1、Kafka消息生产者
1)创建springboot-kafka-producer-demo项目,导入jar包。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.4.5.RELEASE</version>
</dependency>
2)在application.properties添加Kafka producer配置项
spring.kafka.bootstrap-servers=127.0.0.1:9092
spring.kafka.template.default-topic=topic-test
spring.kafka.listener.missing-topics-fatal=false
spring.kafka.listener.concurrency= 3
spring.kafka.producer.client-id=${spring.application.name}
# 写入失败时,重试次数。当leader节点失效,一个repli节点会替代成为leader节点,此时可能出现写入失败,
# 当retris为0时,produce不会重复。retirs重发,此时repli节点完全成为leader节点,不会产生消息丢失。
spring.kafka.producer.retries=0
# 每次批量发送消息的数量,produce积累到一定数据,一次发送
spring.kafka.producer.batch-size=16384
# produce积累数据一次发送,缓存大小达到buffer.memory就发送数据
spring.kafka.producer.buffer-memory=33554432
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
#request.required.acks有三个值 0 1 -1
#0:生产者不会等待broker的ack,这个延迟最低但是存储的保证最弱当server挂掉的时候就会丢数据
#1:服务端会等待ack值 leader副本确认接收到消息后发送ack但是如果leader挂掉后他不确保是否复制完成新leader也会导致数据丢失
#-1:同样在1的基础上 服务端会等所有的follower的副本受到数据后才会受到leader发出的ack,这样数据不会丢
spring.kafka.producer.acks=-1
3)Kafka消息生产者启动类中加入@EnableKafka注解
4)编写Kafka消息发送类-Kafka消息生产者
@Slf4j
@Component
public class KafkaSender {
@Autowired
private Globals globals;
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
/**
* 发送消息方法
* @param msg
*/
public ResponseEntity send(String msg) {
log.info("发送消息,消息内容 : {}", msg);
try {
String uuid = UUID.randomUUID().toString();
String topic = globals.getTopic();
Message message = new Message();
message.setId(uuid);
message.setMsg(msg);
message.setSendTime(new Date());
ListenableFuture listenableFuture = kafkaTemplate.send(topic, uuid, JSON.toJSONString(message));
//发送成功后回调
SuccessCallback<SendResult<String,String>> successCallback = new SuccessCallback<SendResult<String,String>>() {
@Override
public void onSuccess(SendResult<String,String> result) {
log.info("发送消息成功");
}
};
//发送失败回调
FailureCallback failureCallback = new FailureCallback() {
@Override
public void onFailure(Throwable ex) {
log.error("发送消息失败", ex);
}
};
listenableFuture.addCallback(successCallback,failureCallback);
}catch (Exception e){
log.error("发送消息异常", e);
}
return new ResponseEntity("", HttpStatus.OK);
}
}
5)发送消息测试类
public class MsgSenderTest extends KafkaProducerApplicationTest {
@Autowired
MsgSender sender;
@Test
public void send() {
sender.send("这是Kafka发送的消息内容" + System.currentTimeMillis());
}
}
2、Kafka消息消费者
1)创建springboot-kafka-consumer-demo项目,导入jar包。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.4.5.RELEASE</version>
</dependency>
2)在application.properties添加Kafka consumer配置项
#============== kafka ===================
# 指定kafka 代理地址,可以多个
spring.kafka.bootstrap-servers=127.0.0.1:9092
spring.kafka.template.default-topic=topic-test
spring.kafka.listener.missing-topics-fatal=false
spring.kafka.listener.concurrency=3
spring.cloud.bus.trace.enabled=true
#=============== consumer =======================
spring.kafka.consumer.client-id=${spring.application.name}
