java常用排序算法有:冒泡排序、插入排序、归并排序和基数排序、选择排序、快速排序、希尔排序、堆排序、树 等。
一、稳定性:
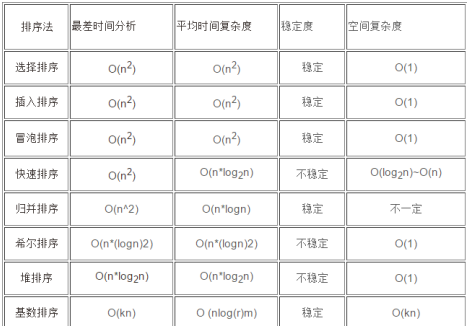
稳定:冒泡排序、插入排序、归并排序和基数排序
不稳定:选择排序、快速排序、希尔排序、堆排序
二、平均时间复杂度
O(n^2):直接插入排序,简单选择排序,冒泡排序。
在数据规模较小时(9W内),直接插入排序,简单选择排序差不多。当数据较大时,冒泡排序算法的时间代价最高。性能为O(n^2)的算法基本上是相邻元素进行比较,基本上都是稳定的。
O(nlogn):快速排序,归并排序,希尔排序,堆排序。
其中,快排是最好的, 其次是归并和希尔,堆排序在数据量很大时效果明显。
三、排序算法的选择
1、数据规模较小
(1)待排序列基本序的情况下,可以选择直接插入排序;
(2)对稳定性不作要求宜用简单选择排序,对稳定性有要求宜用插入或冒泡
2、数据规模不是很大
(1)完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
(2)序列本身可能有序,对稳定性有要求,空间允许下,宜用归并排序
3、数据规模很大
(1)对稳定性有求,则可考虑归并排序。
(2)对稳定性没要求,宜用堆排序
4、序列初始基本有序(正序),宜用直接插入,冒泡
各算法复杂度如下:
1 去重
1、1 去重
//去重复,需要额外定义一个List
public static void RemoveRepeat(List<Integer> arrs) {
List<Integer> tmp = new ArrayList<Integer>();
Iterator<Integer> it = arrs.iterator();
while (it.hasNext()) {
int a = it.next();
if (tmp.contains(a))
it.remove();
else
tmp.add(a);
}
}
1、2 去不重
// 去不重复的数,用的是选择排序算法变化版
public static void RemoveNoRepeat(List<Integer> arrs) {
Boolean isRepeate = false;
for (int i = 0; i < arrs.size(); i++) {
isRepeate = false;
for (int j = 0; j < arrs.size(); j++) {
if (arrs.get(i) == arrs.get(j) && i != j) {
isRepeate = true;
break;
}
}
if (!isRepeate) {
arrs.remove(i);
i--;
}
}
}
public static void RemoveNoRepeatImprove(List<Integer> arrs) {
Boolean isRepeate = false;
for (int i = arrs.size() - 1; i >= 0; i--) {
isRepeate = false;
for (int j = arrs.size() - 1; j >= 0; j--) {
if (arrs.get(i) == arrs.get(j) && i != j) {
isRepeate = true;
break;
}
}
if (!isRepeate) {
arrs.remove(i);
}
}
}
public static void RemoveNoRepeatWithExtraMap(List<Integer> arrs) {
Map<Integer, Integer> repeat = CountRepeat(arrs);
for (int i = arrs.size() - 1; i >= 0; i--) {
if (repeat.get(arrs.get(i)) == 1) {
arrs.remove(i);
}
}
}
// 统计重复数
public static Map<Integer, Integer> CountRepeat(List<Integer> arrs) {
Map<Integer, Integer> map = new HashMap<Integer, Integer>();
Integer value = 0;
for (Integer arr : arrs) {
if (map.containsKey(arr)) {
value = map.get(arr);
map.put(arr, value + 1);
} else {
map.put(arr, 1);
}
}
return map;
}
2 随机分配
public static Map<String, String> TicketDispatch(List<String> customers, List<String> tickets) {
Map<String, String> result = new HashMap<String, String>();
Random r = new Random();
int iCustomer;
int iTicket;
for (int i = customers.size(); i > 0; i--) {
// 取值范围[0,i)
iCustomer = r.nextInt(i);
iTicket = r.nextInt(tickets.size());
result.put(customers.get(iCustomer), tickets.get(iTicket));
customers.remove(iCustomer);
tickets.remove(iTicket);
}
return result;
}
3 递归
递归排序
public void mergeSort(int[] a, int left, int right) {
int t = 1;// 每组元素个数
int size = right - left + 1;
while (t < size) {
int s = t;// 本次循环每组元素个数
t = 2 * s;
int i = left;
while (i + (t - 1) < size) {
merge(a, i, i + (s - 1), i + (t - 1));
i += t;
}
if (i + (s - 1) < right)
merge(a, i, i + (s - 1), right);
}
}
private static void merge(int[] data, int p, int q, int r) {
int[] B = new int[data.length];
int s = p;
int t = q + 1;
int k = p;
while (s <= q && t <= r) {
if (data[s] <= data[t]) {
B[k] = data[s];
s++;
} else {
B[k] = data[t];
t++;
}
k++;
}
if (s == q + 1)
B[k++] = data[t++];
else
B[k++] = data[s++];
for (int i = p; i <= r; i++)
data[i] = B[i];
}
//Java递归删除一个目录下文件和文件夹
private static void deleteDir(File dir) {
if (dir.isDirectory()) {
String[] children = dir.list();
// 递归删除目录中的子目录下
for (int i=0; i<children.length; i++) {
deleteDir(new File(dir, children[i]));
}
}
dir.delete();
}
3个月起每个月都生一对兔子,小兔子长到第三个月后每个月又生一对兔子,假如兔子都不死,问每个月的兔子总数为多少?
