1. 背景
Spark SQL的优化器有两种优化方式,即基于规则的优化方式(Rule-Based Optimization,简称为RBO)和基于代价的优化方式(Cost-Based Optimization,简称为CBO)。
Spark 2.4.3模块的Cost Model的核心思想是计算每个物理计划的代价,然后得到最优的物理计划,但是该版本Spark的这部分并没有实现,直接返回多个物理计划列表的第一个作为最优的物理计划,而SPARK-16026引入的CBO优化主要在RBO Optimizer阶段进行的,对应的Rule为CostBasedJoinReorder,并且需要开启spark.sql.cbo.enabled = true,spark.sql.cbo.joinReorder.enabled = true。spark.sql.statistics.histogram.enabled = false(默认),设置为true则启用column histogram 信息收集。
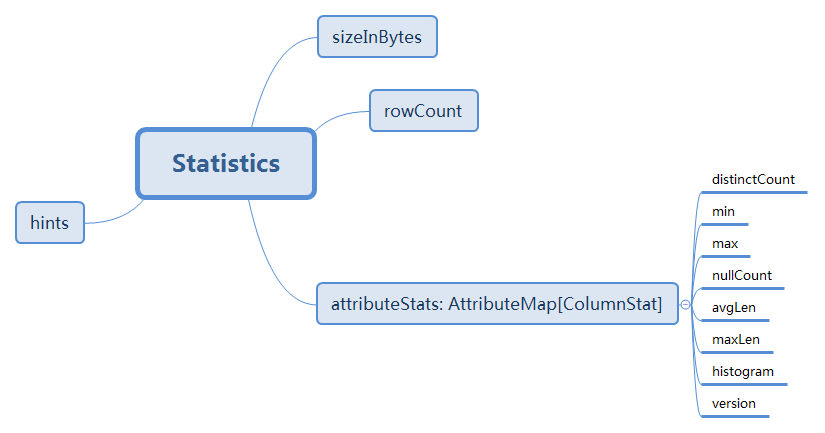
