数据格式
数据使用csv保存,并压缩为gz格式的文件,X为第一列,表示名字,Y为第二列表示对应的国家
数据处理的目的是根据名字预测对应的国家
名字的处理
首先对名字进行分割,然后使用ASCII码进行编码。
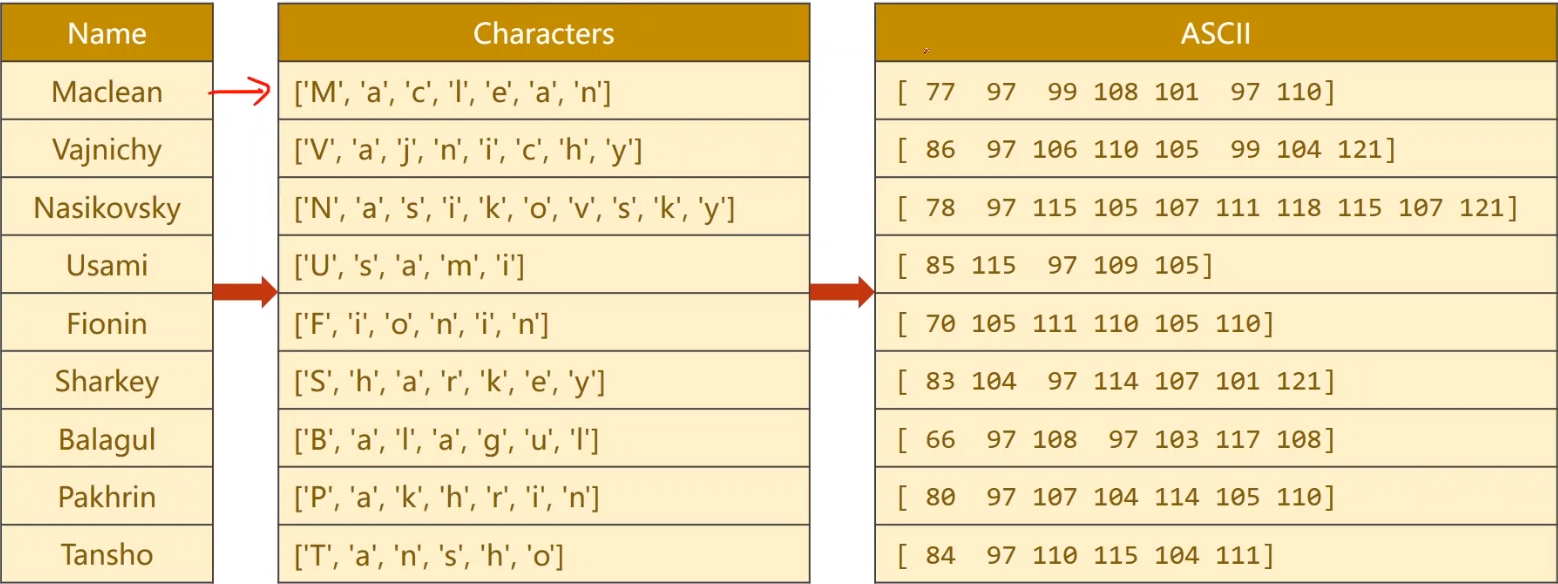
接下来进行padding操作,由于名字的长度不尽相同,因此需要在尾部添加0进行补充,使得可以送入RNN时seqLen是相同的,随后根据名字长度进行又长到短进行排序操作。

国家名的处理
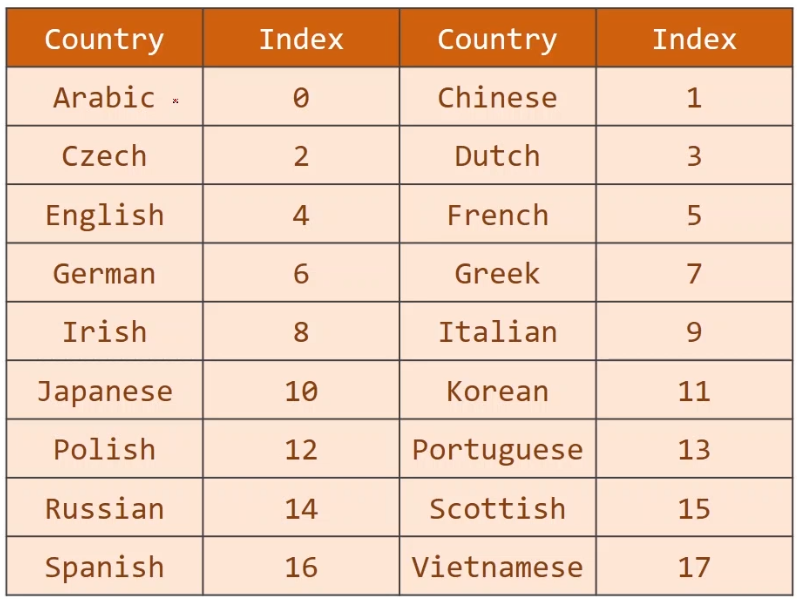
根据索引编号直接制作成字典格式即可。
import torch
from torch.utils.data import DataLoader, Dataset
import numpy as np
import gzip
import csv
import time
import matplotlib.pyplot as plt
import math
HIDDEN_SIZE = 100
BATCH_SIZE = 256
N_LAYER = 2
N_EPOCHS = 100
N_CHARS = 128
USE_GPU = True
# 数据存储到GPU上
def create_tensor(tensor):
if USE_GPU:
device = torch.device("cuda:0")
tensor = tensor.to(device)
return tensor
"""
X: name
type: str
y: country
number
"""
class NameDataset(Dataset):
def __init__(self, is_train_set=True):
filename = 'data/names_train.csv.gz' if is_train_set else 'data/names_test.csv.gz'
with gzip.open(filename, 'rt') as f:
reader = csv.reader(f)
rows = list(reader)
self.names = [row[0] for row in rows]
self.len = len(self.names)
self.countries = [row[1] for row in rows]
self.country_list = list(sorted(set(self.countries)))
self.country_dict = self.getCountryDict()
self.country_num = len(self.country_list)
def __getitem__(self, item):
# 返回名字为字符串(str), 国家为索引值(int)
return self.names[item], self.country_dict[self.countries[item]]
def __len__(self):
return self.len
def getCountryDict(self):
country_dict = dict()