分析:首先我们要明白题目的意思指的是每个月的兔子总对数;假设将兔子分为小中大三种,兔子从出生后三个月后每个月就会生出一对兔子,
那么我们假定第一个月的兔子为小兔子,第二个月为中兔子,第三个月之后就为大兔子,那么第一个月分别有1、0、0,第二个月分别为0、1、0,
第三个月分别为1、0、1,第四个月分别为,1、1、1,第五个月分别为2、1、2,第六个月分别为3、2、3,第七个月分别为5、3、5……
兔子总数分别为:1、1、2、3、5、8、13……
于是得出了一个规律,从第三个月起,后面的兔子总数都等于前面两个月的兔子总数之和,即为斐波那契数列。
public class Test {
public static void main(String[] args) {
int i = 1;
for (i = 1; i <= 20; i++) {
System.out.println("兔子第" + i + "个月的总数为:" + f(i));
}
}
public static int f(int x) {
if (x == 1 || x == 2) {
return 1;
} else {
return f(x - 1) + f(x - 2);
}
}
}
从1到100相加
public class Digui {
public int sum(int i) {
if (i == 1) {
return 1;
}
return i + sum(i - 1);
}
public static void main(String[] args) {
Digui test = new Digui();
System.out.println("计算结果:" + test.sum(100) + "!");
}
}
从1到n阶乘
需要注意的是计算后的结果数值过大程序无法返回,一般情况会返回0!那么用int、long 是无法满足的, 所以要用BigInteger
public class Digui {
public BigInteger sum(int i) {
if (i == 1) {
return BigInteger.ONE;
}
return BigInteger.valueOf(i).multiply(sum(i - 1));
}
public static void main(String[] args) {
Digui test = new Digui();
try {
System.out.println("计算结果:" + test.sum(50) + "!");
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
4 内部排序变形
4、1 取数组中未出现的最小整数
public static Integer GetNotExitMinInteger(Integer[] arr){
Integer minIndex;
Integer tmp;
Integer first=0;
for(int i=0;i<arr.length;i++){
minIndex=i;
for(int j=i+1;j<arr.length;j++){
if(arr[minIndex]>arr[j])
minIndex=j;
}
if(arr[minIndex]-first>1)
return arr[minIndex]-1;
}else{
first=arr[minIndex];
}
if(minIndex!=i){
tmp=arr[i];
arr[i]=arr[minIndex];
arr[minIndex]=tmp;
}
}
return arr[arr.length-1]+1;
}
上面问题其他解决方案:
也可先排序(快速排序,若范围可确定,且不到,可用桶排序),在先后比较arr[next]-arr[one]>1
5 字符串
5、1 全排序
思路:
n个字符
前n-1个固定,第n个,不能再互换,打印排列
前n-2个固定,第n-1个和n位置互换,得到排列
前n-3个固定,第n-2个分别和最后两个位置互换
…
public class FullPermutation {
public static void main(String[] args){
char[] arr=new char[]{'A','B','C','D'};
Permutatition(arr);
}
public static void Permutatition(char[] arr){
recursivePermutation(arr,0,arr.length-1);
}
private static void recursivePermutation(char[] arr,int start,int end){
if(start==end){
for (int i = 0; i <= end; i++)
System.out.print(arr[i]);
System.out.println();
}else {
for (int i = start; i <= end; i++) {
swap(arr, start, i);
recursivePermutation(arr, start+1, end);
swap(arr, start, i);
}
}
}
private static void swap(char[] arr,int left,int right){
char tmp=arr[left];
arr[left]=arr[right];
arr[right]=tmp;
}
}
5、2 找最大回文
回文:正读,倒读一样
样例:abcdedcba,abcddcba
思路:中心点,看两边是否对应
public static String longestPalindrome(String str){
if(str==null||str.length()==0)
return "";
int max=0,current=0,length=str.length();
String subString="";
for(int i=0;i<length;i++){
//考虑回文字段为奇数长度
for(int j=0;i-j>=0&&i+j<length;j++){
if(str.charAt(i-j)!=str.charAt(i+j))
break;
current=j*2+1;
}
if(current>max){
max=current;
subString=str.substring(i-max/2,i+max/2+1);
}
//考虑回文字段为偶数长度
for(int j=0;i-j>=0&&i+j+1<length;j++){
if(str.charAt(i-j)!=str.charAt(i+j+1))
break;
current=j*2+2;
}
if(current>max){
max=current;
subString=str.substring(i-max/2+1,i+max/2+1);
}
}
return subString;
}
5、3 字符串转换为数字
//字符串转换为数字
public static int toInt(String str){
if(str==null&&str.length()==0)
throw new RuntimeException("字符串为空");
//转换结果
int result=0;
//要转换的字符
int current=0;
//整数的正负
char sign='+';
if(str.charAt(0)=='-'||str.charAt(0)=='+'){
sign=str.charAt(0);
str=str.substring(1);
}
//是否需要判断
boolean judgeOverflow=true;
if(str.length()>10){
throw new RuntimeException("整形溢出了");
}else if(str.length()<10){
judgeOverflow=false;
}
for(int i=0;i<str.length();i++){
current=str.charAt(i)-'0';
if(current>9||current<0)
throw new RuntimeException("包含非整数型字符");
if(judgeOverflow){
if(sign=='+'&¤t>Integer.MAX_VALUE/(int)Math.pow(10,9-i)%10){
throw new RuntimeException("整形溢出了");
}
if(sign=='-'&¤t>Integer.MIN_VALUE/(int)Math.pow(10,9-i)%10){
throw new RuntimeException("整形溢出了");
}
}
result=result*10+current;
}
if(sign=='-'){
result=-result;
}
return result;
}
5、4 和为指定值的两个数
1 先排序,后加
2 用哈希表,key为数的值,value为位置。这样,hashMap.get(sum-arr[i]),O(1)定位
public class TwoSum {
public static void main(String[] args){
int[] arr=new int[]{7,8,5,4,1,2,3,6,9};
findByHash(arr,10);
int[] arr2=new int[]{1,2,3,4,5,6,7,8,9};
find(arr2,10);
}