在开启CBO选项的情况下,Spark会统计收集元数据信息并存储在CatalogTable中的CatalogStatistics中,数据表存有sizeInBytes,rowCount,数据列存有distinctCount,min,max,nullCount,avgLen,maxLen,histogram,version,对于最为重要的优化Join重排序而言,根据统计信息计算部分或者全部Join顺序组合的中间关系的代价总和(根节点和叶子节点的Cost为0),动态地选取代价最小的逻辑查询计划,认为此逻辑查询计划可能会生成最优的物理查询计划。
2. 建表源码分析
咱们这里抛砖引玉,引出CBO最最核心的CatalogTable对象
Sql语句如下:sql(“CREATE TABLE IF NOT EXISTS hiveTable (key INT, value STRING) USING hive”)
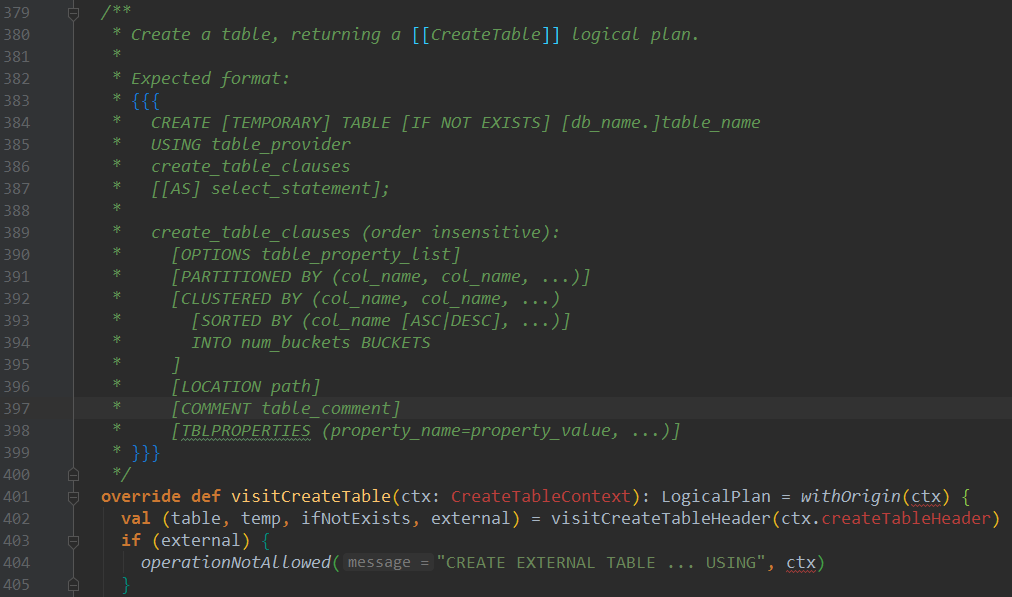
1、查看SqlBase.g4文件,进行解析
2、查看CreateTableContext类的CreateTableContext方法
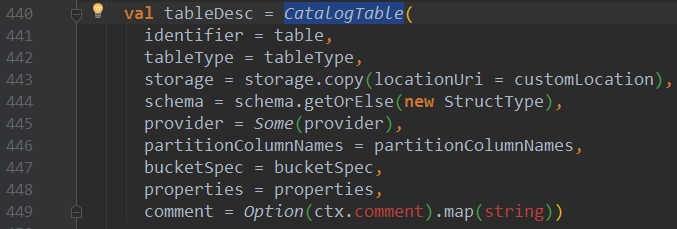
3、查看SparkSqlParser类的visitCreateTable方法,这里会构造CatalogTable对象,并最后会set进去