# 遍历国家列表,从0开始制作字典
for idx, country_name in enumerate(self.country_list, 0):
country_dict[country_name] = idx
return country_dict
def idx2country(self, index):
return self.country_list[index]
def getCountriesNum(self):
return self.country_num
trainset = NameDataset(is_train_set=True)
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True)
testset = NameDataset(is_train_set=False)
testloader = DataLoader(testset, batch_size=BATCH_SIZE, shuffle=False)
N_COUNTRY = trainset.getCountriesNum()
def name2list(name):
# 将名字转换成ASSIC的列表
arr = [ord(c) for c in name]
return arr, len(arr)
# names为字符串构成的列表
# countries为数字构成的列表
# 返回的namesg格式为batch*inputSize
def make_tensors(names, countries):
# 将名字split然后使用ASCII码编号
sequences_and_lengths = [name2list(name) for name in names]
name_sequences = [sl[0] for sl in sequences_and_lengths]
seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_lengths])
countries = countries.long()
# make padding, append 0 to name_sequences
seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long()
for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0):
seq_tensor[idx, :seq_len] = torch.LongTensor(seq)
# sort by length to use pack_padded_sequence
seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True)
seq_tensor = seq_tensor[perm_idx]
countries = countries[perm_idx]
return create_tensor(seq_tensor), create_tensor(seq_lengths), create_tensor(countries)