public static void find(int[] arr,int sum){
//arr 这里arr是排好序的了
int begin=0;
int end=arr.length-1;
while(begin<end){
if(arr[begin]+arr[end]==sum) {
System.out.println(String.format(("[%d,%d]"), arr[begin], arr[end]));
begin++;
}
else if(arr[begin]+arr[end]>0)end--;
else begin++;
}
}
public static void findByHash(int[] arr, int sum){
Hashtable<Integer,Integer> hashMap=new Hashtable<>();
for(int i=0;i<arr.length;i++){
hashMap.put(arr[i],i);
}
for(int i=0;i<arr.length;i++){
int index=hashMap.get(sum-arr[i]);
if(index!=-1&&index>i) {
System.out.println(String.format(("[%d,%d]"), arr[i], arr[index]));
}
}
}
}
直接插入排序
public void insertSort(int[] a) {
int len = a.length;//单独把数组长度拿出来,提高效率
int insertNum;//要插入的数
for (int i = 1; i < len; i++) {//因为第一次不用,所以从1开始
insertNum = a[i];
int j = i - 1;//序列元素个数
while (j >= 0 && a[j] > insertNum) {//从后往前循环,将大于insertNum的数向后移动
a[j + 1] = a[j];//元素向后移动
j--;
}
a[j + 1] = insertNum;//找到位置,插入当前元素
}
}
希尔排序
public void sheelSort(int [] a){
int len=a.length;//单独把数组长度拿出来,提高效率
while(len!=0){
len=len/2;
for(int i=0;i<len;i++){//分组
for(int j=i+len;j<a.length;j+=len){//元素从第二个开始
int k=j-len;//k为有序序列最后一位的位数
int temp=a[j];//要插入的元素
while(k>=0&&temp<a[k]){//从后往前遍历
a[k+len]=a[k];
k-=len;//向后移动len位
}
a[k+len]=temp;
}
}
}
}
简单选择排序
public void selectSort(int[]a){
int len=a.length;
for(int i=0;i<len;i++){//循环次数
int value=a[i];
int position=i;
for(int j=i+1;j<len;j++){//找到最小的值和位置
if(a[j]<value){
value=a[j];
position=j;
}
}
a[position]=a[i];//进行交换
a[i]=value;
}
}
堆排序
public void heapSort(int[] a){
int len=a.length;
//循环建堆
for(int i=0;i<len-1;i++){
//建堆
buildMaxHeap(a,len-1-i);
//交换堆顶和最后一个元素
swap(a,0,len-1-i);
}
}
//交换方法
private void swap(int[] data, int i, int j) {
int tmp=data[i];
data[i]=data[j];
data[j]=tmp;
}
//对data数组从0到lastIndex建大顶堆
private void buildMaxHeap(int[] data, int lastIndex) {
//从lastIndex处节点(最后一个节点)的父节点开始
for(int i=(lastIndex-1)/2;i>=0;i--){
//k保存正在判断的节点
int k=i;
//如果当前k节点的子节点存在
while(k*2+1<=lastIndex){
//k节点的左子节点的索引
int biggerIndex=2*k+1;
//如果biggerIndex小于lastIndex,即biggerIndex+1代表的k节点的右子节点存在
if(biggerIndex<lastIndex){
//若果右子节点的值较大
if(data[biggerIndex]<data[biggerIndex+1]){
//biggerIndex总是记录较大子节点的索引
biggerIndex++;
}
}
//如果k节点的值小于其较大的子节点的值
if(data[k]<data[biggerIndex]){
//交换他们
swap(data,k,biggerIndex);
//将biggerIndex赋予k,开始while循环的下一次循环,重新保证k节点的值大于其左右子节点的值
k=biggerIndex;
}else{
break;
}
}
}
}
冒泡排序
public void bubbleSort(int []a){
int len=a.length;
for(int i=0;i<len;i++){
for(int j=0;j<len-i-1;j++){//注意第二重循环的条件
if(a[j]>a[j+1]){
int temp=a[j];
a[j]=a[j+1];
a[j+1]=temp;
}
}
}
}
快速排序
public void quickSort(int[]a,int start,int end){
if(start<end){
int baseNum=a[start];//选基准值
int midNum;//记录中间值
int i=start;
int j=end;
do{
while((a[i]<baseNum)&&i<end){
i++;
}
while((a[j]>baseNum)&&j>start){
j--;
}
if(i<=j){
midNum=a[i];
a[i]=a[j];
a[j]=midNum;
i++;
j--;
}
}while(i<=j);
if(start<j){
quickSort(a,start,j);
}
if(end>i){
quickSort(a,i,end);
}
}
}
二叉树
树的常用术语
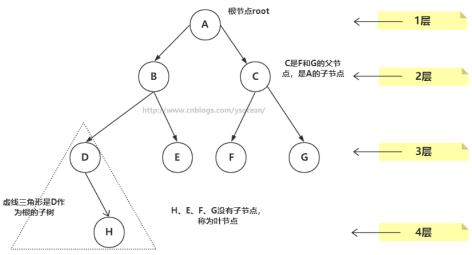
①、路径:顺着节点的边从一个节点走到另一个节点,所经过的节点的顺序排列就称为“路径”。
②、根:树顶端的节点称为根。一棵树只有一个根,如果要把一个节点和边的集合称为树,那么从根到其他任何一个节点都必须有且只有一条路径。A是根节点。
③、父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;B是D的父节点。
④、子节点:一个节点含有的子树的根节点称为该节点的子节点;D是B的子节点。
⑤、兄弟节点:具有相同父节点的节点互称为兄弟节点;比如上图的D和E就互称为兄弟节点。
⑥、叶节点:没有子节点的节点称为叶节点,也叫叶子节点,比如上图的H、E、F、G都是叶子节点。
⑦、子树:每个节点都可以作为子树的根,它和它所有的子节点、子节点的子节点等都包含在子树中。
⑧、节点的层次:从根开始定义,根为第一层,根的子节点为第二层,以此类推。
⑨、深度:对于任意节点n,n的深度为从根到n的唯一路径长,根的深度为0;
⑩、高度:对于任意节点n,n的高度为从n到一片树叶的最长路径长,所有树叶的高度为0;
二叉树:树的每个节点最多只能有两个子节点
上图的第一幅图B节点有DEF三个子节点,就不是二叉树,称为多路树;而第二幅图每个节点最多只有两个节点,是二叉树,并且二叉树的子节点称为“左子节点”和“右子节点”。上图的D,E分别是B的左子节点和右子节点。
如果我们给二叉树加一个额外的条件,就可以得到一种被称作二叉搜索树(binary search tree)的特殊二叉树。
二叉搜索树要求:若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 它的左、右子树也分别为二叉排序树。
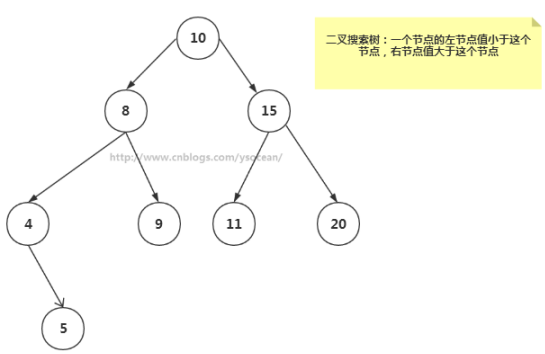
二叉搜索树作为一种数据结构,那么它是如何工作的呢?它查找一个节点,插入一个新节点,以及删除一个节点,遍历树等工作效率如何,下面我们来一一介绍。
二叉树的节点类:
public class Node {
private Object data; //节点数据
private Node leftChild; //左子节点的引用
private Node rightChild; //右子节点的引用
//打印节点内容
public void display(){
System.out.println(data);
}
}
二叉树的具体方法:
public interface Tree {
//查找节点
public Node find(Object key);
//插入新节点
public boolean insert(Object key);
//删除节点
public boolean delete(Object key);
//Other Method......