构造CatalogTable对象tableDesc:
调用真正建表语句的时候,会将元数据CatalogTable对象set进去:
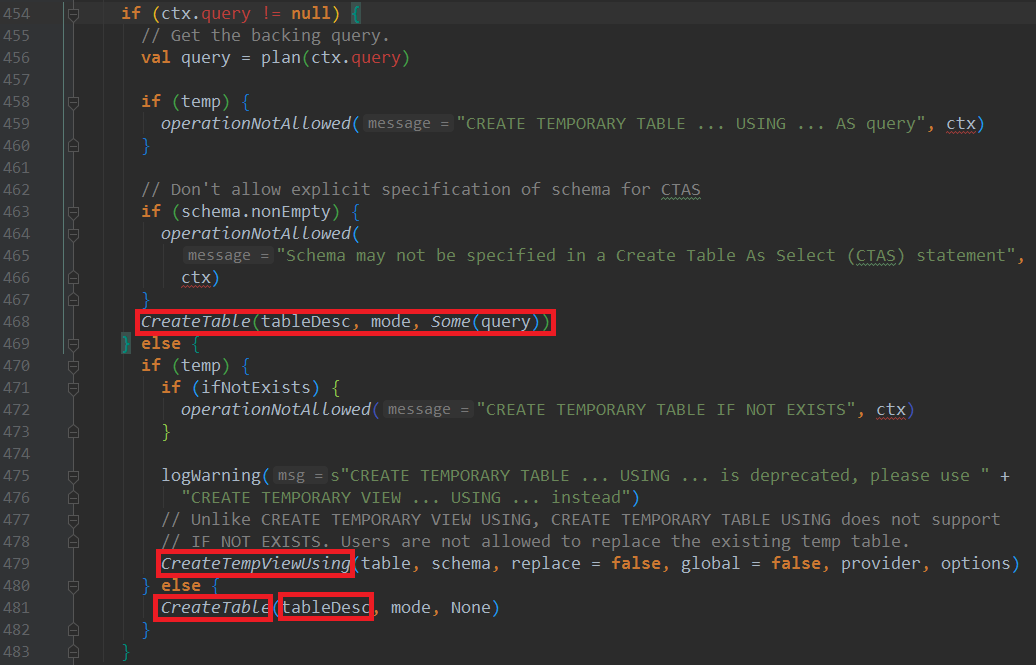
这里可以看到只有永久表会注入CatalogTable对象,而临时表或者TEMPORARY VIEW都不会注入CatalogTable对象。两者最终都会返回LogicalPlan
注意的点:
CreateTempViewUsing继承于RunnableCommand,内部可以看到run方法,而CreateTable则直接继承于LogicalPlan
3. 元数据访问
Spark的早期版本是没有标准的API来访问这些元数据的。用户通常使用查询语句(比如show tables)来查询这些元数据。这些查询通常需要操作原始的字符串,而且不同元数据类型的操作也是不一样的。
这种情况在Spark 2.0中得到改变。Spark 2.0中添加了标准的API(称为catalog)来访问Spark SQL中的元数据。这个API既可以操作Spark SQL,也可以操作Hive元数据。
SessionCatalog 是底层元数据(基于内存InMemory和基于 Hive)的代理,同时也负责临时视图和函数的管理。
