Arrays & Collections
Java 8 提供了对数组和集合的便捷操作工具:Arrays , Collections。这些工具所提供的都属于静态方法,因此不需要创建它们的实例就可以调用其功能。
注意甄别:Collection是集合类的顶级接口,包括了List,与Set等集合。
Collections是工具类。包括了对集合的种种操作。
Arrays
整理了Arrays所提供的常用方法,若要了解全部方法,请参考java.util.Arrays源代码。
| 方法名 | 返回值 | 功能 |
|---|---|---|
| sort(t[] arr) | 无 | t 指代short, int, long等基本类数据类型,而非泛型。对传进来的数组默认按升序排序。 |
| sort(T[] arr) | 无 | 对引用类型数组按升序排序。需要类型T实现了Comparable<T>接口。 |
| sort(T[] arr, Comparator<T> com ) | 无 | 使用Comparator<T>的比较方法对其进行排序。 |
| binarySerach(T[] ts,T t) | int | 二分法方式在ts数组内检索元素t是否存在。存在则返回0,否则返回-1。T指代引用类型,也可引申为基本数据类型。 |
| fill(T[], T t) | 无 | 将ts引用的数组内部的所有元素全部替换为t。该方法一般用于初始化数组。 |
| copyOf(T[] ts,int length) | T[] | 从头开始复制ts[]并生成一个新长度的同类型数组。可以拷贝长度,多余位置补充0,或者null。这里的T为引用类型,也可引申为基本数据类型。 |
| asList(T[] ts) | ArrayList<T> | 将数组T[]类型转化为ArrayList<T>输出。 |
| asList(T… t) | ArrayList<T> | 上述方法的不定参数形式。 |
关于asList方法
1、 (至少在Java 8版本)不建议将该方法用在基本数据类型数组上。
2、 asList方法返回的ArrayList
3、 asList方法返回的ArrayList
原因:asList所返回的ArrayList是Arrays定义的内部类!该ArrayList直接继承自AbstractList,而AbstarctList内的remove和add方法会直接抛出异常:UnsupportedOperationException
Arrays内部的ArrayList和传进来的数组通过建立引用来绑定在一起。因此当数组发生变化时,ArrayList会随之发生变化。此ArrayList”像模像样”地提供继承自List接口的ArrayList的大部分同名功能,但它们并不属于同一个类。
这个问题经常困扰初学者:凭什么asList获取的ArrayList就不能add和remove?因为此ArrayList非彼ArrayList。
在文末给出了asList的源代码部分, 参见附录。
Collections
整理了Collections所提供的常用方法,若要了解全部方法,请参考java.util.Collections源代码。
| 方法名 | 返回值 | 功能 |
|---|---|---|
| sort(List<T> list) | 无 | 对list进行默认排序,要求类型T实现了Comparable<T>。 |
| sort(List<T> list,Comparator<T> com) | 无 | 如果T没有默认实现Comparable<T>接口,则还需要传入一个Comparator<T>来辅助排序。 |
| shuffle(List<T> list ) | 无 | 对list进行随机排序。 |
| binarySerach(List<T> list,T key) | int | 二分法方式在列表内检索元素t是否存在。存在则返回0,否则返回-1。 |
| fill(List<T> list, T t) | 无 | 将list列表内部的所有元素全部替换为t。该方法一般用于初始化列表。 |
| addAll(Collection<T> c, E… e) | 无 | 向Collection(List,Set)内放入后面的元素。 |
| swap(int i, int j) | 无 | 交换索引i,j位置的元素。 |
| copy(List<T> dest, List<T> target ) | 无 | 从头元素开始逐步将target内的每一个元素覆盖到dest上。 |
需要回顾一下Comparator和Comparable
在需要进行排序,或者进行比较比较的场合中,经常需要这两个接口。简单概括这两个接口的差异性:
- Comparable
在类定义时实现。需要重写compareTo(T t)方法来自定义比较规则。 - Comparator
在外部程序定义某个类型T的比较方法,需要重写compare(T t1, T t2)方法来自定义比较规则。Comparator 接口还提供了一些便捷的静态comparing, compareXXX方法。