}
查找某个节点,我们必须从根节点开始遍历。
查找值比当前节点值大,则搜索右子树;
查找值等于当前节点值,停止搜索(终止条件);
查找值小于当前节点值,则搜索左子树;
//查找节点
public Node find(int key) {
Node current = root;
while(current != null){
if(current.data > key){//当前值比查找值大,搜索左子树
current = current.leftChild;
}else if(current.data < key){//当前值比查找值小,搜索右子树
current = current.rightChild;
}else{
return current;
}
}
return null;//遍历完整个树没找到,返回null
}
用变量current来保存当前查找的节点,参数key是要查找的值,刚开始查找将根节点赋值到current。接在在while循环中,将要查找的值和current保存的节点进行对比。如果key小于当前节点,则搜索当前节点的左子节点,如果大于,则搜索右子节点,如果等于,则直接返回节点信息。当整个树遍历完全,即current == null,那么说明没找到查找值,返回null。
树的效率:查找节点的时间取决于这个节点所在的层数,每一层最多有2n-1个节点,总共N层共有2n-1个节点,那么时间复杂度为O(logN),底数为2。
我看评论有对这里的时间复杂度不理解,这里解释一下,O(logN),N表示的是二叉树节点的总数,而不是层数。
要插入节点,必须先找到插入的位置。与查找操作相似,由于二叉搜索树的特殊性,待插入的节点也需要从根节点开始进行比较,小于根节点则与根节点左子树比较,反之则与右子树比较,直到左子树为空或右子树为空,则插入到相应为空的位置,在比较的过程中要注意保存父节点的信息 及 待插入的位置是父节点的左子树还是右子树,才能插入到正确的位置。
//插入节点
public boolean insert(int data) {
Node newNode = new Node(data);
if(root == null){//当前树为空树,没有任何节点
root = newNode;
return true;
}else{
Node current = root;
Node parentNode = null;
while(current != null){
parentNode = current;
if(current.data > data){//当前值比插入值大,搜索左子节点
current = current.leftChild;
if(current == null){//左子节点为空,直接将新值插入到该节点
parentNode.leftChild = newNode;
return true;
}
}else{
current = current.rightChild;
if(current == null){//右子节点为空,直接将新值插入到该节点
parentNode.rightChild = newNode;
return true;
}
}
}
}
return false;
}
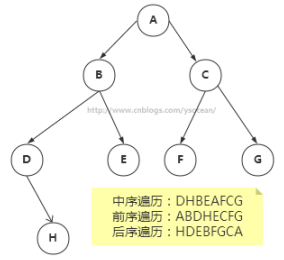
遍历树是根据一种特定的顺序访问树的每一个节点。比较常用的有前序遍历,中序遍历和后序遍历。而二叉搜索树最常用的是中序遍历。
中序遍历:左子树——》根节点——》右子树
前序遍历:根节点——》左子树——》右子树
后序遍历:左子树——》右子树——》根节点
//中序遍历
public void infixOrder(Node current){
if(current != null){
infixOrder(current.leftChild);
System.out.print(current.data+" ");
infixOrder(current.rightChild);
}
}
//前序遍历
public void preOrder(Node current){
if(current != null){
System.out.print(current.data+" ");
preOrder(current.leftChild);
preOrder(current.rightChild);
}
}
//后序遍历
public void postOrder(Node current){
if(current != null){
postOrder(current.leftChild);
postOrder(current.rightChild);
System.out.print(current.data+" ");
}
}
这没什么好说的,要找最小值,先找根的左节点,然后一直找这个左节点的左节点,直到找到没有左节点的节点,那么这个节点就是最小值。同理要找最大值,一直找根节点的右节点,直到没有右节点,则就是最大值。
//找到最大值
public Node findMax(){
Node current = root;
Node maxNode = current;
while(current != null){
maxNode = current;
current = current.rightChild;
}
return maxNode;
}
//找到最小值
public Node findMin(){
Node current = root;
Node minNode = current;
while(current != null){
minNode = current;
current = current.leftChild;
}
return minNode;
}
删除节点是二叉搜索树中最复杂的操作,删除的节点有三种情况,前两种比较简单,但是第三种却很复杂。
1、该节点是叶节点(没有子节点)
2、该节点有一个子节点
3、该节点有两个子节点
下面我们分别对这三种情况进行讲解。
删除没有子节点的节点