ExternalCatalog 用于管理 数据库 、表、分区和函数,在 Spark SQL 中具体有两个实现:
1)InMemoryCatalog
是 ExternalCatalog 基于内存(内部使用 scala.collection.mutable.HashMap )的实现,主要用于测试和探索。不建议用于生产环境。

2)HiveExternalCatalog
是 ExternalCatalog 基于 Hive(内部使org.apache.hadoop.hive.ql.metadata.Hive )的实现。
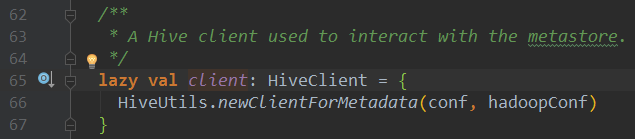
Catalog及其实现类CatalogImpl用于访问Spark SQL中的元数据,内部逻辑本质是调用SessionCatalog对象的API
总的来说逻辑是 Catalog->CatalogImpl->SessionCatalog-> ExternalCatalog-> InMemoryCatalog/ HiveExternalCatalog
4. Spark SQL CBO逻辑分析
通过查看官网资料,我们可以看到:
针对Spark SQL CBO模块,调用AnalyzeTableCommand、AnalyzeColumnCommand两个模块的方法(对应两种CBO统计sql),从Hive获取元数据CatalogTable,来构建统计信息CatalogStatistics
val tableMeta : CatalogTable = sessionState.catalog.getTableMetadata(tableIdentWithDB)
以HiveExternalCatalog为例:
上述获取元数据方法一步步会进入HiveClientImpl类的getTableOption方法:
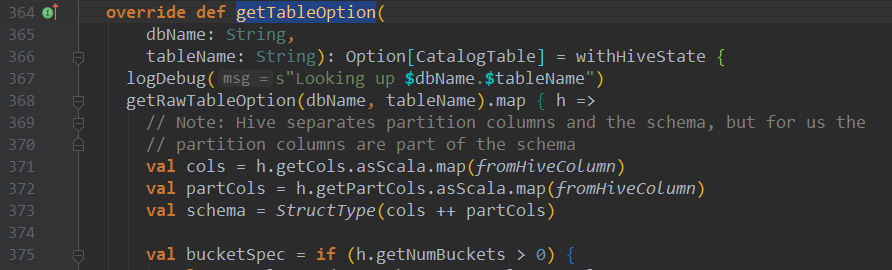
进入getRawTableOption(dbName, tableName)方法,可以看到会调用Hive对象的getTable方法来获取hive表的元数据:
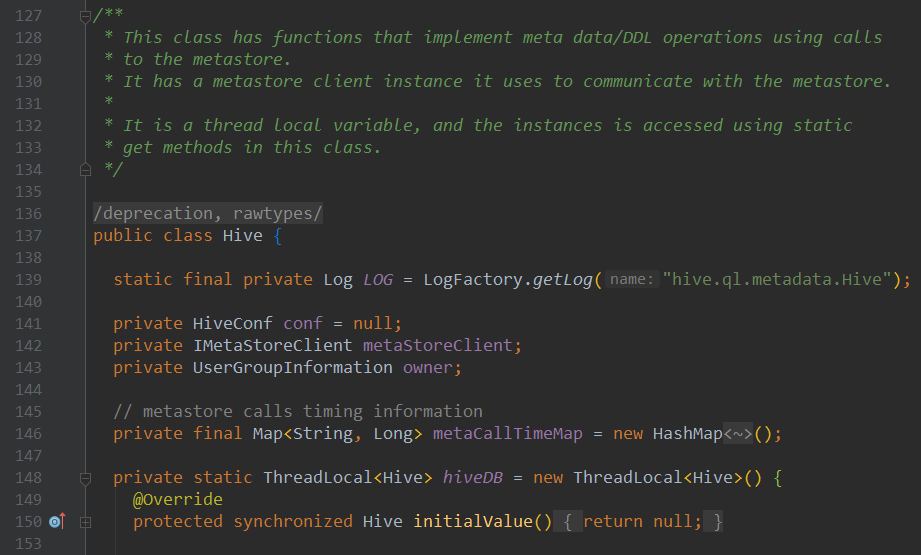
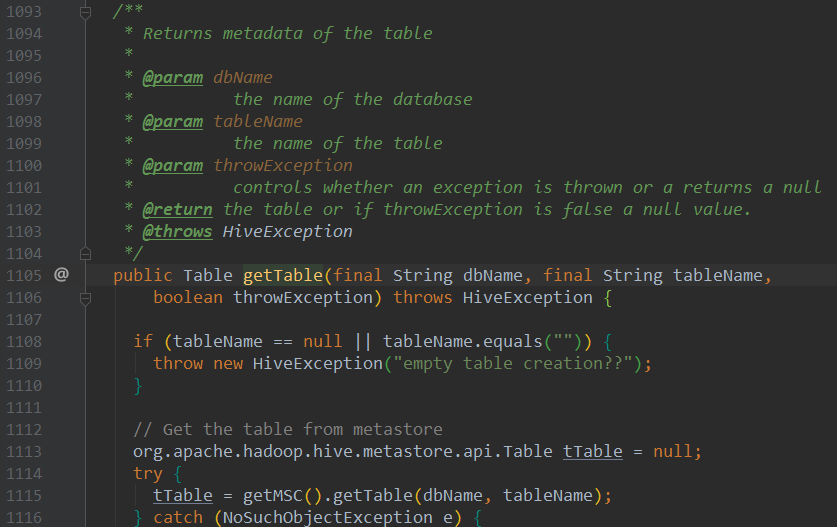
我们来看Table类(HiveTable类):
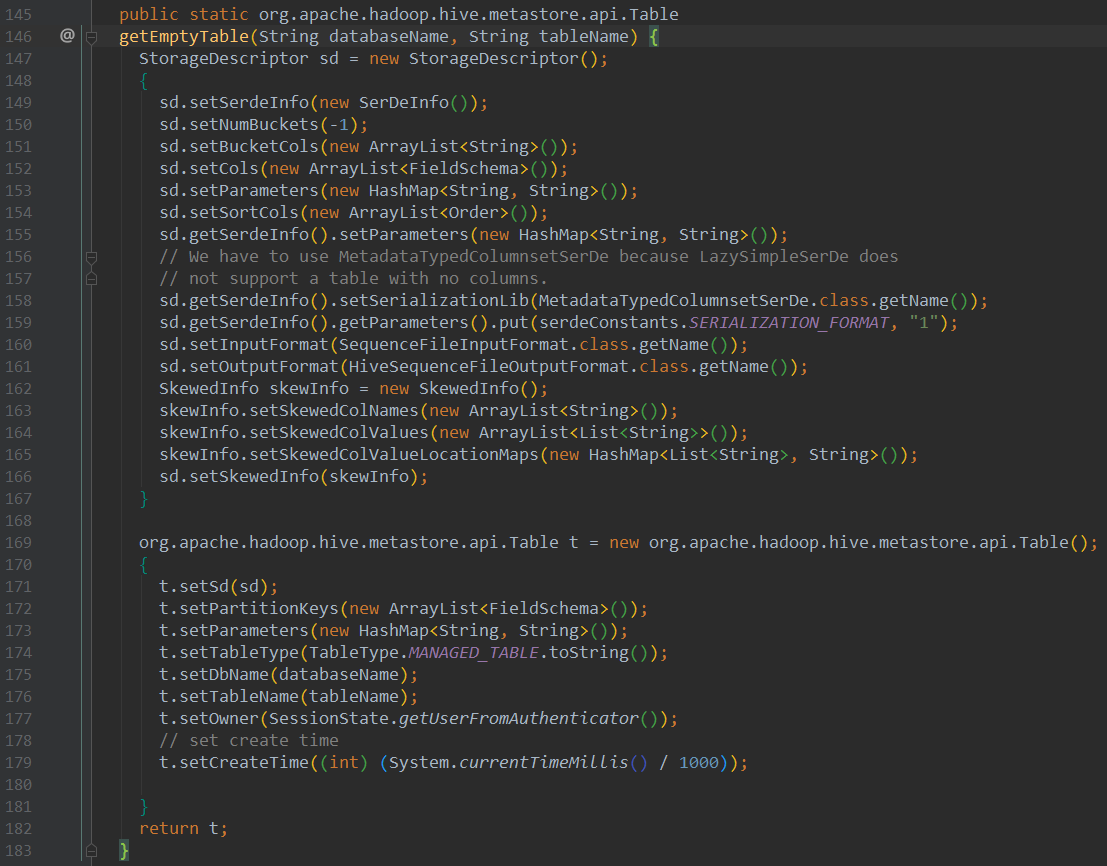
