Stream
在Java 8之前,若要实现这样一个功能:在一个List<String>中找到匹配”Scala”的字符串。则可能需要写一个循环分支,且内部再调嵌套一个if分支判断每一个字符串是否equals.("Scala")。
换一个场景,如果我们是要在MySQL数据库中的某table内寻找一个值为”Scala”的字符串,只需要提供类似一个这样的SQL语句即可实现查找功能。
select str from list where str='Scala'
Stream使得Java从命令式编程摆脱出来,向声明式编程过渡:省略大量的循环,判断分支,只通过”声明”的方式告诉系统,我只需要得到满足什么条件的结果,而不去关注其具体的实现过程。
对于一个Stream流,我们可以用层层工序去加工流过的数据,即在进行终止操作之前可以插入大量的中间操作筛选出想要得到的结果。
Stream流更倾向于描述处理数据的过程,而不去存储数据本身。存储的工作由Collection负责。

刚才提到的这两种操作,稍微再介绍它们。我们首先尝试着在Java中创建一个流出来:
创建一个Stream流
简单来讲,我们可以从数组,集合中获取数据流,也可以使用Stream类提供的方法创建一个流出来。
1、 通过集合来创建。
List<String> strings = new LinkedList<>();
Stream<String> stringStream = strings.stream(); //串行流,最常用。
Stream<String> stringStreamParallel = strings.parallelstream(); //并行流。
2、 对于数组,可以使用Arrays提供的stream(arr)方法来获取流。
Integer[] Ints = {1, 2, 3};
//引用类型数组E[] 会转换成Stream<E>。
Stream<Integer> Intstream = Arrays.stream(Ints);
int[] ints = {4, 5, 6};
//int[], double[], long[]数组 会转换成XXXStream。
IntStream intStream = Arrays.stream(ints);
3、 由Stream.of(E... e)直接生成:
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5);
通过Stream类创建一个无限流
无限流可以通过迭代方式(iterate), 生成方式(generate)两种方式构建出来。
迭代方式
Stream可以提供按一定规律排列的,元素个数无穷的流。相当于无穷数列。
比如等差数列的规律是:第n个元素与第n-1个元素的差为常数a (a∈R)。这个规律在Java中被描述为了一个Lambda表达式:t -> t+a。即传入第n个元素t,那么第(n+1)个元素的值为t+a。
Stream根据这个表达式来生成一个等差数列。现在尝试用Stream.iterate方法生成一个偶数列:
Stream<Integer> num = Stream.iterate(0,t -> t+2);
如果只需要前10个元素,则使用limit方法截断这个流:
Stream<Integer> num = Stream.iterate(0,t -> t+2).limit(10);
该方法的第二个参数是
UnaryOperator<T>接口。它是Function<T,R>接口的一个特例:传入类型T和返回类型R是同一个类型,即T=R。它描述了一个这样的函数:输入T类型参数,经过 f(T) 变换后,得到的仍然是T类型返回值。
生成方式
提供一个SupplierStream<E>。泛型E取决于Supplier提供的是何种元素。
提示:无参构造器也可以认为是Supplier。
Stream<Employee> workers = Stream.generate(Employee :: new).limit(10);
Stream是延迟操作的
延迟操作,即懒加载。单例模式的懒汉式加载就是一个懒加载的例子。有关延迟操作的部分在之后的Scalalazy关键字学习再详细介绍。
我们首先创建出一个Stream流:
Stream<Integer> num = Stream.iterate(0,t -> t+2);