# 指定默认消费者group id --> 由于在kafka中,同一组中的consumer不会读取到同一个消息,依靠groud.id设置组名
spring.kafka.consumer.group-id=test
# smallest和largest才有效,如果smallest重新0开始读取,如果是largest从logfile的offset读取。一般情况下我们都是设置smalles
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.enable-auto-commit=false
# 如果'enable.auto.commit'为true,则消费者偏移自动提交给Kafka的频率(以毫秒为单位),默认值为5000。
spring.kafka.consumer.auto-commit-interval=100
spring.kafka.consumer.max-poll-records=10
# 指定消息key和消息体的编解码方式
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
3)Kafka消息消费者启动类中加入@EnableKafka注解
4)用@KafkaListener创建Kafka消息消费者类
@Component
public class KafkaBatchConsumer {
protected final Logger logger = LoggerFactory.getLogger(this.getClass());
@KafkaListener(topics = {"${spring.kafka.template.default-topic}"},
containerFactory = "kafkaListenerContainerFactory")
public void listen(List<ConsumerRecord> records, Acknowledgment ack) {
try {
for (ConsumerRecord record : records) {
logger.info("接收消息: offset = {}, key = {}, value = {} ",
record.offset(), record.key(), record.value());
}
} catch (Exception e) {
logger.error("kafka接收消息异常",e);
} finally {
//手动提交偏移量
ack.acknowledge();
}
}
}
3、测试Kafka
先启动Kafka消息消费者springboot-kafka-consumer-demo项目
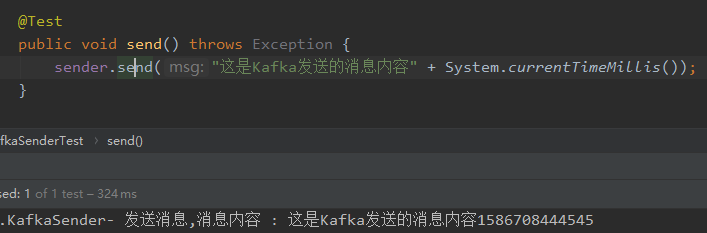
1)在Kafka消息生产者的MsgSenderTest类执行send()方法,如下图
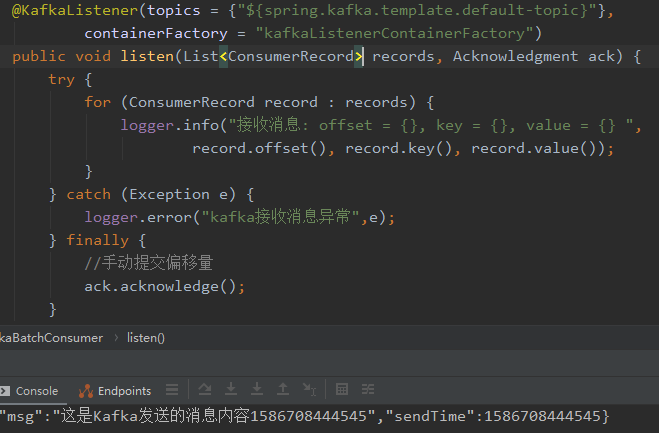
2)切换到Kafka消息消费者查看消费结果
源码示例:https://gitee.com/lion123/springboot-kafka-demo
4、一些问题
1)、kafka在高并发的情况下,如何避免消息丢失和消息重复?
消息丢失解决方案:
首先对kafka进行限速, 其次启用重试机制,重试间隔时间设置长一些,最后Kafka设置acks=all,即需要相应的所有处于ISR的分区都确认收到该消息后,才算发送成功
消息重复解决方案:
消息可以使用唯一id标识
生产者(ack=all 代表至少成功发送一次)
消费者 (offset手动提交,业务逻辑成功处理后,提交offset)
落表(主键或者唯一索引的方式,避免重复数据)
业务逻辑处理(选择唯一主键存储到Redis或者mongdb中,先查询是否存在,若存在则不处理;若不存在,先插入Redis或Mongdb,再进行业务逻辑处理)
2)、kafka怎么保证数据消费一次且仅消费一次
幂等producer:保证发送单个分区的消息只会发送一次,不会出现重复消息
事务(transaction):保证原子性地写入到多个分区,即写入到多个分区的消息要么全部成功,要么全部回滚流处理EOS:流处理本质上可看成是“读取-处理-写入”的管道。此EOS保证整个过程的操作是原子性。注意,这只适用于Kafka Streams
3)、kafka保证数据一致性和可靠性
数据一致性保证
一致性定义:若某条消息对client可见,那么即使Leader挂了,在新Leader上数据依然可以被读到
HW-HighWaterMark: client可以从Leader读到的最大msg offset,即对外可见的最大offset, HW=max(replica.offset)
对于Leader新收到的msg,client不能立刻消费,Leader会等待该消息被所有ISR中的replica同步后,更新HW,此时该消息才能被client消费,这样就保证了如果Leader fail,该消息仍然可以从新选举的Leader中获取。
对于来自内部Broker的读取请求,没有HW的限制。同时,Follower也会维护一份自己的HW,Folloer.HW = min(Leader.HW, Follower.offset)
数据可靠性保证
当Producer向Leader发送数据时,可以通过acks参数设置数据可靠性的级别
0: 不论写入是否成功,server不需要给Producer发送Response,如果发生异常,server会终止连接,触发Producer更新meta数据;
1: Leader写入成功后即发送Response,此种情况如果Leader fail,会丢失数据
-1: 等待所有ISR接收到消息后再给Producer发送Response,这是最强保证
4)、kafka到spark streaming怎么保证数据完整性,怎么保证数据不重复消费?
保证数据不丢失(at-least)
spark RDD内部机制可以保证数据at-least语义。
Receiver方式
开启WAL(预写日志),将从kafka中接受到的数据写入到日志文件中,所有数据从失败中可恢复。
Direct方式
依靠checkpoint机制来保证。
保证数据不重复(exactly-once)
要保证数据不重复,即Exactly once语义。
- 幂等操作:重复执行不会产生问题,不需要做额外的工作即可保证数据不重复。
- 业务代码添加事务操作
就是说针对每个partition的数据,产生一个uniqueId,只有这个partition的所有数据被完全消费,则算成功,否则算失效,要回滚。下次重复执行这个uniqueId时,如果已经被执行成功,则skip掉。
5)、你用的kafka是批量消费还是一条条消费?为什么这样用?
两种方式都有用到。
对用不重要的数据,如日志这些数据,使用的是批量;对用重要数据则不配置批量消费。
重要数据批量消费失败的话就要批量重新发送和消费。