查看getTableOption方法409行,CBO统计信息基于val properties = Option(h.getParameters).map(_.asScala.toMap).orNull
此时的CatalogStatistics对象只包含sizeInBytes、rowCount,并没有列统计信息colStats
回到AnalyzeColumnCommand:通过调用如下方法来计算表中列的统计信息

进入该方法,可以找到计算统计信息的函数调用:
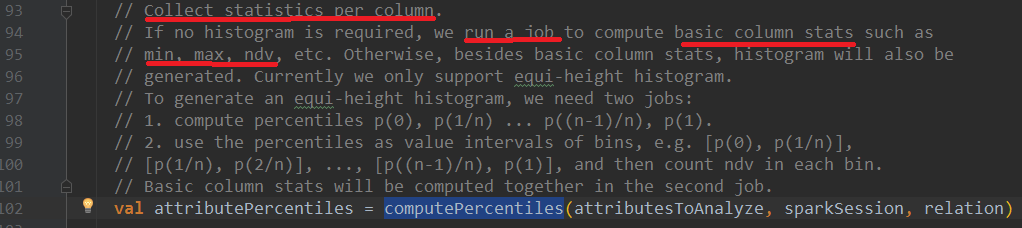
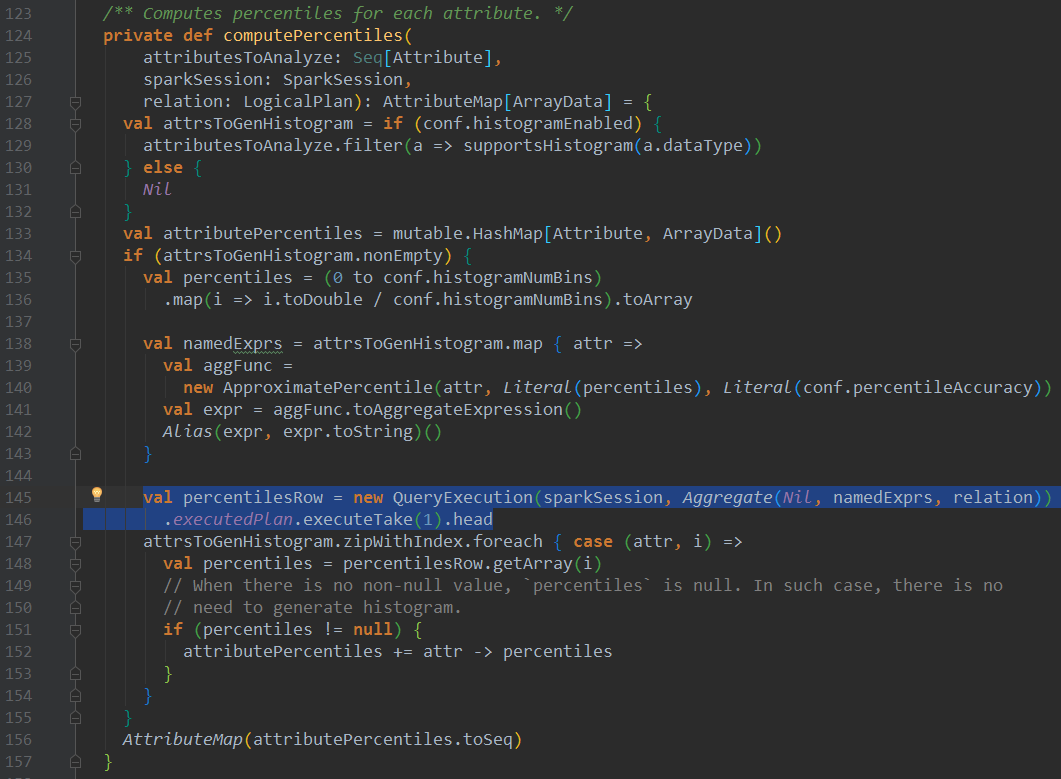
自此,我们已经看到完整的CBO统计信息计算流程了。
5. DEBUG一波
debug CBO统计信息sql语句:
对应执行的SQL语句:ANALYZE TABLE default.hiveKvTable COMPUTE STATISTICS FOR COLUMNS key,value
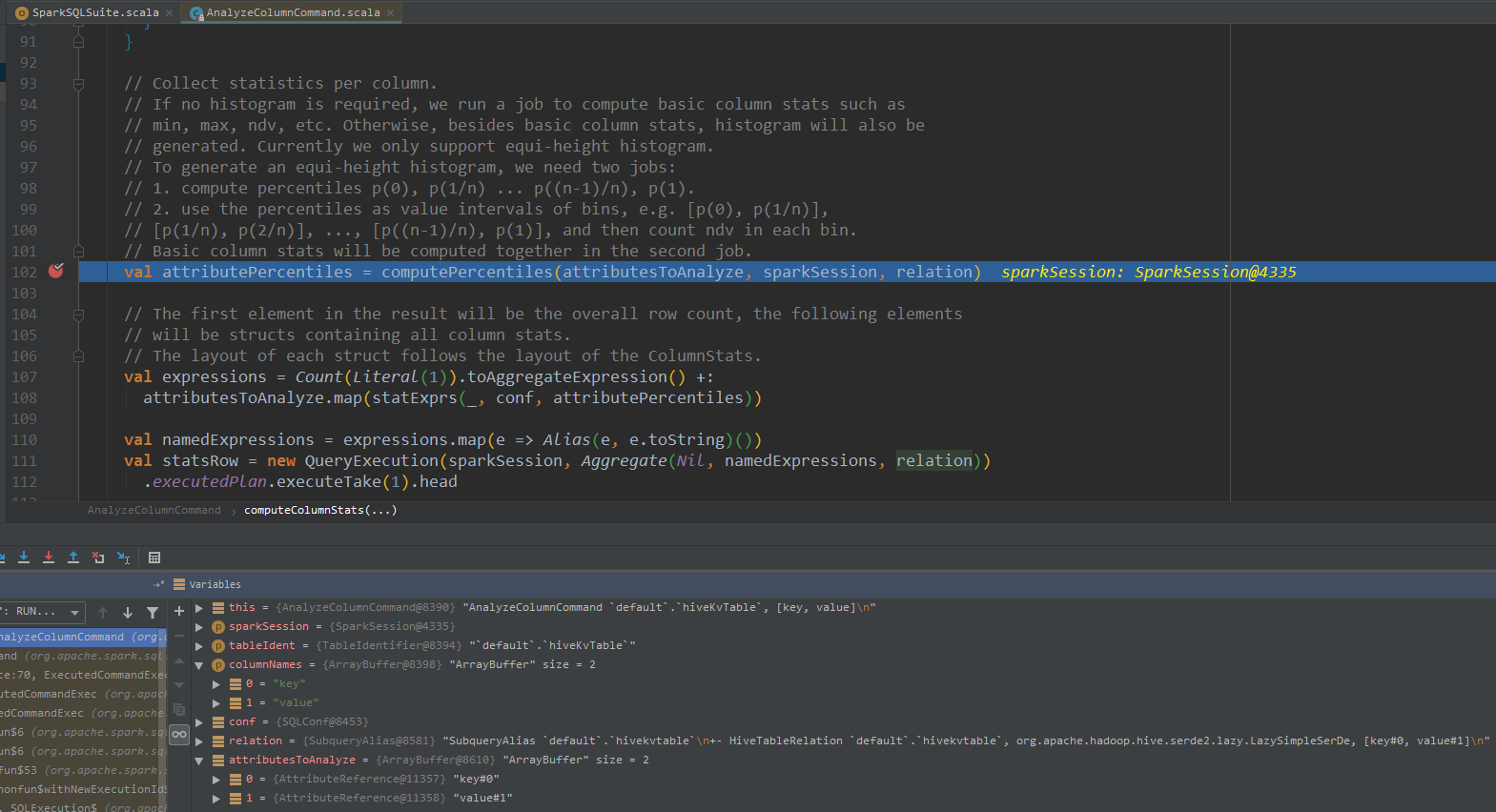
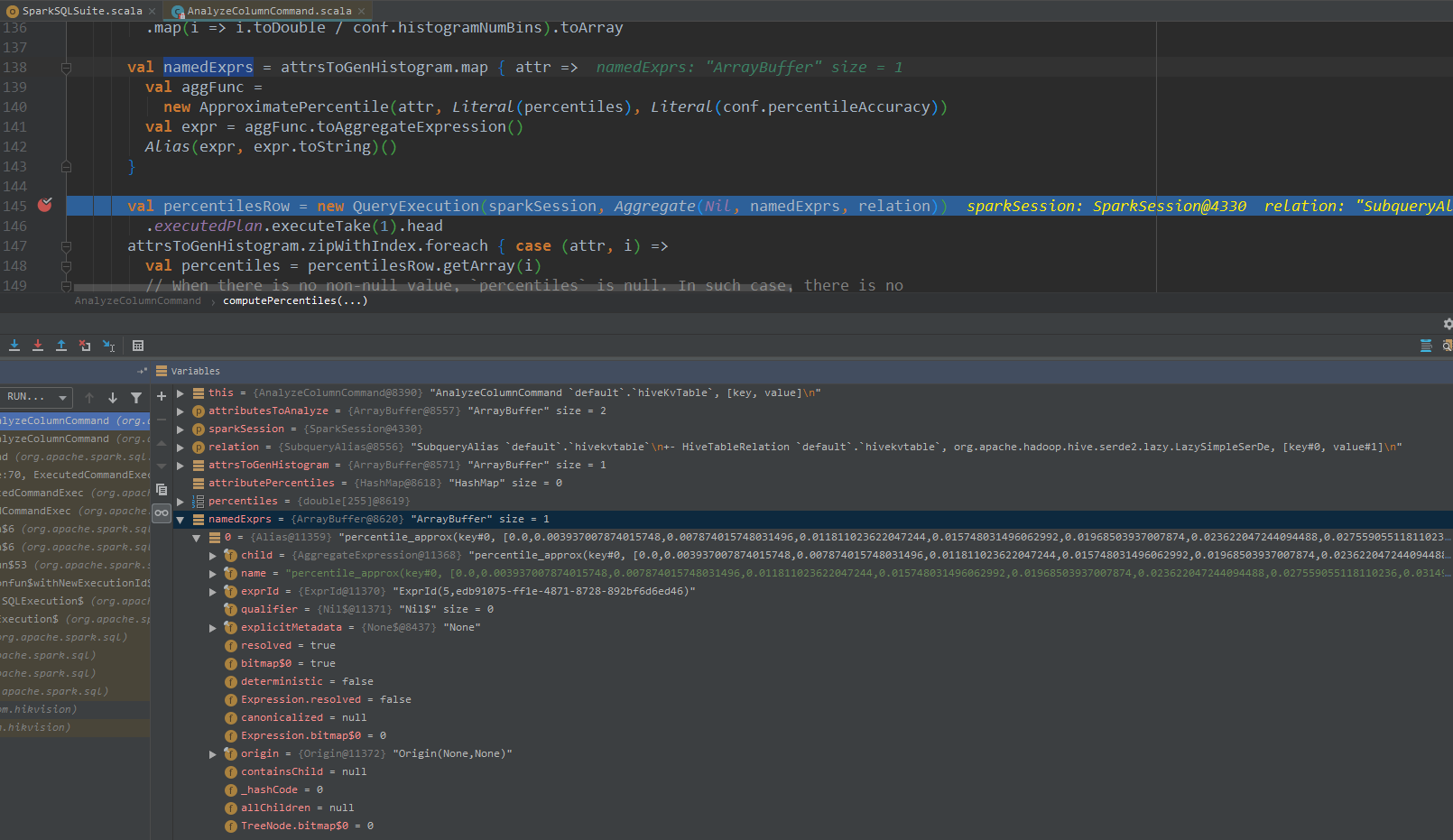