举个例子:现在有一个学生类Student,内部有一个属性age。希望分别用这两个接口,来定义这样的比较方法:age越大的学生,则在逻辑上认为它更”大”。
Comparable
class Student implements Comparable<Student>{
private short age;
//省略get方法
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
外部的comparator
//Lambda表达式重写compare方法。
Comparator<Student> studentComparator1 = (s1,s2)->s1.getAge()-s2.getAge();
Comparator<Student> studentComparator3 = Comparator.comparingInt(s -> s.getAge());
//使用方法引用实现,要求传入的参数是可以比较的。如果比较的对象是非String,包装类以外的引用类型,则该引用类型也要实现Comparable<T>接口。
Comparator<Student> studentComparator2 = Comparator.comparing(Student::getAge);
Collector & Collectors
在上一章讲到了Stream流的几个终止操作:匹配与查找,规约,收集。在该部分对收集操作的细节做补充。
首先从Stream当中获取一个Stream流:
Stream<Integer> limit = Stream.iterate(0, integer -> integer + 2).limit(4);
当进行收集操作时,我们要调用collect方法。内部的参数需要传入Collector类,来告诉程序,如何去收集这些数据。
我们上周仅介绍了collect(Collectors.toXXX)可以将数据流转化为想要的XXX集合类型。实际上这个collector方法的参数是一个Collector。那它的内部构造是什么样呢?
Collector
Collector定义了可变的汇聚操作。Collector的三个泛型分别代指:
- T:聚合的元素类型
- A:中间结果的容器类型
- R:最终生成的结果类型
为什么会存在一个中间结果的容器呢?这是为了支持多线程环境下对每个并行流并行“归并”操作,最终汇聚成一个R类型的容器返回(也就是说Collector支持对并行流,串行流进行操作)。从它内部定义的5个核心接口分析:
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
//在对并行流进行合并时会使用此方法
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
}
从方法名,返回值类型和泛型我们能推测出Collector的基本运行原理:
Supplier方法用于记录一个提供者:创建一个中间结果的容器类型。accumulator方法用于记录一个函数:将Stream的元素装入中间容器A当中。 combiner方法记录一个函数:在处理并行流时,将多个中间结果的A类型容器进行归并。串行流不使用此方法。fininsher记录一个函数:将收集(或称归并)完毕的A集合最终以R类型集合返回。
那charateristics()方法是用于做什么的?它用来为Collector设定特征值。Characteristics是Collector接口内部定义的枚举类型,具有三个特征值:
- CONCURRENT: 表示最后只会返回一个结果容器。只用在处理并行流,且当收集器不具备该特征,
combiner()才会被执行。当然,在串行流来说,结果容器总是一个。 - UNORDERED:流中的元素无序
- IDENTITY_FINISH:中间结果容器类型与最终结果类型一致。即T==R。该情况下
finisher()方法不会被调用。
下面给出串行流中,Collector的收集方式:
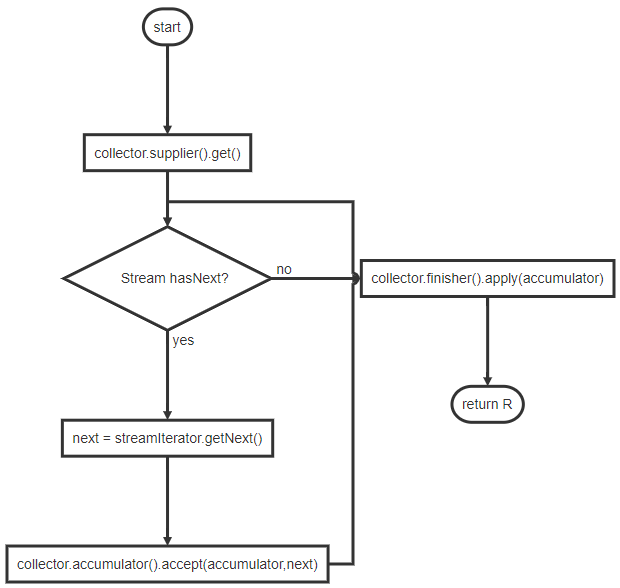
Collector对并行流的操作过程,可以类比归并算法。
在了解了Collector的基本工作流程之后,尝试着自定义一个MyCollector:
class MyCollector implements Collector<String,LinkedList<String>,LinkedList<String>>{
@Override
public Supplier<LinkedList<String>> supplier() {
return LinkedList::new;
}
@Override
public BiConsumer<LinkedList<String>, String> accumulator() {
System.out.println("Function BiConsumer is working!");
