相信很多人都碰到过需要用正则匹配字符串的时候,遇到了又不会写,上网一通乱搜,也看不明白那些鬼画符是个什么意思,就当黑箱调来改去的经历。
但其实如果只是想看懂简单正则表达式的话,并没有那么困难。符号虽多,但仍有线索可寻。它的内容可以大致划分为字符组、量词、分组和断言四部分
这四个部分的表示方法都和这三个括号(),[],{}息息相关,简单的对应关系如下:
- 字符组 []
- 量词 {}
- 分组 & 断言 ()
接下来就让我们以括号为线索了解正则表达式吧
(为了方便, 文中示例使用JavaScript, 可以直接粘贴到浏览器控制台查看效果)
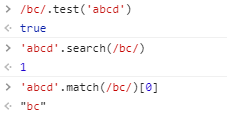
/bc/.test('abcd') //输出true 判断字符串'abcd'是否匹配表达式 'abc' /字符串/是js表示正则的语法
'abcd'.search(/bc/) //输出1 搜索首次匹配的位置
'abcd'.match(/bc/)[0] //输出 获取匹配到的字符串
一. 字符组 []
首先,在没有特殊符号的情况下,正则只是简单的匹配字符是否相等 比如 /b/.test('abc')匹配字符串中的b字符
但是往往我们会需要在一个位置上匹配一类字符,这在正则中被称为字符组,使用 中括号[] 表示
例如,需要查找字符串中是否存在数字的话,可以写作'a1'.search(/[0123456789]/) //输出1 意思是字符串’a1’中的下标为1的字符可以由表达式/[0123456789]/匹配
但这样也有个问题,表示英文字母得把26个字母挨个敲一遍,太长了; 不过放心,正则提供了一些简写的方式
1. 字符组的简写
1.1 范围表示法
范围表示法就是以[x-y]的形式表示x到y范围的字符,按照ASCII的顺序来 这样,[0123456789]就可以写作[0-9],小写字母也就可以表示为[a-z]
1.2 字符组简记法
使用[0-9],[a-z]已经可以很方便的表示数字和小写字母了,但仍然有更简单的表示,也就是简记法
比如 表示数字的 [0-9] 可以写成 \d,d表示数字(digit); 虽然\d这种写法并没有中括号,但它们是等价的;
下面是一些常用的简记法和其等价的字符组的对应关系
| 简记法 | 等价字符组 | 说明 |
|---|---|---|
| \d | [0-9] | 数字 digit |
| \D | [^0-9] | 非数字 |
| \s | [ \t\r\n\v\f] | 空白字符 |
| \S | [^ \t\r\n\v\f] | 非空白字符 |
| \w | [0-9a-zA-Z_] | 单词字符(字母数字下划线,包括中文) |
| \W | [^0-9a-zA-Z_] | 非单词字符 |
2. 排除和转义
2.1 排除型字符组
上面的表里一二行出现了一个奇怪的现象,[0-9]只是加了个^,怎么就从数字变成非数字了呢?不应该表示的是十个数字加上一个^这11个字符吗?
这个^符号在字符组里表示 取反 ,可以很方便的表示指定字符之外的字符集合这一概念,比如[^0-9]可以用来形容所有非数字字符
但是这样的话 十个数字加上一个^这11个字符 又该怎么表示呢?
其实,^只有紧跟在左中括号后面时,才表示取反的意思,如果改成[0-9^],那么它的意思就只是简单的匹配 十个数字或者^字符了
2.2 转义字符
让取反符号^变成普通字符并不只有更改位置这一种方式,还可以通过转义字符来实现
说到转义,首先不得不提到一个概念: 元字符 ; 这些字符不同于普通字符,它们在正则表达式中有折特殊的含义,例如 字符组[^0-9]里面的^ 和 -,还有外层的中括号本身等;
如果就是想要匹配这些元字符本身,而不是它们所表达的特殊含义的话,可以在它们前面加上反斜杠\,来恢复它们的本来面目.
到这里你也应该发现了,\也是元字符,需要用\\来表示它本身
下面是一些常见的元字符
| 元字符 | 作用 | 说明 |
|---|---|---|
| – | 范围表示法 [0-9]表示[0123456789],按照ASCII编码顺序 |
只在字符组内有效 |
| ^ | 排除型字符组 例: [^0-9]匹配除数字外的其他字符 |
只有紧跟在[后才是元字符[12^]匹配的是’1′ ,’2’,’^’这三个普通字符 |
| \ | 转义字符 | 匹配字符\本身需要\\ |
| () | 分组 | |
| [] | 字符组 | |
| {} | 量词 |
二. 量词 {}
上面所描述的都是匹配单个字符,如果需要匹配多个,比如YYYY-MM-DD这种格式的日期,只用\d的话是这样的\d\d\d\d-\d\d-\d\d,很啰嗦;
正则中这种匹配多个字符的方式叫做量词,写作{n,m} ,比如4个数字是\d{4} 整个日期可以写成\d{4}-\d{2}-\d{2}
量词的一般形式为{m,n},用于限定{}前面的元素出现的次数,n和m分别为出现次数的上下限(闭区间)
| 量词 | 说明 |
|---|---|
| {n} | 必须出现n次 |
| {m,n} | 出现m到n次 |
| {m,} | 至少出现m次,无上限 |
| * | 次数无上下限 , 等价于{0,} |
| + | 至少一次,等价于{1,} |
| ? | 0次或1次,等价于 {0,1} |
贪婪和非贪婪模式
看到上面的表,你有没有疑惑: 如果+意思是匹配 1到无穷次, 那么如果有很多的字符都可以匹配的话,它是按多的来还是少的来呢?
具体来说, 用\d+匹配一段数字,是匹配全部还是只选第一个?
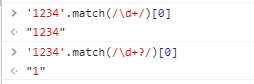
这里可以在控制台里尝试一下 '1234'.match(/\d+/)[0] ,会发现它匹配上了全部的1234,所以说量词默认是 贪婪 的,即尽量多的匹配能匹配上的字符
那么相对应的就有非贪婪模式(匹配尽量少的字符), 它的写法是在量词后面加上?
'1234'.match(/\d+/)[0] // 1234
'1234'.match(/\d+?/)[0] // 1
- 可以简单的理解为
- 贪婪模式下这个量词匹配尽量多的字符
- 非贪婪模式匹配尽量少的字符
有意思的是?本身也是一种量词,两个?连起来表示: 以非贪婪模式匹配前面的元素0或1次,考虑到要匹配尽量少的字符,那就是压根不匹配
'ab'.match(/ab?/)[0] // ?等价于量词 {0,1} , 字符b可以匹配也可以不匹配, 因为是贪婪模式,那就匹配上了
'ab'.match(/ab??/)[0] // 第一个?是量词 ,第二个? 表示非贪婪模式