进入该方法,首先会进行直方图统计,构建出namedExprs 聚合表达式数组后,进行聚合计算,计算出各个指标,调用statExprs方法,结构化统计数据
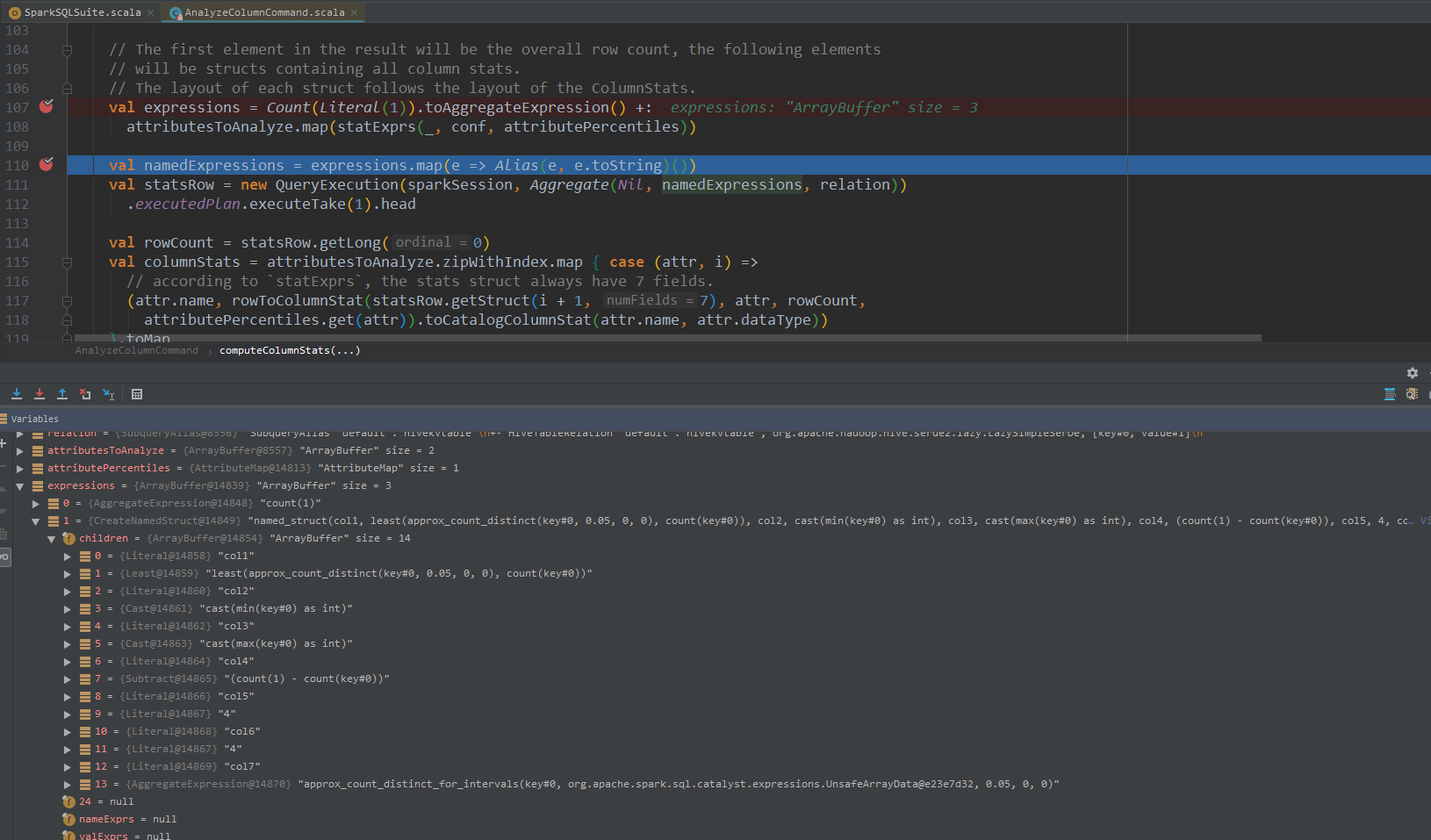
可以看到针对count distinct的计算,Spark SQL这里使用的近似计算least(approx_count_distinct(key#0, 0.05, 0, 0), count(key#0))
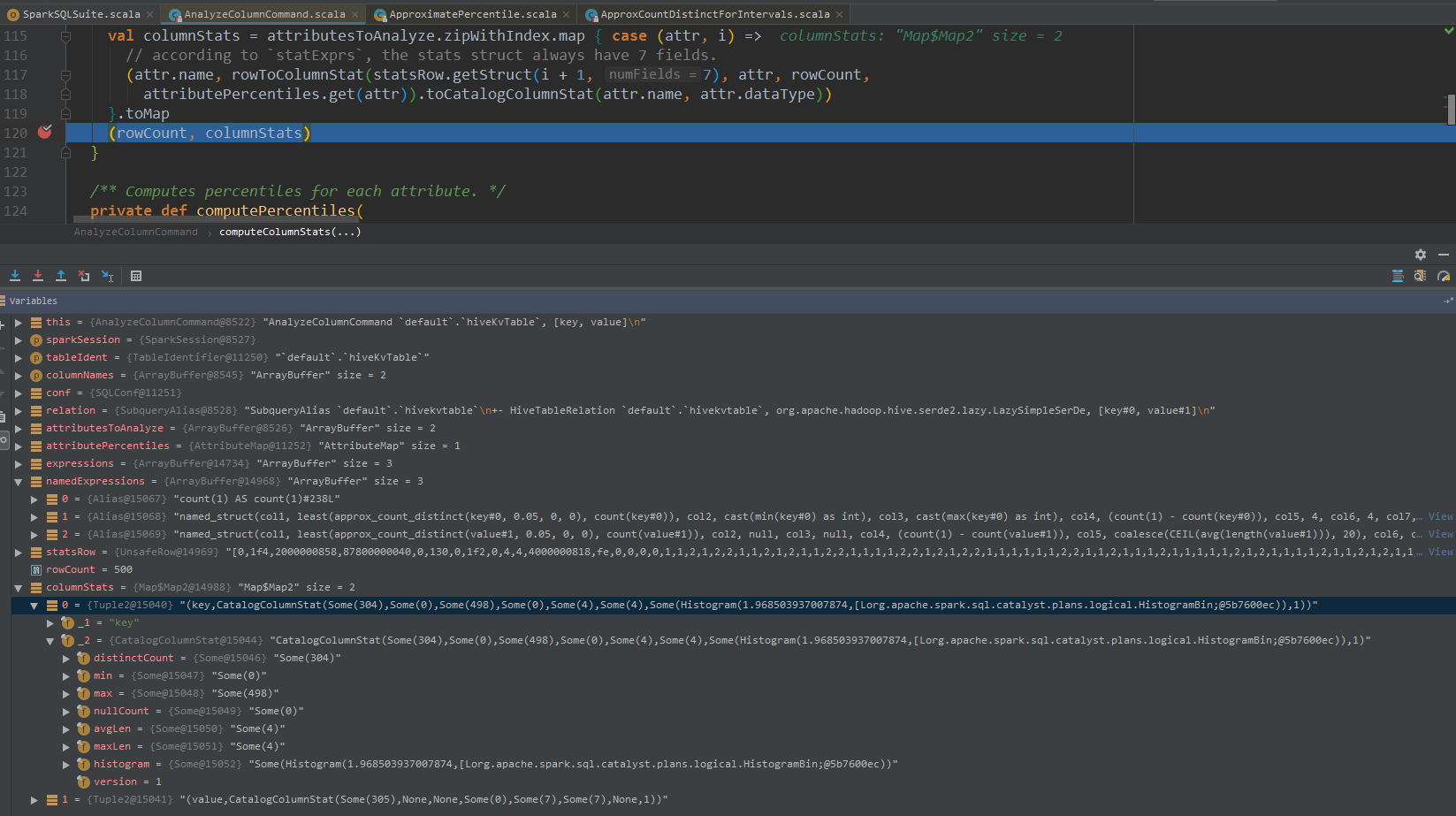
最后得到CBO列统计信息:
6. show tables sql语句分析
show tables分析
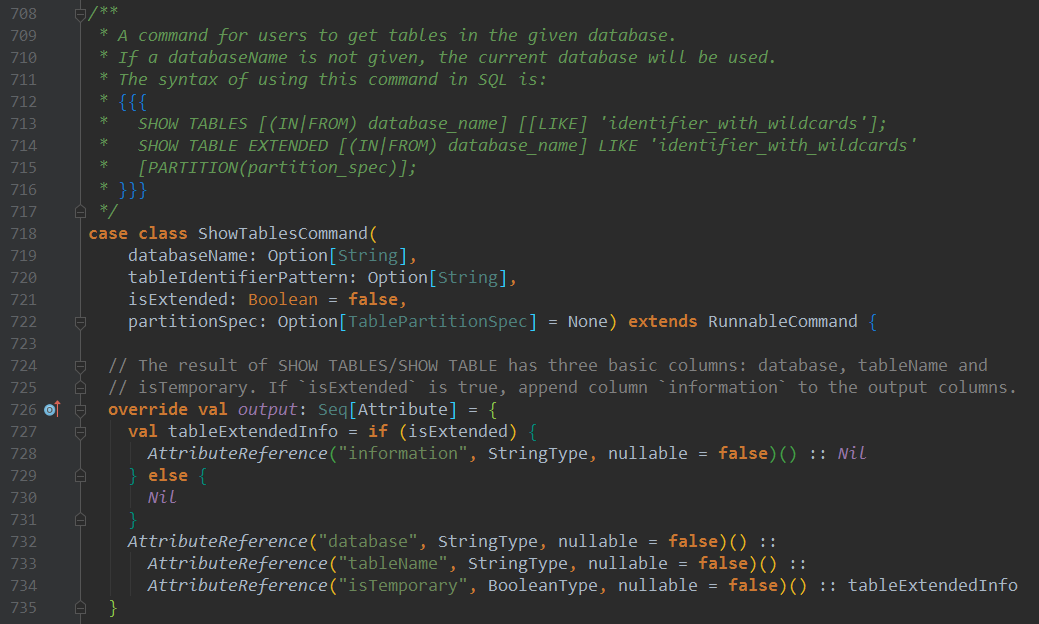
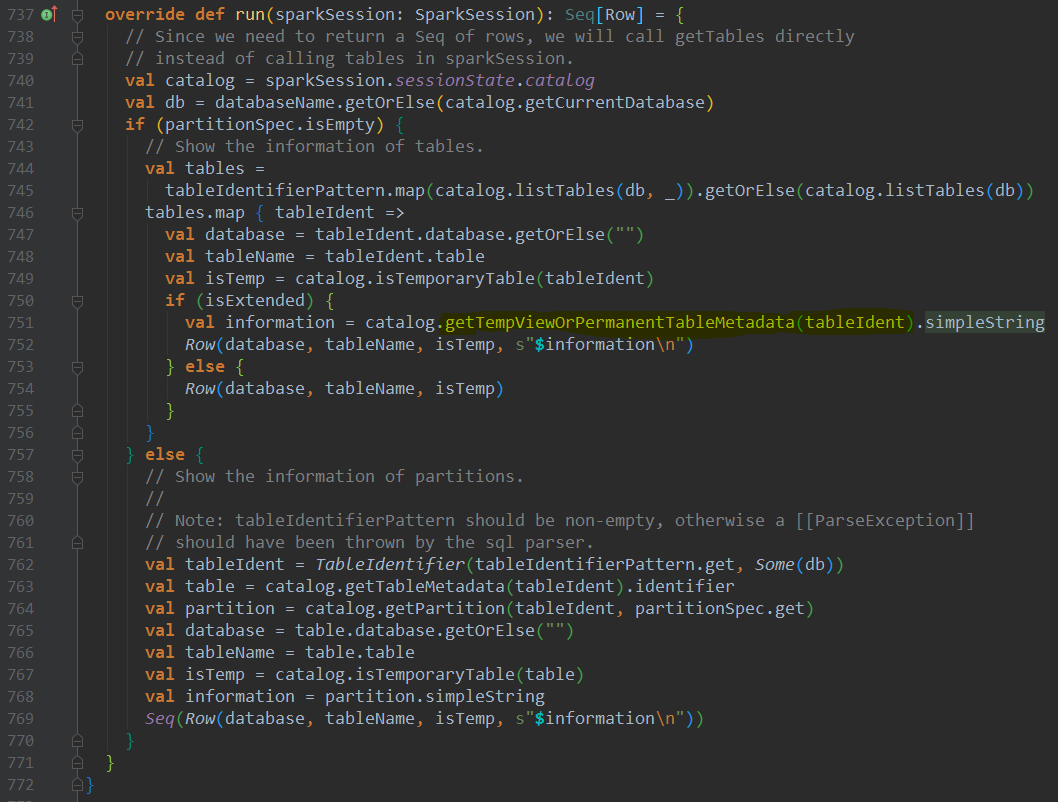
其本质是调用getTempViewOrPermanentTableMetadata方法
对于TempView,临时构建CatalogTable返回,对于永久表,则通过getTableMetadata方法获取CatalogTable(和Spark SQL CBO模块获取元数据逻辑一样)