//方法引用之对象类型引用:第二个类型String是第一个类型的某个实例方法的参数。
return LinkedList<String>::add;
}
@Override
public BinaryOperator<LinkedList<String>> combiner() {
return (list1, list2) ->{
list1.addAll(list2);
return list1;
};
}
@Override
public Function<LinkedList<String>, LinkedList<String>> finisher() {
System.out.println("由于特征值被设定为IDENTITY_FINISH,所以该方法不会被调用。");
return null;
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH));
}
}
尝试着在主函数中使用它:
List<String> strings = new LinkedList<>();
Collections.addAll(strings,"Hello","Scala","Java","Kotlin");
LinkedList<String> collect = strings.stream().collect(new MyCollector());
collect.forEach(System.out::println);
Collector.of方法支持从外部传入四个函数接口的方式来生成一个特定功能的Collector。
public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,
BiConsumer<R, T> accumulator,
BinaryOperator<R> combiner,
Characteristics... characteristics) {
Objects.requireNonNull(supplier);
Objects.requireNonNull(accumulator);
Objects.requireNonNull(combiner);
Objects.requireNonNull(characteristics);
Set<Characteristics> cs = (characteristics.length == 0)
? Collectors.CH_ID
: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH,
characteristics));
return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);
}
stream.collect方法正是按照Collector定义的四个action来执行收集操作。但显然,自己定义一个Collector要麻烦一些,因此有必要去介绍一个更有效的工具类。
Collectors
Collectors也是相当于Arrays, Collections的工具,它提供各类用于缩减操作的Collector。toXXX方法其实都是Collectors接口所定义的静态方法:根据需要提供不同种类型的Collector,而后collect方法根据Collector对流数据进行收集。
Collectors有多种方法来提供满足不同需要的Collector。
下面列出Collectors的常用方法。注意,这些罗列的方法返回值是Collector类型!,经过collect方法处理之后才返回最后被规约的数据类型。所以Collectors提供的方法都与collect组合使用。
篇幅限制,这里只给出常用的方法,预览全部功能,请查阅Collectors源码。在本文的最后,给出了这些常用方法的简单使用案例。
求值操作:
| 方法 | 功能 |
|---|---|
| averagingInt(ToIntFunction<? super T> mapper) | 求平均值,还有对应输出Double,Long的求均值方法。 |
| counting() | 统计流内元素的个数 |
| maxBy(Comparator<? super T> comparator) | 统计元素中的逻辑最大者,需要传入Comparator。 |
| minBy(Comparator<? super T> comparator) | 统计元素中的逻辑最小者,需要传入Comparator。 |
| summingInt(ToIntFunction<? super T > mapper) | 求和。还有对应输出Double, Long的求平均值方法。 |
| summarizingInt(ToIntFunction<? super T > mapper) | 求综合的统计结果,包含了最值,平均值,求和等数据。返回值为IntSummaryStatistics。还有对应Double,Long的方法。 |