要删除叶节点,只需要改变该节点的父节点引用该节点的值,即将其引用改为 null 即可。要删除的节点依然存在,但是它已经不是树的一部分了,由于Java语言的垃圾回收机制,我们不需要非得把节点本身删掉,一旦Java意识到程序不在与该节点有关联,就会自动把它清理出存储器。
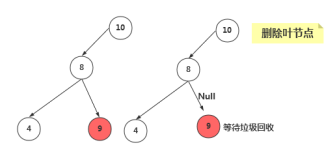
@Override
public boolean delete(int key) {
Node current = root;
Node parent = root;
boolean isLeftChild = false;
//查找删除值,找不到直接返回false
while(current.data != key){
parent = current;
if(current.data > key){
isLeftChild = true;
current = current.leftChild;
}else{
isLeftChild = false;
current = current.rightChild;
}
if(current == null){
return false;
}
}
//如果当前节点没有子节点
if(current.leftChild == null && current.rightChild == null){
if(current == root){
root = null;
}else if(isLeftChild){
parent.leftChild = null;
}else{
parent.rightChild = null;
}
return true;
}
return false;
}
删除节点,我们要先找到该节点,并记录该节点的父节点。在检查该节点是否有子节点。如果没有子节点,接着检查其是否是根节点,如果是根节点,只需要将其设置为null即可。如果不是根节点,是叶节点,那么断开父节点和其的关系即可。
删除有一个子节点的节点
删除有一个子节点的节点,我们只需要将其父节点原本指向该节点的引用,改为指向该节点的子节点即可。
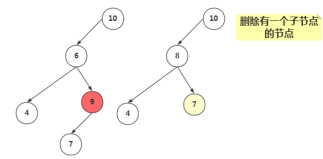
//当前节点有一个子节点
if(current.leftChild == null && current.rightChild != null){
if(current == root){
root = current.rightChild;
}else if(isLeftChild){
parent.leftChild = current.rightChild;
}else{
parent.rightChild = current.rightChild;
}
return true;
}else{
//current.leftChild != null && current.rightChild == null
if(current == root){
root = current.leftChild;
}else if(isLeftChild){
parent.leftChild = current.leftChild;
}else{
parent.rightChild = current.leftChild;
}
return true;
}
删除有两个子节点的节点
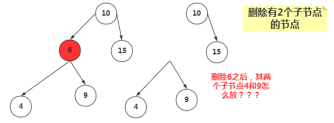
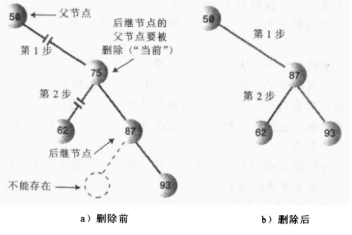
当删除的节点存在两个子节点,那么删除之后,两个子节点的位置我们就没办法处理了。既然处理不了,我们就想到一种办法,用另一个节点来代替被删除的节点,那么用哪一个节点来代替呢?
我们知道二叉搜索树中的节点是按照关键字来进行排列的,某个节点的关键字次高节点是它的中序遍历后继节点。用后继节点来代替删除的节点,显然该二叉搜索树还是有序的。(这里用后继节点代替,如果该后继节点自己也有子节点,我们后面讨论。)
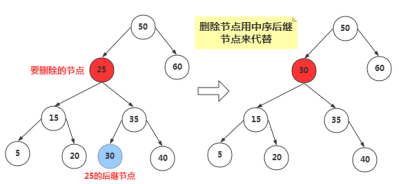
那么如何找到删除节点的中序后继节点呢?其实我们稍微分析,这实际上就是要找比删除节点关键值大的节点集合中最小的一个节点,只有这样代替删除节点后才能满足二叉搜索树的特性。
后继节点也就是:比删除节点大的最小节点。
算法:程序找到删除节点的右节点,(注意这里前提是删除节点存在左右两个子节点,如果不存在则是删除情况的前面两种),然后转到该右节点的左子节点,依次顺着左子节点找下去,最后一个左子节点即是后继节点;如果该右节点没有左子节点,那么该右节点便是后继节点。
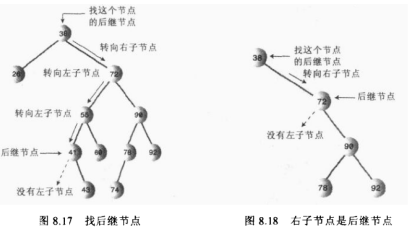
需要确定后继节点没有子节点,如果后继节点存在子节点,那么又要分情况讨论了。
①、后继节点是删除节点的右子节点
这种情况简单,只需要将后继节点表示的子树移到被删除节点的位置即可!
②、后继节点是删除节点的右子节点的左子节点
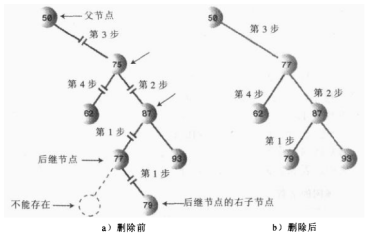
public Node getSuccessor(Node delNode){
Node successorParent = delNode;
Node successor = delNode;
Node current = delNode.rightChild;
while(current != null){
successorParent = successor;
successor = current;
current = current.leftChild;
}
//将后继节点替换删除节点
if(successor != delNode.rightChild){
successorParent.leftChild = successor.rightChild;
successor.rightChild = delNode.rightChild;
}
return successor;
}
删除有必要吗?