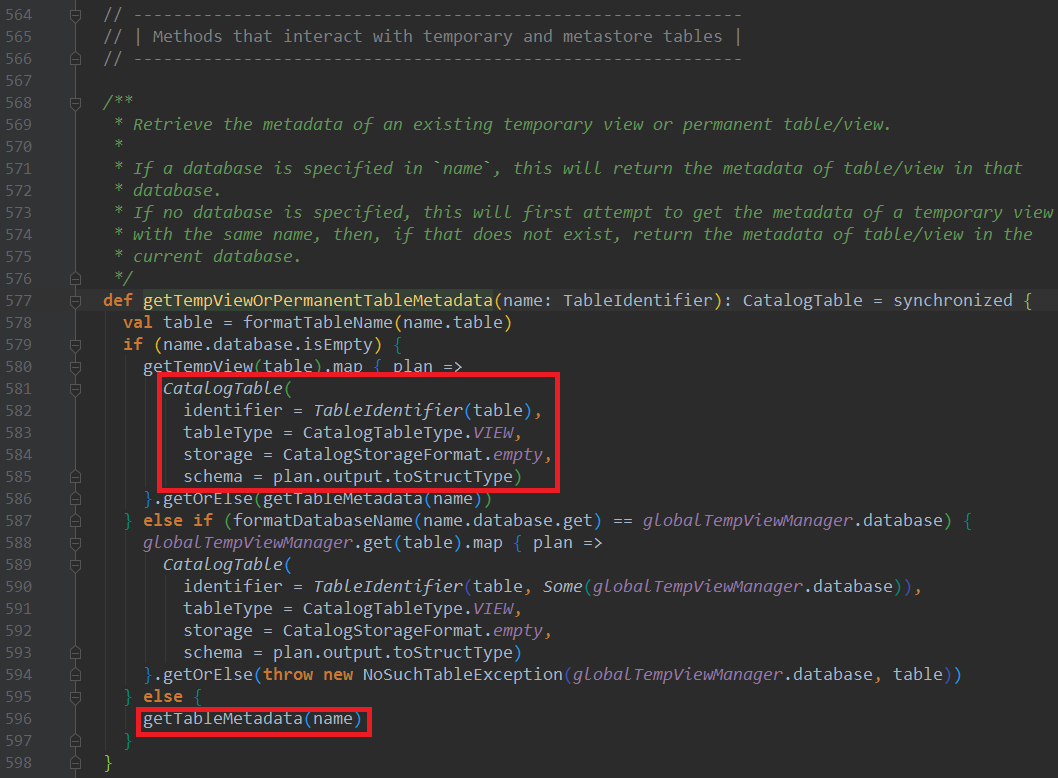
7. 结语
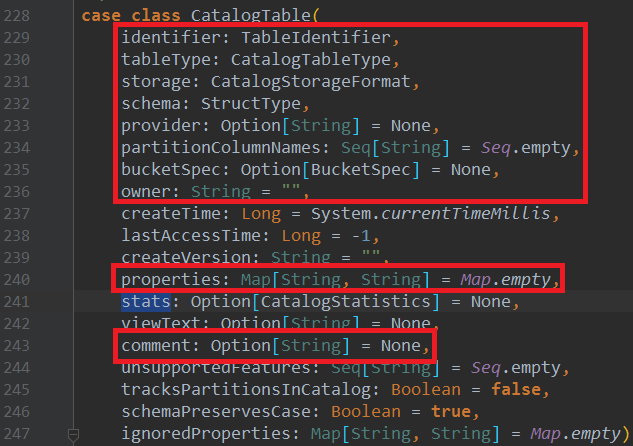
目前Spark SQL的元数据结构是CatalogTable,并且建表的时候注入的参数是红框部分,这里stats参数保存的是CBO统计信息CatalogStatistics对象,仅在执行AnalyzeTableCommand、AnalyzeColumnCommand两个模块对应sql的CBO统计任务后调用sessionState.catalog.alterTableStats(tableIdentWithDB, Some(statistics))方法才会进行更新
如果不想借助hive metastore存储CBO统计信息以及Spark CBO那两个sql语句进行统计,咱们可以自己实现统计信息计算,并存储到对应的数据库中,例如mysql,pg(可使用调用sql的方式计算)。然后在SparkSQL分析阶段,从数据库中拉取对应LogicalRelation阶段对象的统计信息构建CatalogTable,并调用copy方法,把这个CatalogTable注入到LogicalRelation并返回即可。