其实在里用创建来形容并不准确,因为这一条语句仅仅是对创建一个Integer流的一个声明。num此刻并没有被加载出来。
为什么这个流只有声明,却没有加载?究其原因,就是因为到目前为止,程序都没有使用到这个流所提供的数据。这是由于Stream的延迟操作特性决定的。
举个生活中的延迟操作例子:我们只有在用水时才会拧开水龙头,水才会流出来。在其它时候我们会拧紧水龙头,不让水被白白地浪费掉。
*Spark 的 RDD 也沿用了懒加载的思想来避免了计算大量且无用的数据,导致浪费系统资源。
Stream的两种关键操作
我们刚才提到了两个方法:中间操作,和终止操作。
中间操作,相当于是对处理流数据过程的描述。通过一个中间操作,可以将一个数据流转换成另一个数据流。可是仅有这些描述,并不意味着我们就一定会使用到流提供的数据。
终止操作,相当于我们真正把数据流的“水龙头”拧开,通过声明实际的数据操作来告诉程序:我现在要用到这个流提供的数据,因此你现在必须要加载它了。
举个例子:程序现在希望能通过一个数据流打印出偶数数列,为了能顺利执行这条命令,它必须要加载这个数据流以获取到能打印在屏幕上的数据。
Stream.iterate(0,t -> t+2).limit(10).foreach(System.out::println)
中间操作
中间操作包含了过滤,映射,排序等方法。经过中间操作可以将上一个流的数据传递给下一个流。其中,flatMap比较抽象一些,因此在文章的最后,详细地介绍这一方法。
//一般从方法名就可以推断出这个方法的功能,因此这里只以表格形式列出来常用的中间操作。
过滤操作
| 方法 | 参数类型 | 功能 |
|---|---|---|
| filter | Predicate<E> | 使用规定的表达式筛选元素,只保留判断为true的元素,并返回筛选后的数据流。 |
| limit | Integer | 从这个流当中截取前Integer个元素,并返回截取后的新数据流。 |
| skip | Integer | 从流的第一个元素开始跳过Integer的元素。若该数值超过了流的元素个数,则返回空流。 |
| distinct | 无 | 相当于SQL语句中的去重操作。根据元素的HashCode()和equal()方法来判断是否重复。 |
映射操作
| 方法 | 参数类型 | 功能 |
|---|---|---|
| map | Function<T,R> | 将原流内的每个T类型元素传进去,经过变换后,返回一个R类型元素,最后返回的是R类型的数据流。 |
| flatMap | Function<T,Stream<R>> | 将原流内的每一个T类型元素传进去,经过变换后,返回一个Stream<R>类型元素,最后,将多条Stream<R>流合并为一个统一的Stream<R>。 |
排序操作
| 方法 | 参数类型 | 功能 |
|---|---|---|
| sorted | 无 | 按照自然顺序对流内的所有元素进行排序,并返回一个新的流。默认按照Comparable<R>的比较方法。 |
| sorted | Comparator<T> | 按照Comparator所规定的比较方法来进行排序,并返回排序后的流。 |
终止操作
一条贯通的流(流和流之间用中间操作衔接)在某处进行了终止操作,则程序认为这一整条Stream流已经操作完毕,随即所有的流将被关闭。
如图所示:一条连贯的数据流,在Stream3处执行了终止操作,即意味数据流到此截止了。之后Stream1,2,3被关闭,因此如果再在Stream1之后接入一个数据流Stream4,会在运行时会抛出IllegalStateException异常。(该异常不是受检异常,因此在编译期间不会报错,但是运行时则会抛出异常。)
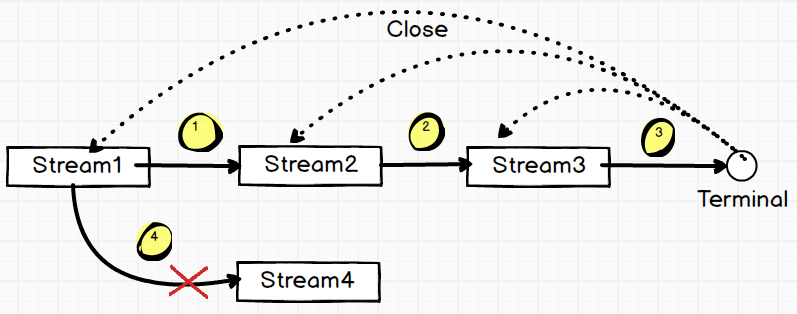
以forEach这个终止操作为例子,它的参数是一个Consumer<T>类型的函数式接口。设计者认为我们已经在终止操作中把数据消费掉了,那么之前所有的Stream流便可以全部关闭。
下面的操作均属于终止操作。
匹配与查找
| 方法 | 功能 |
|---|---|
| allMatch(Predicate<T> p) | 检查这个流内是否所有的元素都满足某个条件,并最终返回一个boolean值。 |