通过上面的删除分类讨论,我们发现删除其实是挺复杂的,那么其实我们可以不用真正的删除该节点,只需要在Node类中增加一个标识字段isDelete,当该字段为true时,表示该节点已经删除,反正没有删除。那么我们在做比如find()等操作的时候,要先判断isDelete字段是否为true。这样删除的节点并不会改变树的结构。
public class Node {
int data; //节点数据
Node leftChild; //左子节点的引用
Node rightChild; //右子节点的引用
boolean isDelete;//表示节点是否被删除
}
二叉树的效率
从前面的大部分对树的操作来看,都需要从根节点到下一层一层的查找。
一颗满树,每层节点数大概为2n-1,那么最底层的节点个数比树的其它节点数多1,因此,查找、插入或删除节点的操作大约有一半都需要找到底层的节点,另外四分之一的节点在倒数第二层,依次类推。
总共N层共有2n-1个节点,那么时间复杂度为O(logn),底数为2。
在有1000000 个数据项的无序数组和链表中,查找数据项平均会比较500000 次,但是在有1000000个节点的二叉树中,只需要20次或更少的比较即可。
有序数组可以很快的找到数据项,但是插入数据项的平均需要移动 500000 次数据项,在 1000000 个节点的二叉树中插入数据项需要20次或更少比较,在加上很短的时间来连接数据项。
同样,从 1000000 个数据项的数组中删除一个数据项平均需要移动 500000 个数据项,而在 1000000 个节点的二叉树中删除节点只需要20次或更少的次数来找到他,然后在花一点时间来找到它的后继节点,一点时间来断开节点以及连接后继节点。
所以,树对所有常用数据结构的操作都有很高的效率。
遍历可能不如其他操作快,但是在大型数据库中,遍历是很少使用的操作,它更常用于程序中的辅助算法来解析算术或其它表达式。
用数组表示树
用数组表示树,那么节点是存在数组中的,节点在数组中的位置对应于它在树中的位置。下标为 0 的节点是根,下标为 1 的节点是根的左子节点,以此类推,按照从左到右的顺序存储树的每一层。
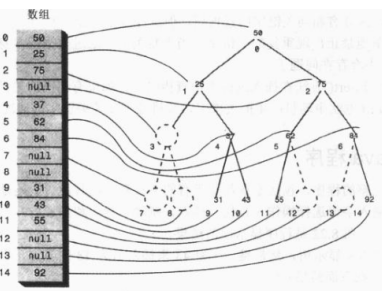
树中的每个位置,无论是否存在节点,都对应于数组中的一个位置,树中没有节点的在数组中用0或者null表示。
假设节点的索引值为index,那么节点的左子节点是 2*index+1,节点的右子节点是 2*index+2,它的父节点是 (index-1)/2。
在大多数情况下,使用数组表示树效率是很低的,不满的节点和删除掉的节点都会在数组中留下洞,浪费存储空间。更坏的是,删除节点如果要移动子树的话,子树中的每个节点都要移到数组中新的位置,这是很费时的。
不过如果不允许删除操作,数组表示可能会很有用,尤其是因为某种原因要动态的为每个字节分配空间非常耗时。
BinaryTree代码
Node.java
public class Node {
int data; //节点数据
Node leftChild; //左子节点的引用
Node rightChild; //右子节点的引用
boolean isDelete;//表示节点是否被删除
public Node(int data){
this.data = data;
}
//打印节点内容
public void display(){
System.out.println(data);
}
}
Tree.java
public interface Tree {
//查找节点
public Node find(int key);
//插入新节点
public boolean insert(int data);
//中序遍历
public void infixOrder(Node current);
//前序遍历
public void preOrder(Node current);
//后序遍历
public void postOrder(Node current);
//查找最大值
public Node findMax();
//查找最小值
public Node findMin();
//删除节点
public boolean delete(int key);
//Other Method......
}
BinaryTree.java
public class BinaryTree implements Tree {
//表示根节点
private Node root;
//查找节点
public Node find(int key) {
Node current = root;
while(current != null){
if(current.data > key){//当前值比查找值大,搜索左子树
current = current.leftChild;
}else if(current.data < key){//当前值比查找值小,搜索右子树
current = current.rightChild;
}else{
return current;
}
}
return null;//遍历完整个树没找到,返回null
}
//插入节点
public boolean insert(int data) {
Node newNode = new Node(data);
if(root == null){//当前树为空树,没有任何节点
root = newNode;
return true;
}else{
Node current = root;
Node parentNode = null;
while(current != null){
parentNode = current;
if(current.data > data){//当前值比插入值大,搜索左子节点
current = current.leftChild;
if(current == null){//左子节点为空,直接将新值插入到该节点
parentNode.leftChild = newNode;
return true;
}
}else{
current = current.rightChild;
if(current == null){//右子节点为空,直接将新值插入到该节点
parentNode.rightChild = newNode;
return true;
}
}
}
}
return false;
}
//中序遍历
public void infixOrder(Node current){
if(current != null){
infixOrder(current.leftChild);
System.out.print(current.data+" ");
infixOrder(current.rightChild);
}
}
//前序遍历
public void preOrder(Node current){
if(current != null){
System.out.print(current.data+" ");
infixOrder(current.leftChild);
infixOrder(current.rightChild);
}
}
//后序遍历
public void postOrder(Node current){
if(current != null){
infixOrder(current.leftChild);
infixOrder(current.rightChild);
System.out.print(current.data+" ");
}
}
//找到最大值
public Node findMax(){
Node current = root;
Node maxNode = current;
while(current != null){
maxNode = current;
current = current.rightChild;
}
return maxNode;
}
//找到最小值
public Node findMin(){
Node current = root;
Node minNode = current;
while(current != null){
minNode = current;
current = current.leftChild;
}
return minNode;
}
@Override
public boolean delete(int key) {
Node current = root;
Node parent = root;
boolean isLeftChild = false;
//查找删除值,找不到直接返回false
while(current.data != key){
parent = current;
if(current.data > key){
isLeftChild = true;
current = current.leftChild;
}else{
isLeftChild = false;
current = current.rightChild;
}
if(current == null){
return false;
}
}
//如果当前节点没有子节点
if(current.leftChild == null && current.rightChild == null){
if(current == root){
root = null;
}else if(isLeftChild){
parent.leftChild = null;
}else{
parent.rightChild = null;
}
return true;
//当前节点有一个子节点,右子节点
}else if(current.leftChild == null && current.rightChild != null){
if(current == root){
root = current.rightChild;
}else if(isLeftChild){
parent.leftChild = current.rightChild;
}else{
parent.rightChild = current.rightChild;
}
return true;
//当前节点有一个子节点,左子节点
}else if(current.leftChild != null && current.rightChild == null){
if(current == root){
root = current.leftChild;
}else if(isLeftChild){
parent.leftChild = current.leftChild;
}else{
parent.rightChild = current.leftChild;
}
return true;
}else{
//当前节点存在两个子节点
Node successor = getSuccessor(current);
if(current == root){
root= successor;
}else if(isLeftChild){
parent.leftChild = successor;
}else{
parent.rightChild = successor;
}
successor.leftChild = current.leftChild;
}
return false;
}
public Node getSuccessor(Node delNode){
Node successorParent = delNode;
Node successor = delNode;
Node current = delNode.rightChild;
while(current != null){
successorParent = successor;
successor = current;
current = current.leftChild;
}
//后继节点不是删除节点的右子节点,将后继节点替换删除节点
if(successor != delNode.rightChild){
successorParent.leftChild = successor.rightChild;
successor.rightChild = delNode.rightChild;
}
return successor;
}
public static void main(String[] args) {
BinaryTree bt = new BinaryTree();
bt.insert(50);
bt.insert(20);
bt.insert(80);
bt.insert(10);
bt.insert(30);
bt.insert(60);
bt.insert(90);
bt.insert(25);
bt.insert(85);
bt.insert(100);
bt.delete(10);//删除没有子节点的节点
bt.delete(30);//删除有一个子节点的节点
bt.delete(80);//删除有两个子节点的节点
System.out.println(bt.findMax().data);
System.out.println(bt.findMin().data);
System.out.println(bt.find(100));
System.out.println(bt.find(200));
}
}
哈夫曼(Huffman)编码
我们知道计算机里每个字符在没有压缩的文本文件中由一个字节(比如ASCII码)或两个字节(比如Unicode,这个编码在各种语言中通用)表示,在这些方案中,每个字符需要相同的位数。
有很多压缩数据的方法,就是减少表示最常用字符的位数量,比如英语中,E是最常用的字母,我们可以只用两位01来表示,2位有四种组合:00、01、10、11,那么我们可以用这四种组合表示四种常用的字符吗?