分组:
| 方法 | 功能 |
|---|---|
| <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<? super T, ? extends K> classifier) | 给定分组的标准Key,并按照Key相同的元素的元素放入到一个List当中,最后返回Map<Key,List>形式。 |
字符串拼接:
注意,这里要求传入的是Stream
| 方法 | 功能 |
|---|---|
| joining() | 直接拼接流内的String元素。 |
| joining(CharSequence delimiter) | 拼接时插入delimiter声明的分割符 |
| joining(CharSequence delimiter,CharSequence prefix, CharSequence suffix) | 拼接时,额外的增加前缀和后缀。 |
规约操作:
Collectors也提供规约操作,但是一般不需要它,因为Stream本身就提供reduce操作。
| 方法 | 功能 |
|---|---|
| reducing(BinaryOperator<T> op) | 按照BinaryOpeartor的方式对元素进行规约操作。 |
| reducing(T identity, BinaryOperator<T> op) | 提供一个初始值identity。 |
Optional类
Java程序员最经常碰到异常的就是空指针异常。Optional就是为了解决这个麻烦而诞生的。 和Collection集合类的作用类似,它也是一个容器。Optiona
创建一个Optional类对象
| 方法 | 功能 |
|---|---|
| Optional.of(T t) | 创建一个非空T类型对象的Optional实例。 |
| Optional.ofNullable(T t) | 创建一个允许为空的T类型对象的Optional实例。 |
| Optional.empty() | 创建一个空的Optianal实例。 |
判断Optional容器中是否包含对象
| 方法 | 功能 |
|---|---|
| IsPresent() | 判断是否包含对象。 |
| IfPresent(Consumer con) | 判断是否包含对象,且若包含,则将该对象发送给Consumer消费。 |
安全地获取Optional容器的对象
| 方法 | 功能 |
|---|---|
| Get() | 如果返回的对象非空,则返回,否则则抛出异常。 |
| orElse(T other) | 如果非空,则执行get()。如果为空,则返回参数的other对象来防止空指针。 |
| orElseGet(Supplier other) | 如果非空,则执行get()。如果为空,则用Supplier提供的对象。该对象extends T泛型类型。 |
引入了Optional类,通过T t3 = Optional.ofNullable(T t1).orElse(T t2)来建立了一个保障机制,至少会返回一个默认的引用来规避空指针异常。
再来谈谈Stream
从底层一窥Stream的真面目
Stream作为Java8 最亮眼的特性之一,它的内部构造要复杂得多:我们常用的Stream是BaseStream衍生出来的众多子接口的其中一个,其它的还有IntStream,LongStream,DoubleStream。(Java 8 的设计者很偏爱这三个包装类,对Integer,Long,Double类型的数据都单独做了封装。)
既然Stream接口只是提供了数据流传递的方法。那每一段数据流真正的载体是谁呢?
每一段数据流,其实指数据流的每一个阶段Stage(下文有提及),记录着进来的数据是何种类型,做何种操作,流出去的数据又是何种类型,而非存储数据本身。Stream不存储对象的信息。
真正的载体是AbstractPipeLine<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>抽象类,翻译过来就是抽象的数据管道。如果该流内装载的是引用类型,则可以向下细化为ReferencePipeLine,如果是Integer,Long,Double这三种包装类型,则可以细化为IntPipeLine,LongPipeLine和DoulePipeLine。下文中为了方便叙述,将这四种PipeLine统称为XXXPipeLine。
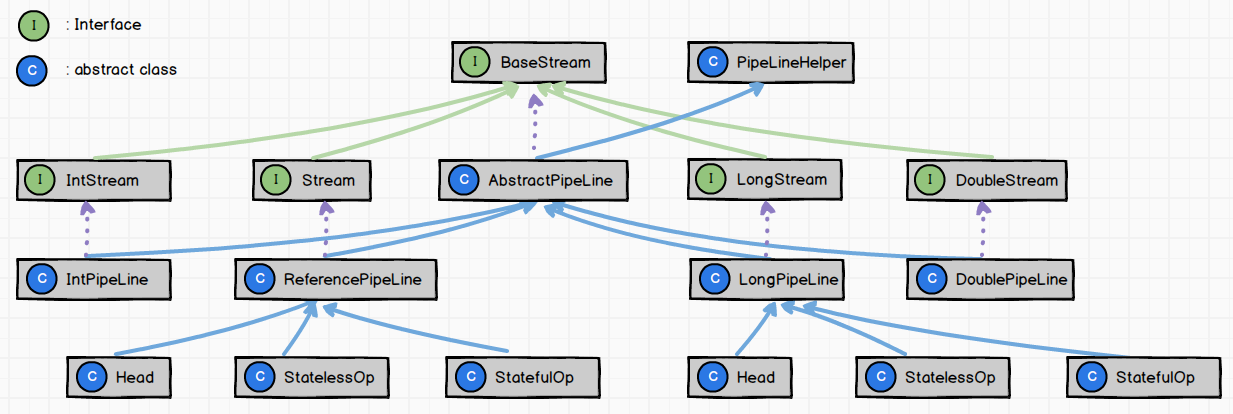
Stream的灵魂是AbstractPipeLine
一条连贯的Stream流是如何构建的呢?AbstractPipeLine抽象类定义了三个成员:
/**
* Backlink to the head of the pipeline chain (self if this is the source stage).
