
点击跳转到 Elastic Search 专栏目录
ElasticSearch 是一个用Java语言开发的分布式文档检索引擎。 也支持文档存储功能, 且不会将信息类似SQL存储为列数据, 而是存储已序列化的JSON文档的复杂数据结构。 而且ElasticSearch支持集群部署, 当集群中有多个ElasticSearch节点时, 存储的文档会分布在整个集群中, 并且可以从任何节点立即访问。
ElasticSearch是基于 Lucene 的搜索服务器, 并且提供了标准的 RESTful web接口, 作为 Apache 许可条款下的开放源码发布。
相关术语约定
- 分片:shard
- 主分片:primary shard
- 副分片:replica shard
- 分片副本:指数据中的一个分片,不区分主分片还是副分片
- 分片配置:shard allocation
- 集群状态:cluster state
- 分配决策:allocation decision
- 分配感知:allocation awareness
- 分配标识:allocation IDs
- 追踪:tracking
- 事物日志:translog
- 同步集合:in-sync set
理解ES元字段和概念
ElasticSearch 在存储数据的时候是以 JSON 序列化文档的方式存储, 所以再这样的文档中, 有很多标识性的字段, 叫:元字段, 例如在存储结构上用 _index、_type和_id来标识一个文档:
- _index: 指向一个或多个物理分片的逻辑命名空间
- _type:在同一集合中, 对数据的不同细分的元字段标识
- _id:唯一标识符
在初学者中, 会引用 RDBMS(Relational Database Management System 关系数据库管理系统) 来帮助对这些元字段的理解, 将 _index 理解为数据库, _type理解成为表, 但是在 ES 中, 你对 _type 进行删除操作的时候, 并不能对内存空间进行释放, 而该元字段存在也并没有什么实际意义, 因此在6.版本后仅存在一个 _type 字段, 在7.中将会直接删除。 因此我们在数据释放的时候应该是以 _index 作为删除单位。
集群状态描述
- Green:所有主分片和副分片皆运行正常
- Yellow:所有主分片都运行正常, 但并非所有的副分片都运行正常, 存在单点故障
- Red:存在主分片非正常运行
当然, 这种状态也存在于索引之间的状态描述, 假设某一索引下修饰了一个副分片, 那么该分片所属的索引以及整个集群都会变成 Yellow 状态, 其他的索引依旧是原来的状态。
分片关系
在 ES 中为了应对并发更新的问题上, ES 采用主从模式, 主分片的数据作为权威数据, 写入的过程优先写入主分片, 成功执行后再写入副分片, 在数据恢复阶段的时候亦是以主分片的数据为基准。
其中数据分片和数据副本的关系:
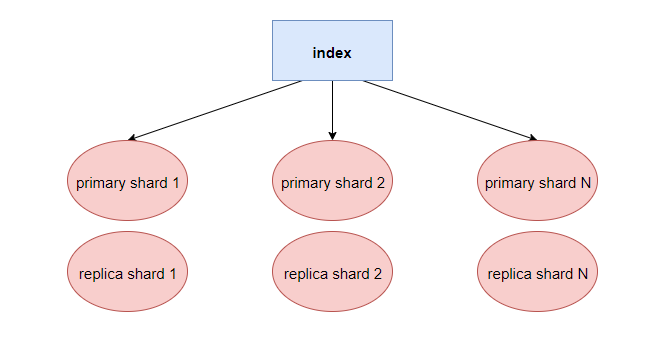
分片在 ES 中是底层中基本的读写单元, 其作用是为了将巨大的索引数据进行分割, 让读写操作可以并行执行, 因此索引和分片的包含关系如下:
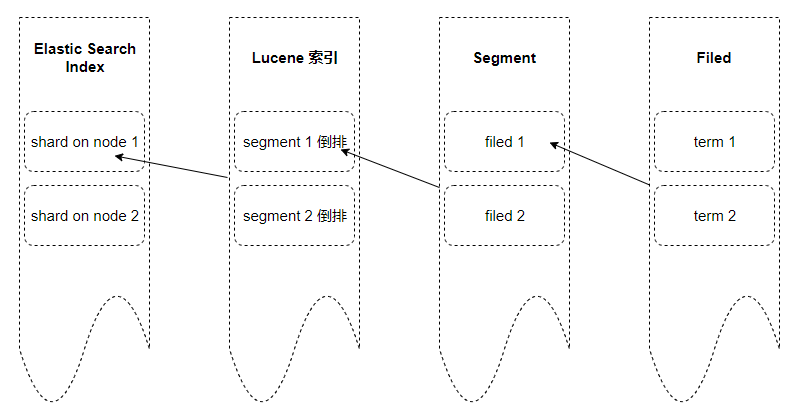 其中一个 ES 索引包含很多个分片, 一个分片就是一个 Lucene 索引, 一个 Lucene 索引包含很多个分段, 一个分段是由多个倒排索引组成, 一个倒排索引包含若干个文档数据, 一个文档数据由若干个词构成, 词是经过分词器处理和语言处理最后的结果。
其中一个 ES 索引包含很多个分片, 一个分片就是一个 Lucene 索引, 一个 Lucene 索引包含很多个分段, 一个分段是由多个倒排索引组成, 一个倒排索引包含若干个文档数据, 一个文档数据由若干个词构成, 词是经过分词器处理和语言处理最后的结果。
ES 的实时性
在 ES 中, 对于实时的概念, 其实是一个秒级同步数据的概念, 例如在你写入数据的时候立马查询(设定查询时间小于1秒), 你将查询不到该数据, 因为你写入 ES 中的数据将暂时性的存在一个缓存中, 在秒级单位内统一写入 ES 内存中, 所以在很多时候, 对数据写入后立即查询的时候, 存在数据写入失败的假象。
ES 分词器(Analyzer)
分词器的作用是:把文本内容的词按一定规则进行切割分离, 对应的是Analyzer 类, 这是一个抽象基类, 切分词的具体规则是由子类继承实现的, 所以对于不同的语言的条件下, 需要用不同的分词器。 在创建索引时和数据搜索时都会用到分词器, 并且使用的分词器需要统一, 否则将会出现数据检索为空的情况。
内置分词器:
| tokenizer | logical name | description |
|---|---|---|
| standard tokenizer | standard | – |
| edge ngram tokenizer | edgeNGram | – |
| keyword tokenizer | keyword | 不分词 |
| letter analyzer | letter | 按单词分 |
| lowercase analyzer | lowercase | letter tokenizer, lower case filter |
| ngram analyzers | nGram | – |
| whitespace analyzer | whitespace | 以空格为分隔符拆分 |
| pattern analyzer | pattern | 定义分隔符的正则表达式 |
| uax email url analyzer | uax_url_email | 不拆分url和email |
| path hierarchy analyzer | path_hierarchy | 处理类似path/to/somthing样式的字符串 |
在这些内置的分词器意外还有其他的, 例如IK分词器, 这个分词器对于中文分词有很好的效果, 很多使用者对官方的分词器实现中文分词的时候效果并不理想, 但是IK就解决了这个问题。
有可用环境的时候将使用实操截屏的方式展示 ES 的相关特性, 以及相关操作。