答案是不可以的,因为在编码序列中是没有空格或其他特殊字符存在的,全都是有0和1构成的序列,比如E用01来表示,X用01011000表示,那么在解码的时候就弄不清楚01是表示E还是表示X的起始部分,所以在编码的时候就定下了一个规则:每个代码都不能是其它代码的前缀。
哈夫曼编码
二叉树中有一种特别的树——哈夫曼树(最优二叉树),其通过某种规则(权值)来构造出一哈夫曼二叉树,在这个二叉树中,只有叶子节点才是有效的数据节点(很重要),其他的非叶子节点是为了构造出哈夫曼而引入的!
哈夫曼编码是一个通过哈夫曼树进行的一种编码,一般情况下,以字符:‘0’与‘1’表示。编码的实现过程很简单,只要实现哈夫曼树,通过遍历哈夫曼树,规定向左子树遍历一个节点编码为“0”,向右遍历一个节点编码为“1”,结束条件就是遍历到叶子节点!因为上面说过:哈夫曼树叶子节点才是有效数据节点!

我们用01表示S,用00表示空格后,就不能用01和11表示某个字符了,因为它们是其它字符的前缀。在看三位的组合,分别有000,001,010,100,101,110和111,A是010,I是110,为什么没有其它三位的组合了呢?因为已知是不能用01和11开始的组合了,那么就减少了四种选择,同时011用于U和换行符的开始,111用于E和Y的开始,这样就只剩下2个三位的组合了,同理可以理解为什么只有三个四位的代码可用。
所以对于消息:SUSIE SAYS IT IS EASY
哈夫曼编码为:100111110110111100100101110100011001100011010001111010101110
哈夫曼解码
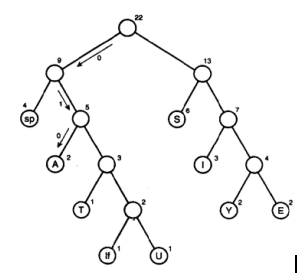
如果收到上面的一串哈夫曼编码,怎么解码呢?消息中出现的字符在哈夫曼树中是叶节点,也就是没有子节点,如下图:它们在消息中出现的频率越高,在树中的位置就越高,每个圆圈外面的数字就是频率,非叶节点外面的数字是它子节点数字的和。
每个字符都从根开始,如果遇到0,就向左走到下一个节点,如果遇到1,就向右。比如字符A是010,那么先向左,再向右,再向左,就找到了A,其它的依次类推。
总结
树是由边和节点构成,根节点是树最顶端的节点,它没有父节点;
二叉树中,最多有两个子节点;
某个节点的左子树每个节点都比该节点的关键字值小,右子树的每个节点都比该节点的关键字值大,那么这种树称为二叉搜索树,其查找、插入、删除的时间复杂度都为logN;
可以通过前序遍历、中序遍历、后序遍历来遍历树,前序是根节点-左子树-右子树,中序是左子树-根节点-右子树,后序是左子树-右子树-根节点;
删除一个节点只需要断开指向它的引用即可;
哈夫曼树是二叉树,用于数据压缩算法,最经常出现的字符编码位数最少,很少出现的字符编码位数多一些。
-—————————————————————————————————–
一致性Hash算法
一致性hash算法是分布式中一个常用且好用的分片算法、或者数据库分库分表算法。
现在的互联网服务架构中,为避免单点故障、提升处理效率、横向扩展等原因,分布式系统已经成为了居家旅行必备的部署模式,所以也产出了几种数据分片的方法:
1、取模,2.划段,3.一致性hash
前两种有很大的一个问题就是需要固定的节点数,即节点数不能变,不能某一个节点挂了或者实时增加一个节点,变了分片规则就需要改变,需要迁移的数据也多。
那么一致性hash是怎么解决这个问题的呢?
