
E := errors.New("Not A IP.")
if len(ips) != 4 {
return 0, E
}
var intIP int
for k, v := range ips {
i, err := strconv.Atoi(v)
if err != nil || i > 255 {
return 0, E
}
intIP = intIP | i<<uint(8*(3-k))
}
return int64(intIP), nil
}
- 算法核心
// 因为snowFlake目的是解决分布式下生成唯一id 所以ID中是包含集群和节点编号在内的
const (
numberBits uint8 = 12 // 表示每个集群下的每个节点,1毫秒内可生成的id序号的二进制位 对应上图中的最后一段
workerBits uint8 = 10 // 每台机器(节点)的ID位数 10位最大可以有2^10=1024个节点数 即每毫秒可生成 2^12-1=4096个唯一ID 对应上图中的倒数第二段
// 这里求最大值使用了位运算,-1 的二进制表示为 1 的补码,感兴趣的同学可以自己算算试试 -1 ^ (-1 << nodeBits) 这里是不是等于 1023
//workerMax int64 = -1 ^ (-1 << workerBits) // 节点ID的最大值,用于防止溢出
numberMax int64 = -1 ^ (-1 << numberBits) // 同上,用来表示生成id序号的最大值
timeShift = workerBits + numberBits // 时间戳向左的偏移量
workerShift = numberBits // 节点ID向左的偏移量
// 41位字节作为时间戳数值的话,大约68年就会用完
// 假如你2010年1月1日开始开发系统 如果不减去2010年1月1日的时间戳 那么白白浪费40年的时间戳啊!
// 这个一旦定义且开始生成ID后千万不要改了 不然可能会生成相同的ID
epoch int64 = 1525705533000
)
// 实例化一个工作节点
// workerId 为当前节点的id,通过IP算出来
func NewWorker(workerId int64) (*Worker, error) {
// 要先检测workerId是否在上面定义的范围内
if workerId < 0 {
return nil, errors.New("Worker ID excess of quantity")
}
// 生成一个新节点
return &Worker{
timestamp: 0,
workerId: workerId,
number: 0,
}, nil
}
// 定义一个worker工作节点所需要的基本参数
type Worker struct {
mu sync.Mutex // 添加互斥锁 确保并发安全
timestamp int64 // 记录上一次生成id的时间戳
workerId int64 // 该节点的ID
number int64 // 当前毫秒已经生成的id序列号(从0开始累加) 1毫秒内最多生成4096个ID
}
// 生成方法一定要挂载在某个worker下,这样逻辑会比较清晰 指定某个节点生成id
func (w *Worker) GetStringId() string {
intA := w.GetId()
return strconv.FormatInt(intA, 10)
}
func (w *Worker) GetId() int64 {
w.mu.Lock()
defer w.mu.Unlock()
// 获取生成时的时间戳
now := time.Now().UnixNano() / 1e6 // 纳秒转毫秒
if w.timestamp == now {
w.number++
// 这里要判断,当前工作节点是否在1毫秒内已经生成numberMax个ID
if w.number > numberMax {
// 如果当前工作节点在1毫秒内生成的ID已经超过上限 需要等待1毫秒再继续生成
for now <= w.timestamp {
now = time.Now().UnixNano() / 1e6
}
}
} else {
// 如果当前时间与工作节点上一次生成ID的时间不一致 则需要重置工作节点生成ID的序号
w.number = 0
// 下面这段代码看到很多前辈都写在if外面,无论节点上次生成id的时间戳与当前时间是否相同 都重新赋值 这样会增加一丢丢的额外开销 所以我这里是选择放在else里面
w.timestamp = now // 将机器上一次生成ID的时间更新为当前时间
}
ID := (now-epoch)<<timeShift | (w.workerId << workerShift) | (w.number)
return ID
}
雪花算法的优缺点
优点
- 快(哈哈,天下武功唯快不破)。
- 没有啥依赖,实现也特别简单。
- 知道原理之后可以根据实际情况调整各各位段,方便灵活。
缺点
- 只能趋势递增。(有些也不叫缺点,网上有些如果绝对递增,竞争对手中午下单,第二天在下单即可大概判断该公司的订单量,危险!!!)
- 依赖机器时间,如果发生回拨会导致可能生成id重复。 下面重点讨论时间回拨问题。
snowflake算法时间回拨问题思考
由于存在时间回拨问题,但是他又是那么快和简单,我们思考下是否可以解决呢? 零度在网上找了一圈没有发现具体的解决方案,但是找到了一篇美团不错的文章:Leaf——美团点评分布式ID生成系统(https://tech.meituan.com/MT_Leaf.html)文章很不错,可惜并没有提到时间回拨如何具体解决。下面看看零度的一些思考:
分析时间回拨产生原因
1、 第一:人物操作,在真实环境一般不会有那个傻逼干这种事情,所以基本可以排除。
2、 第二:由于有些业务等需要,机器需要同步时间服务器(在这个过程中可能会存在时间回拨,查了下我们服务器一般在10ms以内(2小时同步一次))。
解决方法
由于是分布在各各机器自己上面,如果要几台集中的机器(并且不做时间同步),那么就基本上就不存在回拨可能性了(曲线救国也是救国,哈哈),但是也的确带来了新问题,各各结点需要访问集中机器,要保证性能,百度的uid-generator产生就是基于这种情况做的(每次取一批回来,很好的思想,性能也非常不错)https://github.com/baidu/uid-generator。 如果到这里你采纳了,基本就没有啥问题了.
时间问题回拨的解决方法:
当回拨时间小于15ms,就等时间追上来之后继续生成。
1、 当时间大于15ms时间我们通过更换workid来产生之前都没有产生过的来解决回拨问题。 首先把workid的位数进行了调整(15位可以达到3万多了,一般够用了)