*/
private final AbstractPipeline sourceStage;
/**
* The "upstream" pipeline, or null if this is the source stage.
*/
private final AbstractPipeline previousStage;
/**
* The next stage in the pipeline, or null if this is the last stage.
* Effectively final at the point of linking to the next pipeline.
*/
private AbstractPipeline nextStage;
我们便可以得知:流和流之间以双向链表的节点形式组织了起来。sourceStage记录了流的起点,previousStage记录了上一个流,nextStage同理。
无论哪种XXXPipeLine,都定义了继承XXXPipeLine本身的内部静态类StatefulOp, StatelessOp, Head。即根据功能的不同对每个XXXPipeLine下层又进行了详细划分。
Head,顾名思义,就是这个链表的第一个节点,它通过XXXPipeLine构造器进行初始化参数。
Java中的抽象类可以定义构造器,当抽象类的子类被初始化时,则可以用抽象类的构造器来对内部的属性进行初始化,但不能用于构造抽象类本身。
StatelessOp & StatefulOp
我们在上一篇文章中介绍了:Stream存在两种操作方式:第一种:终止操作。第二种:中间操作。从底层的角度来看,终止操作归于TerminalOp接口。
终止操作还可分为短路操作和非短路操作,短路操作是指不用处理全部元素就可以返回结果,比如找到第一个满足条件的元素。
而中间操作,又衍生出两个分支:有状态操作(statefulOp)和无状态操作(statelessOp)。
- 无状态操作,指元素的处理不受前一个元素的影响。比如
filter方法:每个元素独立进行判断来决定该元素是否会留下。 - 有状态操作,指元素的处理受前一个元素的影响。比如sorted方法:每个元素的位置取决于它在该流内的相对大小。
因此,涉及到有状态操作的PipeLine,则实际上它被细化为了StatefulOp;涉及到无状态操作的PipeLine则被细化为了StatelessOp。
在这里附上表格:
| Stream操作 | 具体操作 |
|---|---|
| 无状态(StatelessOp) | unordered(),filter(),map(),mapToInt(),mapToLong(),mapToDouble(),flatMap(),flatMapToInt(),flatMapToLong(),flatMapToDouble(),peek() |
| 有状态(StatefulOp) | distinct(),sorted(),limit(),skip() |
| 最终操作(TerminalOp) | forEach(),forEachOrdered(),toArray(),reduce(),collect(),max(),min(),count(),anyMatch(),allMatch(),noneMatch(),findFirst(),findAny() |
Stream使用Stage的概念来描述每一段流
每个PipeLine(代指各种XXXXOp)具备三个元素:数据源,操作,回调函数,分别对应着三个步骤:拿什么做,做什么,具体怎么做。
stream.filter(t -> t > 4 );
上述代码块,数据源是stream流入的数据,操作是filter,回调函数则是传入的Lambda表达式。这一个完整的操作过程,Java 8 的设计者称之为一个Stage。
那多个Stream通过中间操作相连接的过程,就是将具有先后顺序的stage连成了一条流水线,直到有一个Stage执行了TerminalOp。每一个Stage都保留着从AbstractPipeLine继承到的sourceStage,该引用指向Head。
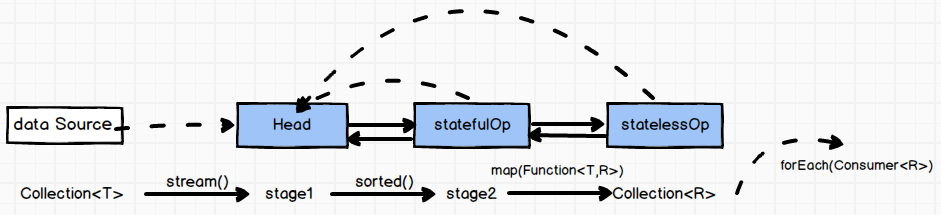
Sink维护整条流水线
每一个Stage只知道自己执行的是哪个操作。换句话说,它不知道流水线中前一个的Stage的具体操作,也不知道后一个Stage的具体操作,此时就应该有一个组件,来协调相邻Stage之间的调用,这就是Sink接口存在的意义。(注:Sink的汉译为“水槽”,细细品)
在创建每一个Stage时,都会包含一个opWrapSink方法,该方法把操作的具体实现(回调函数)封装在Sink类。
当一个Stage执行了终止操作,从这个Stage开始按照PipeLine的链接顺序不断调用前面的中间操作,同时,递归产生一个Sink链,记录整条流水线具体的每一个具体操作(回调函数)。
附录:Collectors的简单案例
首先声明一个简单的学生类,省略了部分代码。
class Student implements Comparable<Student> {
private int age;
private String name;
//省略了Get & Set方法,请自行补齐。
//省略了Student(age,name)构造器方法,请自行补齐。
//省略了toString方法,请自行补齐。
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
summarizing案例
Double[] a = {2.0, 3.0, 3.0, 5.1, 6.3};
DoubleSummaryStatistics collect2 = Arrays.stream(a).collect(Collectors.summarizingDouble(Double::doubleValue));
joining案例
//这里有个小bug:IDE提倡使用方法引用,这么写会抛出一个恼人的Warning。
//但是Double类有重载的toString方法,因此如果替换成了方法引用则又会报错:
//no compile-time declaration for the method reference is found