一致性hash:对节点和数据,都做一次hash运算,然后比较节点和数据的hash值,数据值和节点最相近的节点作为处理节点。为了分布得更均匀,通过使用虚拟节点的方式,每个节点计算出n个hash值,均匀地放在hash环上这样数据就能比较均匀地分布到每个节点。
1、原理
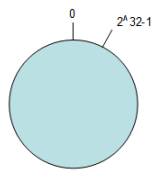
(1)环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。
现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图
(2)把数据通过一定的hash算法处理后映射到环上
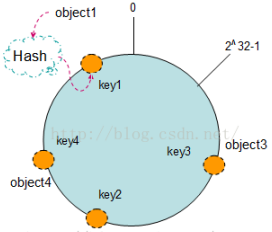
现在我们将object1、object2、object3、object4四个对象通过特定的Hash函数计算出对应的key值,然后散列到Hash环上。如下图:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
(3)将机器通过hash算法映射到环上
在采用一致性哈希算法的分布式集群中将新的机器加入,其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中
(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
假设现在有NODE1,NODE2,NODE3三台机器,通过Hash算法得到对应的KEY值,映射到环中,其示意图如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
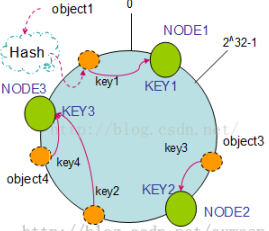
通过上图可以看出对象与机器处于同一哈希空间中,这样按顺时针转动object1存储到了NODE1中,object3存储到了NODE2中,object2、object4存储到了NODE3中。
在这样的部署环境中,hash环是不会变更的,因此,通过算出对象的hash值就能快速的定位到对应的机器中,这样就能找到对象真正的存储位置了。
2、机器的删除与添加
普通hash求余算法最为不妥的地方就是在有机器的添加或者删除之后会造成大量的对象存储位置失效。下面来分析一下一致性哈希算法是如何处理的。
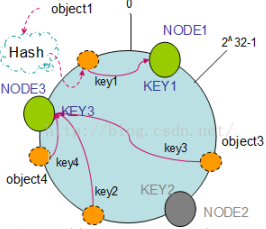
(1)节点(机器)的删除
以上面的分布为例,如果NODE2出现故障被删除了,那么按照顺时针迁移的方法,object3将会被迁移到NODE3中,这样仅仅是object3的映射位置发生了变化,其它的对象没有任何的改动。如下图:
(2)节点(机器)的添加
如果往集群中添加一个新的节点NODE4,通过对应的哈希算法得到KEY4,并映射到环中,如下图:
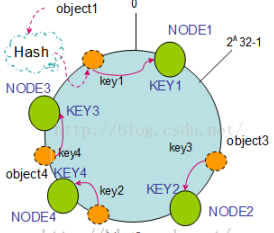
通过按顺时针迁移的规则,那么object2被迁移到了NODE4中,其它对象还保持着原有的存储位置。
通过对节点的添加和删除的分析,一致性哈希算法在保持了单调性的同时,还是数据的迁移达到了最小,这样的算法对分布式集群来说是非常合适的,避免了大量数据迁移,减小了服务器的的压力。
3、平衡性–虚拟节点
根据上面的图解分析,一致性哈希算法满足了单调性和负载均衡的特性以及一般hash算法的分散性,但这还并不能当做其被广泛应用的原由,
因为还缺少了平衡性。下面将分析一致性哈希算法是如何满足平衡性的。
hash算法是不保证平衡的,如上面只部署了NODE1和NODE3的情况(NODE2被删除的图),object1存储到了NODE1中,而object2、object3、object4都存储到了NODE3中,这样就造成了非常不平衡的状态。在一致性哈希算法中,为了尽可能的满足平衡性,其引入了虚拟节点。
——“虚拟节点”( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一个实际节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
以上面只部署了NODE1和NODE3的情况(NODE2被删除的图)为例,之前的对象在机器上的分布很不均衡,现在我们以2个副本(复制个数)为例,这样整个hash环中就存在了4个虚拟节点,最后对象映射的关系图如下:
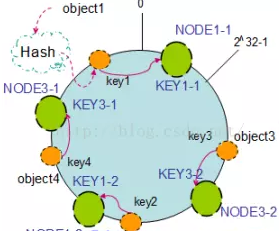
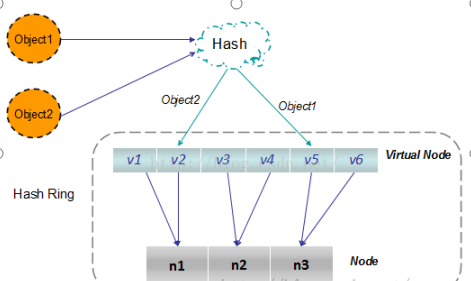
根据上图可知对象的映射关系:object1->NODE1-1,object2->NODE1-2,object3->NODE3-2,object4->NODE3-1。通过虚拟节点的引入,对象的分布就比较均衡了。那么在实际操作中,正真的对象查询是如何工作的呢?对象从hash到虚拟节点到实际节点的转换如下图:
“虚拟节点”的hash计算可以采用对应节点的IP地址加数字后缀的方式。例如假设NODE1的IP地址为192.168.1.100。引入“虚拟节点”前,计算 cache A 的 hash 值:
Hash(“192.168.1.100”);
引入“虚拟节点”后,计算“虚拟节”点NODE1-1和NODE1-2的hash值:
Hash(“192.168.1.100#1”); // NODE1-1
Hash(“192.168.1.100#2”); // NODE1-2
二、一致性hash算法的Java实现。
1、不带虚拟节点的
import java.util.SortedMap;
import java.util.TreeMap;
/**
* 不带虚拟节点的一致性Hash算法
*/
public class ConsistentHashingWithoutVirtualNode {
//待添加入Hash环的服务器列表
private static String[] servers = { "192.168.0.2:111", "192.168.0.3:111",
"192.168.0.4:111", "192.168.0.5:111", "192.168.0.6:111" };
//key表示服务器的hash值,value表示服务器
private static SortedMap<Integer, String> sortedMap = new TreeMap<Integer, String>();
//程序初始化,将所有的服务器放入sortedMap中
static {
for (int i=0; i<servers.length; i++) {
int hash = getHash(servers[i]);
System.out.println("[" + servers[i] + "]加入集合中, 其Hash值为" + hash);
sortedMap.put(hash, servers[i]);
}
}
//得到应当路由到的结点
private static String getServer(String key) {
//得到该key的hash值
int hash = getHash(key);
//得到大于该Hash值的所有Map
SortedMap<Integer, String> subMap = sortedMap.tailMap(hash);
if(subMap.isEmpty()){
//如果没有比该key的hash值大的,则从第一个node开始
Integer i = sortedMap.firstKey();
//返回对应的服务器
return sortedMap.get(i);
}else{
//第一个Key就是顺时针过去离node最近的那个结点
Integer i = subMap.firstKey();
//返回对应的服务器
return subMap.get(i);
}
}
//使用FNV1_32_HASH算法计算服务器的Hash值,这里不使用重写hashCode的方法,最终效果没区别
private static int getHash(String str) {
final int p = 16777619;
int hash = (int) 2166136261L;
for (int i = 0; i < str.length(); i++)
hash = (hash ^ str.charAt(i)) * p;
hash += hash << 13;
hash ^= hash >> 7;
hash += hash << 3;
hash ^= hash >> 17;
hash += hash << 5;
// 如果算出来的值为负数则取其绝对值
if (hash < 0)
hash = Math.abs(hash);
return hash;
}
public static void main(String[] args) {
String[] keys = {"太阳", "月亮", "星星","木星"};
for (int i = 0; i < keys.length; i++) {
System.out.println("[" + keys[i] + "]的hash值为" + getHash(keys[i])
+ ", 被路由到结点[" + getServer(keys[i]) + "]");
}
}
}