| anyMatch(Predicate<T> p) | 检查是否至少有1个元素满足某个条件,没有allMatch方法严格。 |
| noneMatch(Predicate<T> p) | 相当于allMatch方法的取反操作。 |
| count() | 统计流内的元素个数,返回一个long类型的值。 |
| findAny() | 随机返回流当中的某个元素。对于串行流,总返回第一个元素。而对于并行流,则会随机返回一个元素 |
| max(Comparator<T> c) | 返回经比较器比较后最大的元素。 |
| min(Comparator<T> c) | 返回经比较器比较后最小的元素。 |
| forEach(Comsumer<T> c) | 常用的内部迭代,使用consumer<T>自定义如何消费流内的每一个元素。 |
规约
| 方法 | 功能 |
|---|---|
| Reduce(T identify, BinaryOperator<T>) | 给定初始值identify,然后按照BinaryOperator格式对流内所有的元素进行两两归并。最后得到的结果是Optional<T>。 |
| Reduce(BinaryOperator<T>) | 没有初始值的聚合操作。 |
BinaryOperatior是拓展的函数式接口,它代表一个二元操作:输入两个T类型的参数,归并成一个T的参数。
收集
由于Stream本身不负责存储数据(且它是延迟计算,没有action就不进行计算),所以若要用集合将Stream内部的数据收集起来,就需要用到与收集相关的方法。
开发者认为,收集操作也属于终止操作。
collect方法往往和Collectors.toXXX方法搭配使用,这样就可以直接得到一个收集了E元素的XXX集合了。
常用的toXXX方法有toList,toSet和toCollection。返回的数据类型对应List<E>,Set<E>,Collection<E>集合。
collect方法还涉及到了Collectors和Collector的使用,在后续的文章中给出更详细的说明。
List<Integer> collect =
Stream.iterate(0, t -> t +2).limit(10).collect(Collectors.toList());
补充:Stream的flatMap方法
我们用一个word count的实例来介绍flatMap,以下代码块均为伪代码。
假设存在一个函数:foo1 = Function<String,Stream<String>>。它实现的功能是:输入一个String类型的长句子,(比如:“hello world”),foo1会将这个句子按照空格符拆分成多个单词,将多个单词再装入到一个Stream
假如现在有一个集合存放着两个句子:
List<String> sentences =List{“Hello World”,”Hello scala”}
由于每个句子都会被foo1拆分为一个流,因此到现在为止我们会得到一个”二维”的字符串流。
stream2D = Stream{Stream{“hello”,”world”},Stream{“hello”,”scala”}}
如果我们使用的是map操作,则映射就到此为止了。如果再要获取具体的每个单词,则不得不进行嵌套的forEach操作来提取每一个单词。
flatMap相当于是在此基础上又进行了一步flat操作,即先map(映射)后flat(压平)。flatMap会将stream2D内的每个子Stream再次拆解,将内部的所有单词取出来,归并成一个整体的流。
stream1D = Stream{“hello”,”world”,”hello”,”scala”}
此时再要提取每个单词,则只进行一次forEach操作即可。
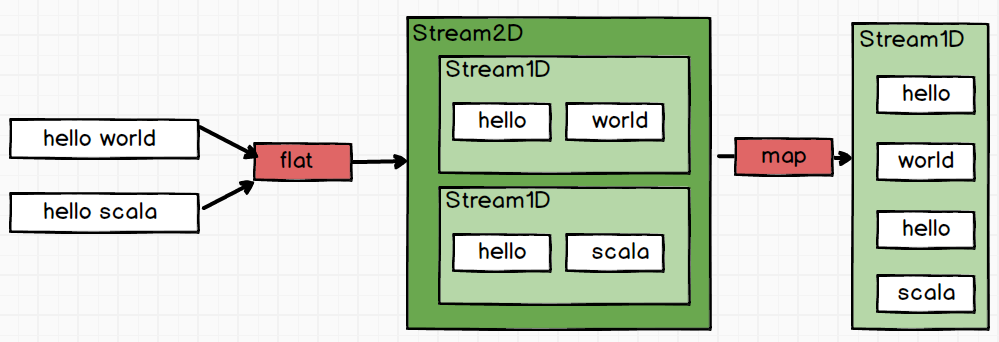
这也对为什么flatMap的第二个参数是Stream<R>类型做出了解释:只有”高维”的Stream,flatMap的flat操作才显得有意义。
flatMap只会拆箱一次。如果这个Stream是n维的,则它返回的是n-1维Stream,而不是1维Stream。
Java源码中,对flatMap方法的声明:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);