Double[] a = {2.0, 3.0, 3.0, 5.1, 6.3};
Arrays.stream(a).map(aDouble -> aDouble.toString()).collect(Collectors.joining(","));
groupingBy案例
List<Student> students = new LinkedList<>();
Collections.addAll(students,new Student(10,"LiYang"),new Student(10,"DingYi"),new Student(13,"ZhangYang"));
Map<Integer, List<Student>> collect2 = students.stream().collect(Collectors.groupingBy(Student::getAge));
collect2.get(10).forEach(System.out::println);
System.out.println("-----------------------");
collect2.get(13).forEach(System.out::println);
reduceing案例
//假设我们对学生进行这样的规约操作:将所有的学生聚合为一个单独的学生对象:
//这个学生对象的age,是有所学生的age之和。
//这个学生对象的name,将所有学生的名字拼接了起来。
BinaryOperator<Student> sbo = (s1,s2)->new Student(s1.getAge() + s2.getAge(), s1.getName()+"-"+s2.getName());
List<Student> students = new LinkedList<>();
Collections.addAll(students, new Student(10, "LiYang"), new Student(10, "DingYi"), new Student(13, "ZhangYang"));
//直接使用reduce方法效果也是一样的。
Optional<Student> collect = students.stream().collect(Collectors.reducing(sbo));
Student result = collect.orElse(new Student(-1, "Error"));
System.out.println(result.toString());
附录:Arrays类的asList方法和ArrayList内部类
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
/**
* @serial include
*/
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{
private static final long serialVersionUID = -2764017481108945198L;
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
@Override
public int size() {
return a.length;
}
@Override
public Object[] toArray() {
return a.clone();
}
@Override
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
int size = size();
if (a.length < size)
return Arrays.copyOf(this.a, size,
(Class<? extends T[]>) a.getClass());
System.arraycopy(this.a, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
@Override
public E get(int index) {
return a[index];
}
@Override
public E set(int index, E element) {
E oldValue = a[index];
a[index] = element;
return oldValue;
}
@Override
public int indexOf(Object o) {
E[] a = this.a;
if (o == null) {
for (int i = 0; i < a.length; i++)
if (a[i] == null)
return i;
} else {
for (int i = 0; i < a.length; i++)
if (o.equals(a[i]))
return i;
}
return -1;
}
@Override
public boolean contains(Object o) {
return indexOf(o) != -1;
}
@Override
public Spliterator<E> spliterator() {
return Spliterators.spliterator(a, Spliterator.ORDERED);
}
@Override
public void forEach(Consumer<? super E> action) {
Objects.requireNonNull(action);
for (E e : a) {
action.accept(e);
}
}
@Override
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
E[] a = this.a;
for (int i = 0; i < a.length; i++) {
a[i] = operator.apply(a[i]);
}
}
@Override
public void sort(Comparator<? super E> c) {
Arrays.sort(a, c);
}
}